Нагрузочное тестирование API NodeJS с помощью Autocannon

Как разработчики, мы всегда заботимся о времени отклика API, чтобы оно не могло стать узким местом для потребителей. Поэтому нам необходимо гарантировать, что время отклика не повлияет на производительность приложения, даже если несколько пользователей используют его одновременно.

Тесты всегда являются неотъемлемой частью приложения, обеспечивающей его бесперебойную работу. Как мы можем протестировать наши API, которые будут поддерживать одновременные запросы пользователей? — Autocannon, пакет нагрузочного тестирования, может имитировать высокий трафик в нашем приложении.
Autocannon
Autocannon — это инструмент для сравнительного анализа HTTP/1.1, написанный на NodeJS и широко используемый для измерения производительности приложения. С помощью autocannon мы можем моделировать несколько запросов в секунду для нагрузочного тестирования нашего приложения.
Кстати, cannon переводится как пушка, орудие (не путать с компанией Canon, а вот звучат слова одинаково), ну а autocannon - автопушка соответственно.
Установка
Установите autocannon глобально.
1npm install -g autocannonКоманда тестирования
1autocannon [opts] URL
2Доступные опции
Больше опций вы можете найти здесь.
1-c | --connections: Устанавливает количество одновременных соединений к серверу. Это основной параметр для моделирования нагрузки, поскольку он определяет, сколько клиентов будет одновременно подключено к серверу во время теста.
2
3-p | --pipeline: Определяет количество HTTP-запросов, которые будут отправлены в одном соединении без ожидания ответа на предыдущий запрос, имитируя HTTP/1.1 pipelining. Этот параметр позволяет увеличить интенсивность нагрузки и эффективность тестирования за счет уменьшения задержек, связанных с латентностью сети.
4
5-d | --duration: Задает продолжительность теста в секундах. Этот параметр определяет, насколько долго будет выполняться нагрузочный тест.
6
7-w | --workers: Устанавливает количество работников (worker threads), используемых для выполнения теста. Работники выполняются в отдельных потоках и могут помочь улучшить производительность тестирования на многоядерных системах.
8
9-m | --method: Позволяет указать HTTP-метод, который будет использоваться при отправке запросов. По умолчанию используется метод GET, но с помощью этого параметра можно выбрать любой другой метод, например POST, PUT, DELETE и так далее.
10
11-t | --timeout: Устанавливает таймаут в миллисекундах для HTTP-запросов. Если сервер не отвечает в течение указанного времени, запрос будет считаться неудачным. Этот параметр помогает определить, как долго клиент готов ждать ответа от сервера перед тем, как отметить запрос как неудачный.
12
13-j | --json: Выводит результаты теста в формате JSON. Это полезно для анализа результатов программно или для их интеграции с другими инструментами.
14
15-f | --forever: Заставляет autocannon выполнять тесты бесконечно или до тех пор, пока тест не будет прерван вручную. Этот режим полезен для долгосрочного тестирования стабильности и выявления утечек памяти или других проблем, которые могут проявиться только при длительной нагрузке.Практика - Командная строка
Выполните следующую команду в терминале:
1autocannon -с 100 -d 5 -p 10 https://google.comЕсли при запуске команды вы встретите ошибку запрета на запуск отключенных в системе сценариев (только Windows), установите политику выполнения следующим образом:
1Set-ExecutionPolicy -Scope CurrentUser -ExecutionPolicy Unrestricted
2Данная команда используется в PowerShell для изменения политики выполнения скриптов для текущего пользователя. Параметр -ExecutionPolicy Unrestricted указывает, что можно запускать любые скрипты, включая скрипты, скачанные из Интернета, что может представлять потенциальную угрозу безопасности, если скрипты не являются доверенными. Параметр -Scope CurrentUser означает, что изменения политики выполнения будут применяться только к текущему пользователю, не влияя на других пользователей системы или на глобальную политику выполнения скриптов в системе.
