
Опубликовал:
Использование файла конфигурации SSH
Привет. Иногда мы подключаемся к удаленному компьютеру с помощью технологии ssh (secure shell). Сначала мы генерируем пару ключей: приватный и публичный. Публичный кладем на удаленный компьютер. Далее вбиваем в терминале что-то вроде ssh username@210.190.13.14 Соединение установлено и мы можем работать на удаленном компьютере как на собcтвенном.
Отлично, но что делать если вы хотите подключаться к нескольким удаленным компьютерам? Можно поступить глупо и положить на все удаленные сервера один и тот же публичный ключ. Это будет работать, но значительно снизит безопасность таких соединений. В идеальном мире, каждое соединение должно осуществляться с собственной парой приватного и публичного ключа. К примеру, если вам понадобится дать своему коллеге доступ к серверу, вы можете передать ему только один ключ (в идеале нужно сгенерировать новый) и коллега получит доступ только к одному компьютеру, а не ко всем сразу. К тому же, разные сервера имеют разные ip адреса, на них установлены разные пользователи, могут быть нестандартные порты и другие мелкие детали. Все это нужно помнить, либо где-то записывать. Все это отнимает наше драгоценное время.
11 полезных советов по современному JavaScript

Автор статьи: Krina Sardhara
Оригинал: https://medium.com/dhiwise/11-useful-modern-javascript-tips-9736962ed2cd
В нашей повседневной программистской рутине мы часто использовали числа для преобразования строк, проверки ключей в объекте, условного манипулирования данными объекта, фильтрации ложных значений в массиве и т. д.
Здесь я описала несколько советов, которые мне очень нравятся ❤️ ️. Мне кажется они очень полезны и делают мой код короче и чище.

Погружение в модули JavaScript. Типы модулей, форматы, загрузчики и сборщики модулей.
Разрабатывая веб сайты или веб приложения мы все чаще переносим выполнение кода на клиент, в браузер. Это и обычные страницы с множеством ajax вызовов, и популярные в наше время SPA (Single Page Application), а так же полноценные приложения по типу Figma и прочих конструкторов, где 90% работы выполняет именно браузер.
Но по мере того как расширяется кодовая база клиентского приложения возникают разумные вопросы: Как управлять большой кодовой базой? Как разделить код на части и переиспользовать их? Как создать гибкую и расширяемую архитектуру приложения?
На эти и другие вопросы я отвечу в данной статье. Мы посмотрим на решения в других языках программирования, заглянем в историю JavaScript, увидим как развивались модульные системы в нашем любимом языке и какова ситуация на данный момент.
Python SimpleHTTPServer - Простой HTTP на Python

Модуль Python SimpleHTTPServer — очень удобный инструмент. С помощью этого модуля можно легко превратить любой каталог в вашей операционной системе в простой HTTP веб сервер.
Как создать объект в JS? Для этого нужно изучить Java

На днях мне понадобилось объяснить как работают конструкторы в JavaScript, как создавать объекты и наследоваться от нужных прототипов. На первый взгляд тут нет ничего сложного, но на самом деле тема эта очень обширна.
При прочтении этой статьи обязательно практикуйтесь, иначе материал усвоится плохо.
Итак, чтобы разобраться в создании объектов в JavaScript нужно изучить синтаксис создания объектов в Java? Так! Стоп! Java? Да, да! Все в порядке - это будет увлекательное путешествие, так что не будем терять время.
Создание пользовательской страницы 404 в Next.js

В данной статье показан простой пример создания страницы 404 в NextJS.
Поддержка нескольких store в React-Redux приложении
Использование нескольких redux хранилищ в React приложении быть довольно сложным.

В приложении с React-Redux рекомендуется иметь только одно хранилище (один store). Но если по какой-то странной/особой причине вам нужно иметь более одного store, вы столкнетесь с проблемами.
Самая распространенная проблема заключается в том, что если мы оборачиваем компонент провайдером, а затем оборачиваем дочерний компонент другим провайдером, подписаться на хранилище провайдера верхнего уровня непросто.