Вы должны увидеть примерно сдедущий отчет:
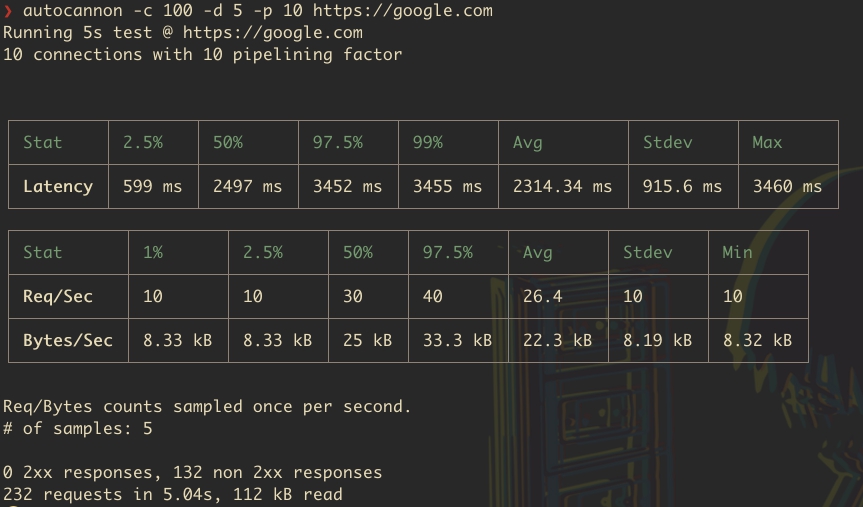
- autocannon: Это команда для запуска `autocannon`, начинающая тест производительности.
- -c 100: Этот параметр указывает количество одновременных подключений к серверу. В данном случае `-c 100` означает, что `autocannon` будет поддерживать 100 одновременных подключений к целевому серверу во время теста.
- -d 5: Задает длительность теста в секундах. -d 5 означает, что нагрузочный тест будет продолжаться 5 секунд.
- -p 10: Устанавливает период ожидания в миллисекундах между запросами для каждого подключения. В данном случае `-p 10` означает, что будет 10 миллисекунд паузы между запросами, сделанными одним подключением. Это помогает немного разгрузить сервер, делая тест более реалистичным по сравнению с беспрерывной отправкой запросов.
- https://google.com: Целевой URL, к которому `autocannon` будет направлять запросы. В данном случае тестируется производительность веб-сервера Google.
В совокупности, эта команда запускает нагрузочный тест, который в течение 5 секунд будет поддерживать 100 одновременных подключений к `https://google.com`, делая паузу в 10 мс между запросами каждого подключения. Это позволяет оценить, как сервер справляется с высокой нагрузкой, и измерить его производительность и способность обрабатывать множество одновременных запросов.
Autocannon, по завершению теста выводит две таблицы данных:
1. Request Latency (Задержка запроса)
2. Request Volume (Объем запроса)
Давайте рассмотрим их подробнее.
Request Latency (Задержка запросов)
Эта таблица показывает время отклика вашего API. Здесь приводятся различные метрики, которые описывают, как быстро сервер отвечает на запросы. Обычно здесь указываются:
Min: Минимальное время отклика за время теста.
Max: Максимальное время отклика за время теста.
Median: Медианное время отклика. Это означает, что половина запросов была обработана быстрее данного времени, а другая половина - медленнее.
Average: Среднее время отклика.
Percentiles: Процентили показывают время отклика в определенном проценте запросов. Например, 95-й процентиль означает, что 95% запросов были обработаны за это время или быстрее.
Давайте разберем на конкретном примере:
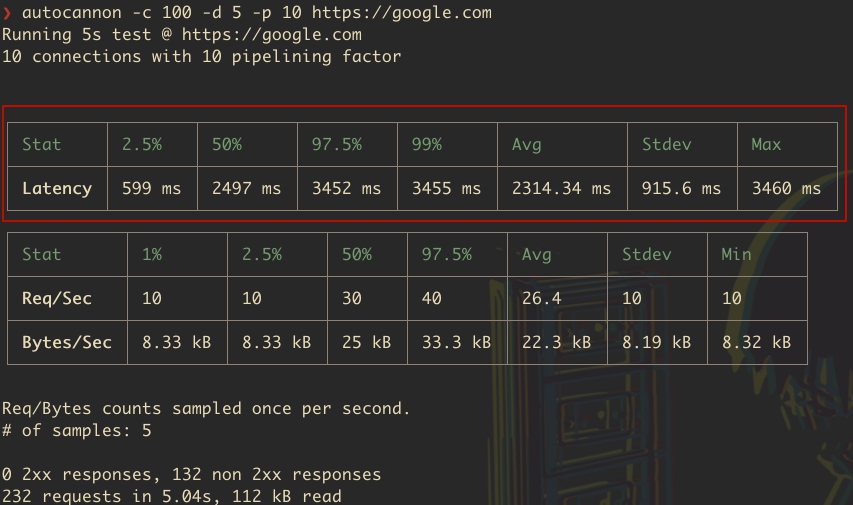
- Stat: Это заголовок колонки, указывающий на то, что в строках ниже будут представлены статистические данные по задержкам.
- 2.5%: Значение задержки в 66 мс означает, что 2.5% запросов имели задержку 66 мс или меньше. Это показывает минимальную задержку, с которой сталкивалось очень маленькое число запросов.
- 50% (Медиана): Значение в 77 мс указывает, что половина всех запросов была выполнена с задержкой 77 мс или меньше. Это наиболее типичное значение задержки для вашего API.
- 97.5%: 169 мс означает, что 97.5% запросов имели задержку 169 мс или меньше. Это дает представление о верхнем пределе задержек для большинства запросов.
- 99%: 1396 мс показывает, что 99% запросов обрабатывались с задержкой 1396 мс или меньше. Это значение говорит о том, что лишь 1% запросов испытывал задержки, превышающие данное значение, что может указывать на наличие некоторых очень медленных запросов.
- Avg (Average / Среднее): Средняя задержка составила 110.63 мс. Это значение рассчитывается путем деления суммы всех задержек на количество запросов и дает общее представление о том, с какой задержкой обрабатываются запросы в среднем.
- Stdev (Standard deviation / Стандартное отклонение): Стандартное отклонение задержки равно 194.86 мс. Это показывает, насколько разнообразными были задержки запросов. Большое стандартное отклонение указывает на то, что время отклика API сильно варьировалось.
- Max (Максимум): Максимальная зафиксированная задержка составила 1450 мс. Это значение показывает максимальное время отклика, которое было зафиксировано во время теста.
Итак, эти данные демонстрируют, что большинство запросов обрабатывалось довольно быстро (до 169 мс для 97.5% запросов), но существовали исключения, когда время отклика значительно возрастало (до 1396 мс для 1% запросов и максимум 1450 мс). Это может указывать на потенциальные проблемы с производительностью или стабильностью для определенных типов запросов или в определенных условиях.
Request Volume (Объем запросов)
Таблица Request Volume показывает статистику по количеству запросов в секунду (Req/Sec) и объему переданных данных в секунду (Bytes/Sec) в ходе тестирования API. Давайте подробно разберем значения:
Давайте так же рассмотрим на примере:
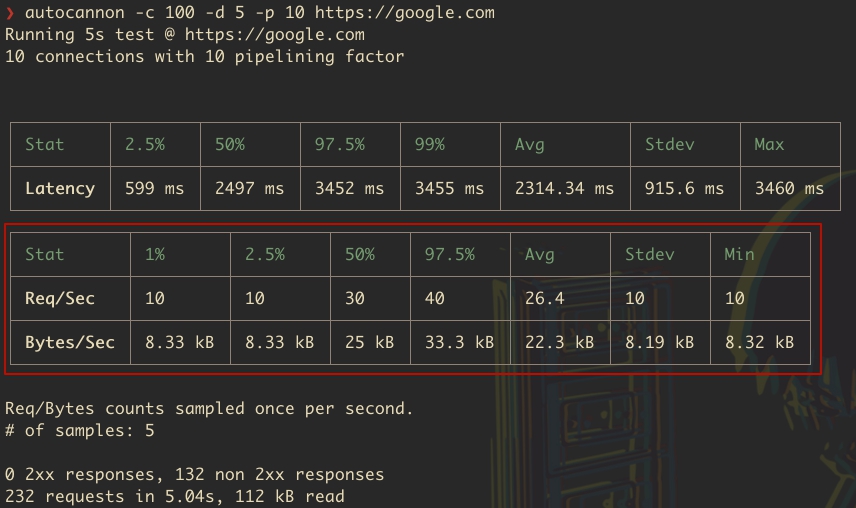
Req/Sec (Запросы в секунду)
1%: Минимальное количество запросов в секунду, которое система смогла обработать, составляет 10. Это означает, что даже в худших условиях производительности, 1% результатов был не ниже 10 запросов в секунду.
2.5%: Также 10 запросов в секунду, указывая на то, что хотя бы 2.5% времени система обрабатывала не менее 10 запросов в секунду.
50% (Медиана): В половине случаев система обрабатывала 30 запросов в секунду, что является наиболее типичным показателем производительности системы во время теста.
97.5%: В 97.5% случаев система обрабатывала не более 40 запросов в секунду, что указывает на верхний предел производительности системы под нагрузкой.
Avg (Среднее): В среднем, система обрабатывала 26.4 запроса в секунду.
Stdev (Стандартное отклонение): Стандартное отклонение равно 10, что говорит о вариативности количества обрабатываемых запросов в секунду во время теста.