1const Component1 = () => {
2 return (
3 <Provider store={store1}>
4 <Provider store={store2}>
5 <Component2 />
6 </Provider>
7 </Provider>
8 );
9};Это настолько запутанно, что через несколько итераций разработки вы обнаружите, что используете провайдеров для каждого компонента, и неспособность считывать значения из обоих хранилищ в одном компоненте вас расстроит.
Чтобы справиться с этой проблемой нам необходимо выполнить некоторые приготовления
Для этого нам понадобится react-redux 7 или выше. Поскольку версии ниже не используют Context API React. Мы будем использовать контексты для доступа к нескольким хранилищам без повторного использования провайдеров.
Создайте контекст для каждого store. Вы также можете импортировать ReactReduxContext из react-redux и использовать его для каждого из stor-ов, который вы хотите использовать в нужный момент.
1const store1Context = React.createContext();
2const store2Context = React.createContext();Теперь оберните корневой компонент React приложения провайдером для каждого хранилища, передав контексты в качестве реквизита.
1<Provider store={store1} context={store1Context}>
2 <Provider store={store2} context={store2Context}>
3 <App/>
4 </Provider>
5</Provider>Нам также нужно создать пользовательские dispatch хуки и selector хуки. Если вы используете хуки по умолчанию (useSelector, useDispatch), он будет использовать хранилище с контекстом по умолчанию, если таковой имеется.
1import {
2 createDispatchHook,
3 createSelectorHook,
4} from 'react-redux';
5
6export const useStore1Dispatch = createDispatchHook(store1Context);
7export const useStore1Selector = createSelectorHook(store1Context);
8
9export const useStore2Dispatch = createDispatchHook(store2Context);
10export const useStore2Selector = createSelectorHook(store2Context);Теперь, в дальнейшей разработке, вы можете использовать эти настраиваемые селекторы и диспатчеры для использования нужного хранилища в любом из компонентов приложения.
Если вы предпочитаете подключать store компонентом высшего порядка (HOC), вы можете сделать:
1connect(mapStateToProps, mapDispatchtoProps,mergeProps, {context: store1Context})(Component) Это все. Если у вас будут вопросы, пожалуйста пишите комментарии. Спасибо.
За основу данной статьи, использована статья Handling multiple stores in a React-Redux application от автора Vikas Kumar
Способы отладки NodeJS приложений
В современном мире "Фронтенда" необходимо писать не только клиентские приложения на JavaScript, но и серверную часть на NodeJS. Чаще всего такие сервера называют аббревиатурой BFF (Back For Frontend). Часто приходится использовать сервер для рендеринга HTML. Отлаживать такие приложения иногда становится довольно проблематично. Поэтому, я хочу поделиться своим методами.

Давайте же приступим.
Inspect
Самое первое, что приходит в голову - это флаг --inspect при запуске программы на NodeJS (см. доку).
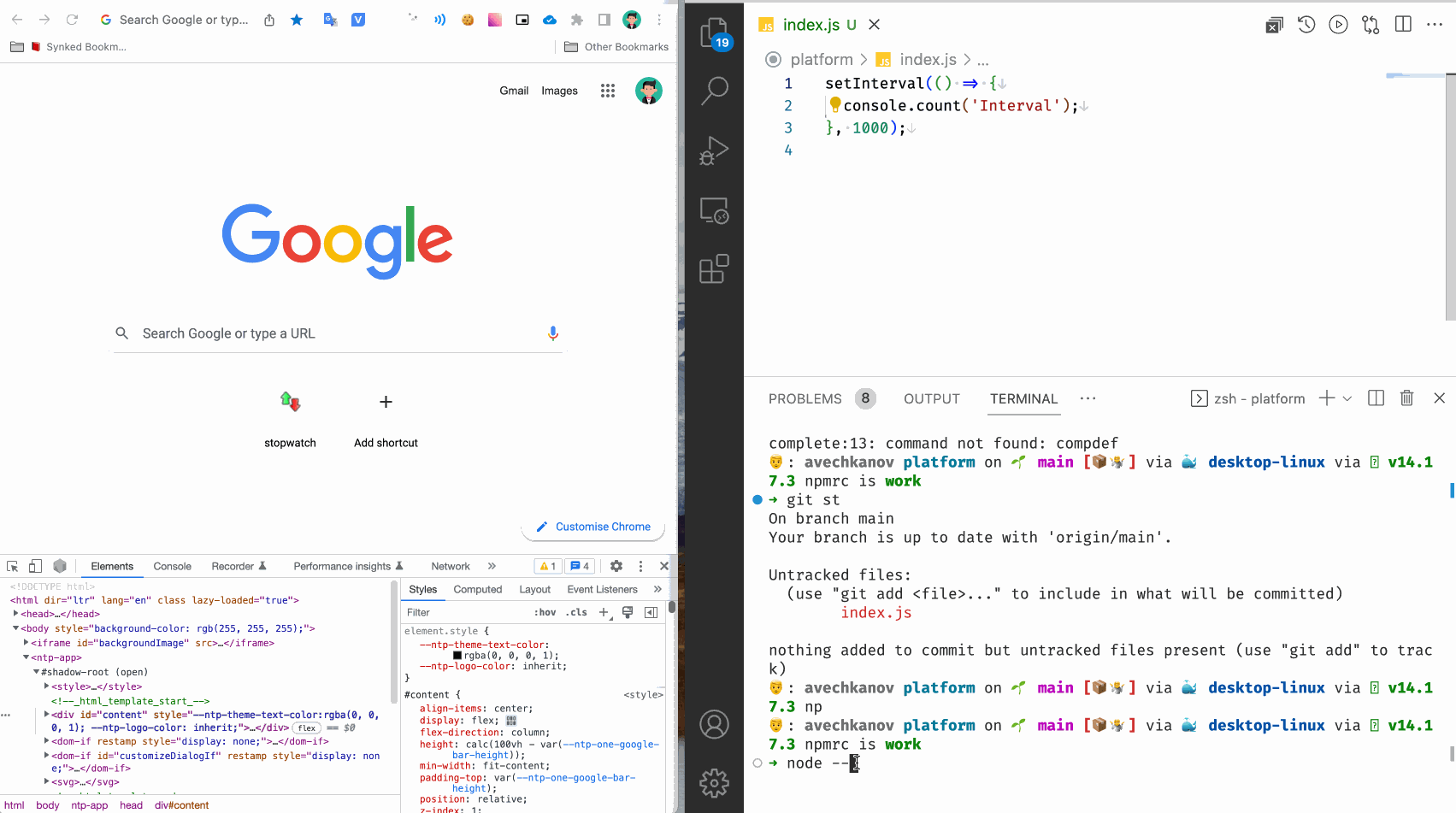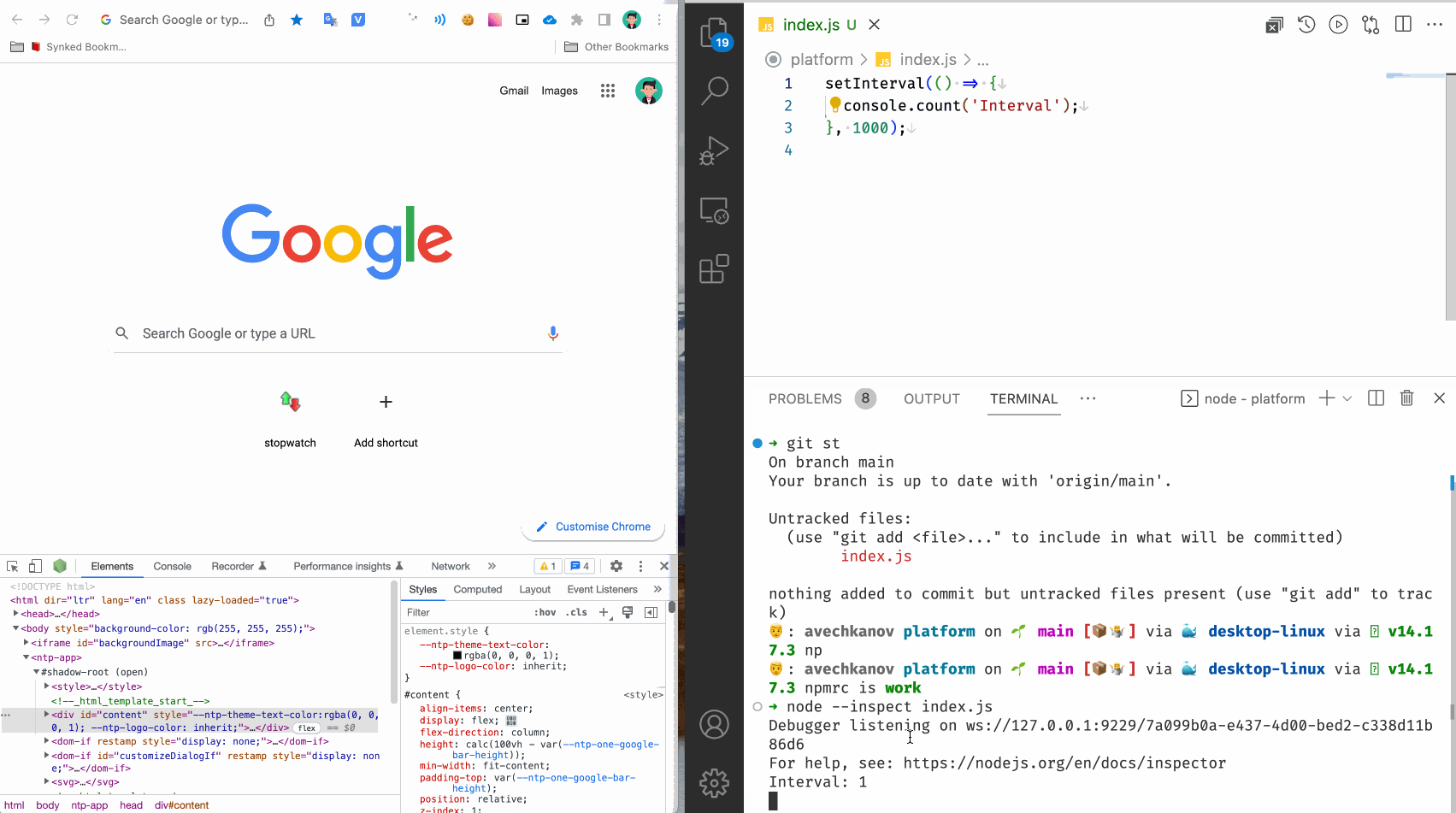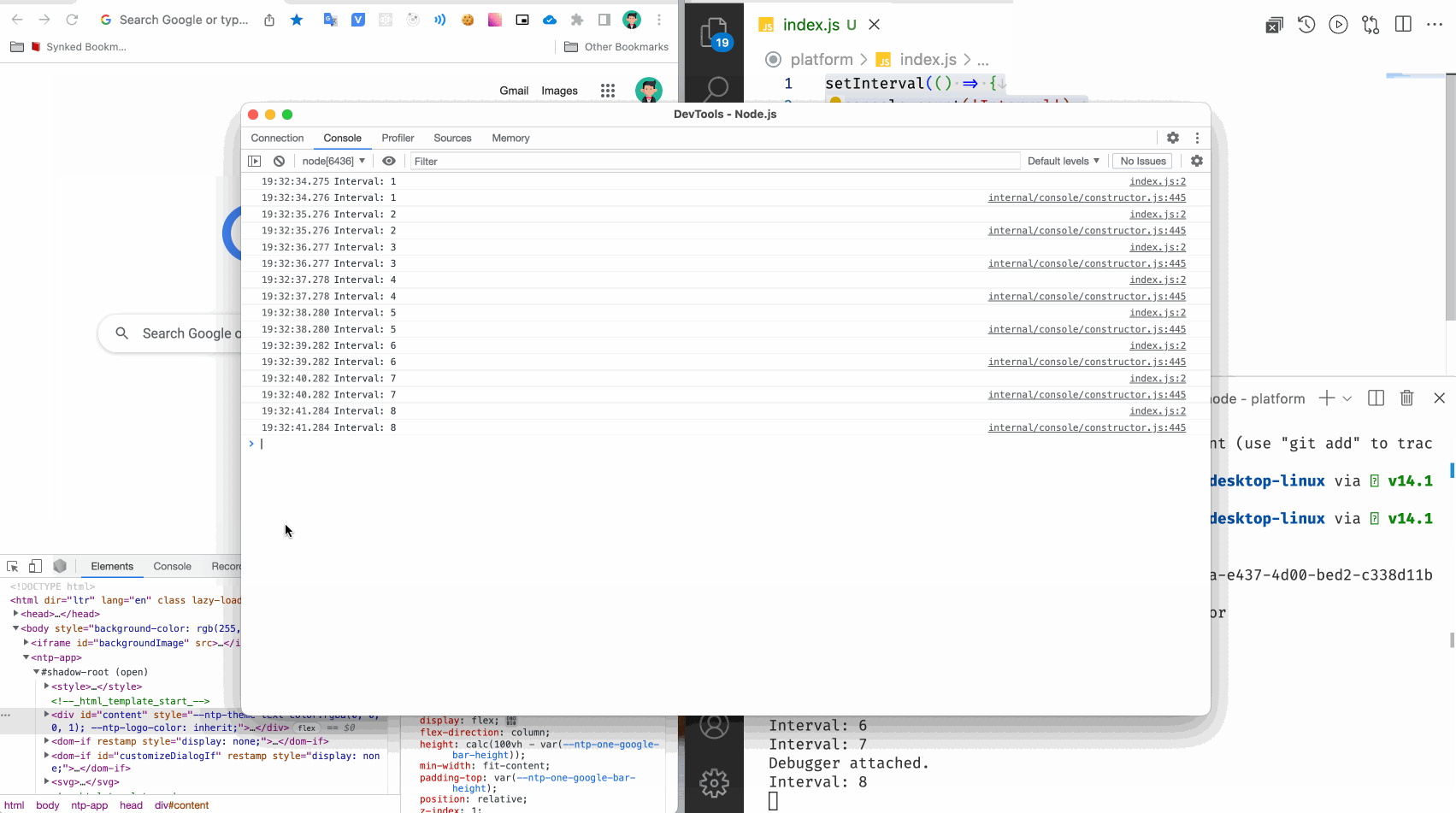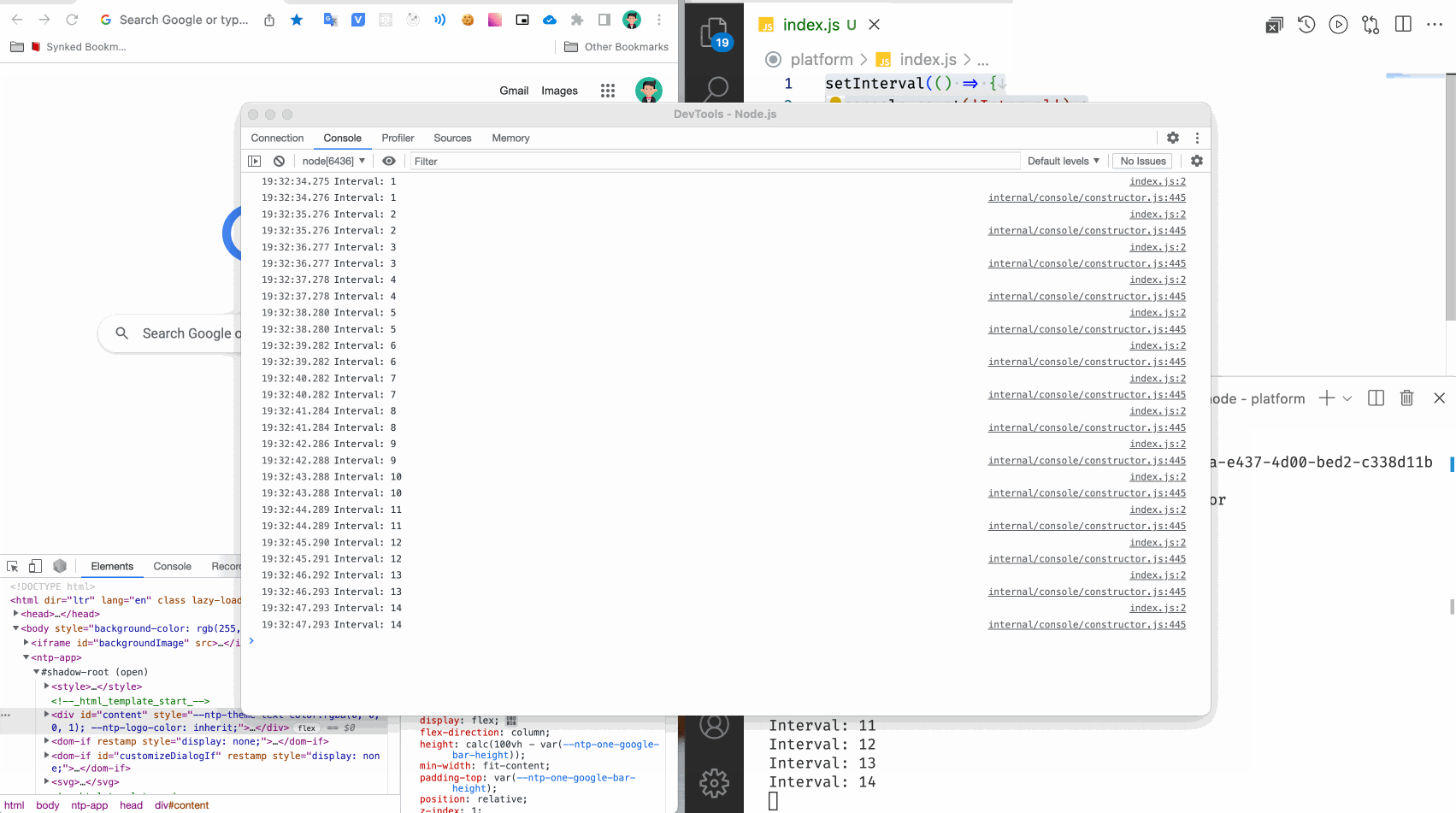
Создадим файл index.js со следующим содержимым:
setInterval(() => {