Min (Минимум): Минимальное количество запросов в секунду в ходе всего теста составило 10.
Bytes/Sec (Байты в секунду)
1%: Минимальный объем данных, переданных в секунду, составляет 8.33 кБ. Это означает, что в худших 1% случаев объем переданных данных не опускался ниже этого значения.
2.5%: Такой же объем данных, как и для 1%, указывает на минимальный уровень производительности системы в плане передачи данных.
50% (Медиана): В половине случаев система передавала 25 кБ данных в секунду.
97.5%: В 97.5% случаев объем переданных данных не превышал 33.3 кБ в секунду.
Avg (Среднее): В среднем, система передавала 22.3 кБ данных в секунду.
Stdev (Стандартное отклонение): Стандартное отклонение равно 8.19 кБ, что указывает на вариативность объема переданных данных в секунду.
Min (Минимум): Минимальный объем данных, переданный в секунду во время всего теста, составил 8.32 кБ.
Данные из этой таблицы дают понимание о производительности и пропускной способности вашего API, показывая, как система справляется с нагрузкой как в плане количества обрабатываемых запросов, так и в плане объема передаваемых данных.
Заключение по таблицам
Обе таблицы важны для оценки производительности и надежности вашего API. Задержка запросов показывает, насколько быстро API отвечает на запросы, что критически важно для пользовательского опыта. Объем запросов дает представление о том, как ваш API справляется с нагрузкой, насколько он устойчив и способен обрабатывать большое количество запросов без сбоев.
Завершающая часть отчета
Завершающая часть отчета `autocannon`, которую мы видим на изображении, содержит важную информацию о результатах тестирования.
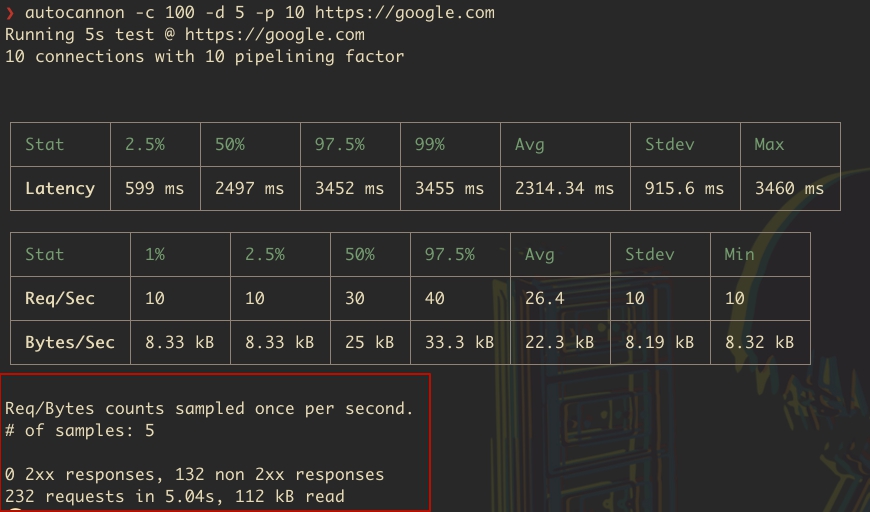
Давайте разберем отчет подробно:
- Req/Bytes counts sampled once per second: Это означает, что количество запросов и объем переданных данных измерялись один раз в секунду в течение всего теста.
- # of samples: 5: Указывает на количество измерений (или выборок), сделанных во время теста. Поскольку тест длился 5 секунд, было сделано 5 измерений. Это соответствует периодичности измерений в одну секунду.
- 0 2xx responses: Показывает количество успешных HTTP-ответов, полученных во время теста. Коды состояния 2xx означают успешную обработку запроса сервером. В данном случае успешных ответов не было.
- 132 non 2xx responses: Указывает на количество ответов, которые не относятся к категории успешных (то есть все, кроме 2xx). Это могут быть ответы с кодами 3xx (перенаправления), 4xx (ошибки клиента) и 5xx (ошибки сервера). В вашем тесте было получено 132 таких ответа.
- 232 requests in 5.04s: Общее количество выполненных запросов за время теста, которое составило 5.04 секунды, было 232. Это дает представление о нагрузке, которую тестирование создавало на сервер.
- 112 kB read: Объем данных, прочитанных в ходе теста, составил 112 килобайт. Это включает в себя данные всех полученных ответов, включая тела ответов и заголовки.
Эта часть отчета дает общее представление о производительности и поведении сервера во время теста. Отсутствие успешных ответов (2xx) может указывать на проблемы с доступностью или конфигурацией сервера во время тестирования. Полученные неуспешные ответы (non 2xx responses) требуют дополнительного анализа для выяснения причин: это могут быть временные или постоянные ошибки сервера, проблемы с маршрутизацией запросов или другие технические неполадки.
Практика - Программно
Autocannon можно использовать не только как инструмент командной строки, но и программно в вашем коде на Node.js. Это позволяет интегрировать нагрузочное тестирование напрямую в ваши приложения или тестовые сценарии, обеспечивая большую гибкость и возможность автоматизации.
Программный запуск autocannon дает возможность динамически конфигурировать параметры тестирования, обрабатывать результаты испытаний на лету и интегрировать нагрузочное тестирование в более широкие процессы CI/CD (Continuous Integration/Continuous Deployment).
Вот базовый пример использования autocannon программно:
1const autocannon = require('autocannon');
2const { promisify } = require('util');
3
4// Превращаем autocannon в Promise для использования с async/await
5const autocannonPromise = promisify(autocannon);
6
7async function runBenchmark() {
8 try {
9 const result = await autocannonPromise({
10 url: 'https://google.com',
11 connections: 10, // количество одновременных соединений
12 duration: 5, // продолжительность теста в секундах
13 // другие параметры по желанию
14 });
15
16 console.log('Результат тестирования:', result);
17 // Обработка результатов тестирования
18 } catch (err) {
19 console.error('Ошибка при выполнении нагрузочного тестирования:', err);
20 }
21}
22
23runBenchmark();
24В этом примере мы используем `autocannon` для программного запуска нагрузочного теста, указывая URL для тестирования, количество одновременных соединений и продолжительность теста. После завершения теста результаты выводятся в консоль. Вот мой результат этого теста:
1Результат тестирования: {
2 title: undefined,
3 url: 'https://google.com',
4 socketPath: undefined,
5 connections: 10,
6 sampleInt: 1000,
7 pipelining: 1,
8 workers: undefined,
9 duration: 5.04,
10 samples: 5,
11 start: 2024-02-13T20:04:56.464Z,
12 finish: 2024-02-13T20:05:01.500Z,
13 errors: 0,
14 timeouts: 0,
15 mismatches: 0,
16 non2xx: 110,
17 resets: 0,
18 '1xx': 0,
19 '2xx': 0,
20 '3xx': 110,
21 '4xx': 0,
22 '5xx': 0,
23 statusCodeStats: { '301': { count: 110 } },
24 latency: {
25 average: 426.13,
26 mean: 426.13,
27 stddev: 63.82,
28 min: 376,
29 max: 604,
30 p0_001: 376,
31 p0_01: 376,
32 p0_1: 376,
33 p1: 377,
34 p2_5: 377,
35 p10: 380,
36 p25: 381,
37 p50: 402,
38 p75: 453,
39 p90: 484,
40 p97_5: 603,
41 p99: 603,
42 p99_9: 604,
43 p99_99: 604,
44 p99_999: 604,
45 totalCount: 110
46 },
47 requests: {
48 average: 22,
49 mean: 22,
50 stddev: 4,
51 min: 20,
52 max: 30,
53 total: 110,
54 p0_001: 20,
55 p0_01: 20,
56 p0_1: 20,
57 p1: 20,
58 p2_5: 20,
59 p10: 20,
60 p25: 20,
61 p50: 20,
62 p75: 20,
63 p90: 30,
64 p97_5: 30,
65 p99: 30,
66 p99_9: 30,
67 p99_99: 30,
68 p99_999: 30,
69 sent: 120
70 },
71 throughput: {
72 average: 18312,
73 mean: 18312,
74 stddev: 3328,
75 min: 16640,
76 max: 24960,
77 total: 91520,
78 p0_001: 16655,
79 p0_01: 16655,
80 p0_1: 16655,
81 p1: 16655,
82 p2_5: 16655,
83 p10: 16655,
84 p25: 16655,
85 p50: 16655,
86 p75: 16655,
87 p90: 24975,
88 p97_5: 24975,
89 p99: 24975,
90 p99_9: 24975,
91 p99_99: 24975,
92 p99_999: 24975
93 }
94}Давайте разберем этот отчет.
Разбор программного отчета
1. Общие параметры теста:
- Было использовано 10 одновременных соединений.
- Продолжительность теста составила около 5.04 секунды.
- Всего было сделано 5 измерений (раз в секунду).
- Тест начался в 20:04:56 и завершился в 20:05:01 по UTC 13 февраля 2024 года.
2. Результаты по HTTP-ответам:
- Все 110 полученных ответов были с кодом 3xx (перенаправления), что указывает на то, что все запросы были перенаправлены. Конкретно, все ответы были с кодом 301 (Permanent Redirect).
- Не было зафиксировано ни одного успешного ответа с кодом 2xx, что связано с тем, что google.com, вероятно, выполняет перенаправление на версию сайта с HTTPS или на локализованную версию.
- Ошибок, таймаутов, несоответствий и сбросов соединений не было.
3. Статистика задержек:
- Средняя задержка составила 426.13 мс с минимальной задержкой в 376 мс и максимальной в 604 мс. Это показывает временные рамки отклика сервера на запросы.
- Стандартное отклонение задержек составило 63.82 мс, что указывает на относительную стабильность времени отклика во время теста.
4. Статистика запросов:
- В среднем обрабатывалось 22 запроса в секунду с минимумом в 20 и максимумом в 30 запросов. Всего было выполнено 110 запросов.
- Стандартное отклонение по количеству запросов в секунду составило 4, что также подтверждает относительную стабильность производительности во время тестирования.
5. Статистика пропускной способности:
- Средняя пропускная способность составила 18312 байт в секунду (приблизительно 17.9 кБ/с) с минимумом в 16640 байт и максимумом в 24960 байт. Общий объем переданных данных составил 91520 байт (приблизительно 89.4 кБ).
- Стандартное отклонение пропускной способности было 3328 байт, что говорит о некотором разнообразии в объемах передаваемых данных между различными интервалами измерения.
Эти результаты показывают, как сервер обрабатывал запросы во время нагрузочного теста, включая информацию о задержках, количестве и типах ответов, а также пропускной способности. Отсутствие ответов 2xx и наличие только ответов 301 указывает на то, что для тестирования потребуется учитывать перенаправления, особенно при работе с веб-сайтами, которые используют HTTPS или имеют специфические правила для перенаправления запросов.
Заключение по программному запуску нагрузки
Этот метод позволяет интегрировать нагрузочное тестирование в автоматизированные тестовые сценарии и процессы разработки, предоставляя возможность детально анализировать производительность приложений и сервисов.
Workers
Параметр workers используется для указания количества воркеров (рабочих потоков), которые будут созданы для выполнения нагрузочного тестирования. Этот параметр позволяет эффективнее использовать многоядерные процессоры, распределяя нагрузку по различным ядрам и тем самым увеличивая общую производительность тестирования.
Пример запуска теста в 4-х потоках:
1const autocannon = require('autocannon')
2
3autocannon({
4 url: 'https://google.com',
5 connections: 10, //default
6 pipelining: 1, // default
7 duration: 10, // default
8 workers: 4
9}, console.log)Как работают воркеры в autocannon:
Многопоточность: Node.js основан на однопоточной модели событийного цикла, но с помощью воркеров можно использовать дополнительные потоки для выполнения кода параллельно. Это особенно полезно для операций, требующих интенсивных вычислений или блокирующих выполнение, таких как нагрузочное тестирование.
Распределение нагрузки: Использование воркеров позволяет autocannon распределять нагрузку между несколькими потоками, что увеличивает общее количество запросов, которое может быть отправлено и обработано за единицу времени.
Изоляция: Каждый воркер выполняется в своем собственном контексте выполнения, изолированно от основного потока и других воркеров. Это значит, что задачи, выполняемые воркерами, не будут влиять на производительность основного потока приложения.
Когда использовать параметр workers:
Тестирование производительности высоконагруженных систем: Если вы хотите максимально реалистично симулировать нагрузку на сервер, использование нескольких воркеров позволит более эффективно использовать ресурсы тестовой машины.
Использование многоядерных процессоров: На машинах с многоядерными процессорами использование нескольких воркеров может значительно улучшить производительность нагрузочного тестирования, поскольку каждый воркер может быть выполнен на отдельном ядре.
Тестирование приложений с высокой параллельной обработкой: В сценариях, где тестируемое приложение оптимизировано для работы с множеством параллельных запросов, использование воркеров может помочь более точно оценить его производительность.
Заключение по Workers
Использование параметра workers в autocannon является продвинутой функцией, которая может помочь в создании более мощных и настроенных под конкретные нужды сценариев нагрузочного тестирования. Однако стоит помнить, что увеличение количества воркеров также увеличивает потребление системных ресурсов, таких как CPU и память, что может повлиять на результаты тестирования.
Тестирование нескольких URL
С помощью autocannon, вы можете выполнить тестирование нескольких URL за один запуск, создав массив запросов. Это особенно полезно, когда вам нужно тестировать различные эндпоинты API или страницы веб-сайта в рамках одного сеанса нагрузочного тестирования.
Чтобы выполнить тестирование нескольких URL, вы должны использовать программный подход, так как CLI (интерфейс командной строки) autocannon по умолчанию поддерживает тестирование только одного URL за раз. В программной версии вы можете определить массив запросов, где каждый запрос будет содержать разные параметры, включая URL.
Вот пример кода на Node.js, который демонстрирует, как это можно сделать:
1const autocannon = require('autocannon');
2const { promisify } = require('util');
3const autocannonPromise = promisify(autocannon);
4
5async function runBenchmark() {
6 try {
7 const result = await autocannonPromise({
8 url: 'http://example.com', // базовый URL, может быть переопределен в setupRequest
9 connections: 10, // количество одновременных соединений
10 duration: 10, // продолжительность теста в секундах
11 // Определение массива запросов
12 requests: [
13 {
14 method: 'GET', // метод HTTP запроса
15 path: '/', // путь относительно базового URL
16 // Здесь можно добавить тело запроса, заголовки и т.д.
17 },
18 {
19 method: 'GET',
20 path: '/about',
21 },
22 {
23 method: 'POST',
24 path: '/api/data',
25 body: JSON.stringify({ data: 'example' }), // тело запроса
26 headers: { 'Content-Type': 'application/json' }, // заголовки запроса
27 }
28 ],
29 // setupRequest и onResponse могут быть использованы для динамической настройки запросов и обработки ответов
30 });
31
32 console.log('Результат тестирования:', result);
33 } catch (err) {
34 console.error('Ошибка при выполнении нагрузочного тестирования:', err);
35 }
36}
37
38runBenchmark();
39В этом примере autocannon настроен на отправку запросов к трем разным путям (/, /about, /api/data) на http://example.com. Каждый запрос может быть настроен индивидуально, включая метод HTTP, путь, тело запроса и заголовки. Это позволяет тестировать различные аспекты вашего веб-приложения или API, используя один и тот же экземпляр autocannon.
Тонкая настройка запросов
1. Создание объектов клиента для соединений: Когда вы запускаете `autocannon`, он создает объекты клиента (Client) в количестве, соответствующем указанному вами числу соединений. Каждый из этих клиентов будет выполнять запросы параллельно друг другу в течение всего времени тестирования. Это время может быть ограничено либо длительностью теста, либо общим числом запросов.
2. Циклическая обработка массива запросов: Каждый клиент последовательно перебирает массив запросов, который может содержать один или несколько запросов. Это означает, что если в массиве указано несколько запросов, клиент будет отправлять их по очереди до тех пор, пока тест не будет завершен.
3. Поддержка контекста: Во время перебора запросов клиент поддерживает контекст — это специальный объект, который можно использовать для хранения и извлечения данных, специфичных для текущего цикла выполнения запросов. Этот контекст может быть полезен, например, для сохранения результатов предыдущих запросов и использования их в последующих запросах или для изменения поведения запросов на основе предыдущих ответов.
4. Функции `onResponse` и `setupRequest`: Вы можете использовать эти функции для работы с контекстом. Функция `setupRequest` позволяет настраивать запросы перед их отправкой, используя данные из контекста, а `onResponse` — обрабатывать ответы сервера, возможно, модифицируя контекст для следующих запросов.
5. Сброс контекста: Когда клиент завершает цикл по массиву запросов и возвращается к первому запросу для повторной отправки, контекст сбрасывается. Это делается для обеспечения одинаковых условий для каждого нового цикла запросов. Контекст будет сброшен к начальному состоянию (`initialContext`), предоставленному вами, или к пустому объекту `{}`, если начальный контекст не был указан.
Этот механизм контекста и настройки запросов предоставляет гибкие возможности для имитации сложных пользовательских сценариев и тестирования веб-приложений с учетом состояний и последовательностей запросов.
Комбинирование соединений, общей скорости и количества
Когда вы настраиваете `autocannon` для выполнения определенного количества HTTP-запросов (`amount`), используя фиксированное количество одновременных соединений (`connections`) с ограничением на общую скорость отправки запросов (`overallRate`), `autocannon` стремится равномерно распределить эту нагрузку между всеми соединениями. Это распределение включает в себя как количество запросов, так и скорость их отправки.
Распределение общей скорости (`overallRate`)
- Если значение `overallRate` (заданное в запросах в секунду для всего теста) не делится нацело на количество соединений (`connections`), `autocannon` будет настраивать часть соединений на отправку немного большего количества запросов в секунду, а другую часть — на отправку меньшего количества. Это делается для того, чтобы в сумме достичь заданной общей скорости.
Распределение количества запросов (`amount`)
- Если общее количество запросов (`amount`) делится нацело на количество соединений, каждое соединение получит одинаковое количество запросов для выполнения.
Влияние на воспринимаемую скорость запросов
- В случае неделимости `overallRate` на количество соединений, соединения с высшей скоростью отправки запросов завершат свою работу раньше остальных. Как результат, когда эти более быстрые соединения закончат отправлять свои запросы, общее количество активных запросов в секунду упадет, поскольку оставшиеся активные соединения будут отправлять меньше запросов. Это приведет к снижению воспринимаемой общей скорости запросов к концу теста.
Пример
Допустим, у нас есть следующие параметры: `connections = 10`, `overallRate = 17`, `amount = 5000`. Это означает, что `autocannon` будет стремиться распределить общее количество запросов (5000) между 10 соединениями таким образом, чтобы общая скорость запросов не превышала 17 запросов в секунду на все соединения вместе взятые. Если деление не нацело, некоторые соединения будут работать быстрее, а некоторые — медленнее, чтобы в сумме обеспечить заданную скорость.
Лимиты
В этом блоке поднимем важный вопрос о производительности и ограничениях при использовании инструмента для нагрузочного тестирования, особенно в сравнении с другими инструментами, такими как wrk и wrk2.
Процессорные Ресурсы
- Ограниченность процессорными ресурсами: `Autocannon`, как и любой инструмент, написанный на JavaScript и работающий в среде Node.js, активно использует процессорные ресурсы (CPU-bound). Это значит, что его производительность и способность генерировать нагрузку зависят от мощности и загрузки процессора.
Сравнение с `wrk`
- Потребление CPU: По сравнению с `wrk`, который компилируется в бинарный код и обычно использует меньше процессорного времени, `autocannon` может использовать значительно больше CPU для выполнения аналогичных задач нагрузочного тестирования. Пример с использованием 1000 соединений на 4-ядерном сервере с поддержкой Hyper-Threading демонстрирует, что `wrk` распределяет свою нагрузку более эффективно, используя несколько потоков, в то время как `autocannon` нагружает один поток на 80%.
Рекомендация использования `wrk2`
- Насыщение CPU: Если процесс `autocannon` достигает 100% использования CPU, это может повлиять на точность и надежность результатов тестирования. В таких случаях рекомендуется использовать `wrk2`, который может обеспечить более низкую и равномерную нагрузку на процессор.
Поддержка HTTP/1.1 Pipelining
- HTTP/1.1 Pipelining: Одним из преимуществ `autocannon` перед `wrk` является поддержка пайплайнинга HTTP/1.1, что позволяет `autocannon` создавать большую нагрузку на сервер за счет одновременной отправки нескольких HTTP-запросов в рамках одного соединения без ожидания ответа на каждый запрос. Это может быть особенно полезно при тестировании серверов и приложений, оптимизированных для работы с HTTP/1.1 pipelining.
Подводим итоги
`Autocannon` — мощный и гибкий инструмент, написанный на JavaScript для среды Node.js, который позволяет проводить комплексное тестирование производительности веб-приложений и API. Он предлагает широкий спектр настраиваемых параметров, включая поддержку HTTP/1.1 pipelining, возможность тестирования нескольких URL за один запуск и гибкое управление количеством запросов, соединений и продолжительностью теста.
Однако, как и любой инструмент, `autocannon` имеет свои ограничения, включая высокую нагрузку на CPU при интенсивном использовании, что может потребовать перехода к альтернативам, таким как `wrk2`, в определенных ситуациях. Несмотря на это, `autocannon` остается важным инструментом в арсенале разработчиков и тестировщиков благодаря его простоте использования, возможности интеграции в автоматизированные тестовые сценарии и глубокой настройке параметров тестирования.
Используя `autocannon`, команды могут лучше понять поведение и пределы своих систем под нагрузкой, выявлять узкие места и оптимизировать производительность, обеспечивая высококачественный пользовательский опыт. В конечном итоге, успешное нагрузочное тестирование — ключевой компонент в процессе разработки любого масштабируемого и надежного веб-приложения или сервиса, и `autocannon` предоставляет все необходимые инструменты для достижения этих целей.
Статью мне помогали писать:
1) Эта статья.
2) Документация autocannon.
3) ChatGPT