console.count('Interval');
}, 1000);
Запустим командой node --inspect index.js
В консоли видим вывод:
Debugger listening on ws://127.0.0.1:9229/f7a0b5f7-edf1-4874-83d6-49b07c009f65
For help, see: https://nodejs.org/en/docs/inspector
Debugger attached.
Отлично! Интервал начал свой счет, а программа подключилась к дебаггеру Хрома. Если совсем просто, то при установке Google Chrome устанавливаются дополнительные модули которые слушают сообщения на специальных портах. Обычно это порты 9229 и 9222 (могут быть и другие). Получается, что запуск NodeJS программы начинает слать весь свой вывод на один из этих портов.
Теперь мы можем открыть Инспектор прямо в инструментах разработчика браузера Google Chrome. Если ваше приложение запущено с инспектором, то вы увидите иконку NodeJS на панели devtools.
Вы можете выводить объекты, массивы и другие сложные типы данных для удобного просмотра в консоли браузера.
Подключение инспектора из дочернего процесса
Пока все супер. Пока запущенный процесс один. Проблемы начинаются когда в разработке участвуют несколько процессов. Чаще всего это запуск веб сервера, webpackDevServer, собирается это все с помощью Webpckack (это тоже процессы node и не один). А запускаются все эти процессы одним родительским, скажем, react-create-app.
В таком случае запуск react-create-app с флагом привяжет инспектор только к родительскому процессу. Но как подключить инспектор к дочерним процессам? Этого тоже можно легко добиться.
Создадим второй файл child.js и обновим содержимое обоих файлов.
index.js
const { spawn } = require('child_process');
const child = spawn('node', ['child.js']);
child.stdout.on('data', data => {
console.log(`Child stdout:\n${data}`);
});
setInterval(() => {
console.count('Parent');
}, 1000);
child.js
setInterval(() => {
console.count('Child');
}, 1000);
Таймеры мы запускаем чтобы процессы NodeJS не завершались. Мы используем модуль spawn для запуска дочернего процесса. Так же подписываемся на все события data. Подробнее про дочерние процессы можете почитать здесь.
Итак, смотрим что получилось:
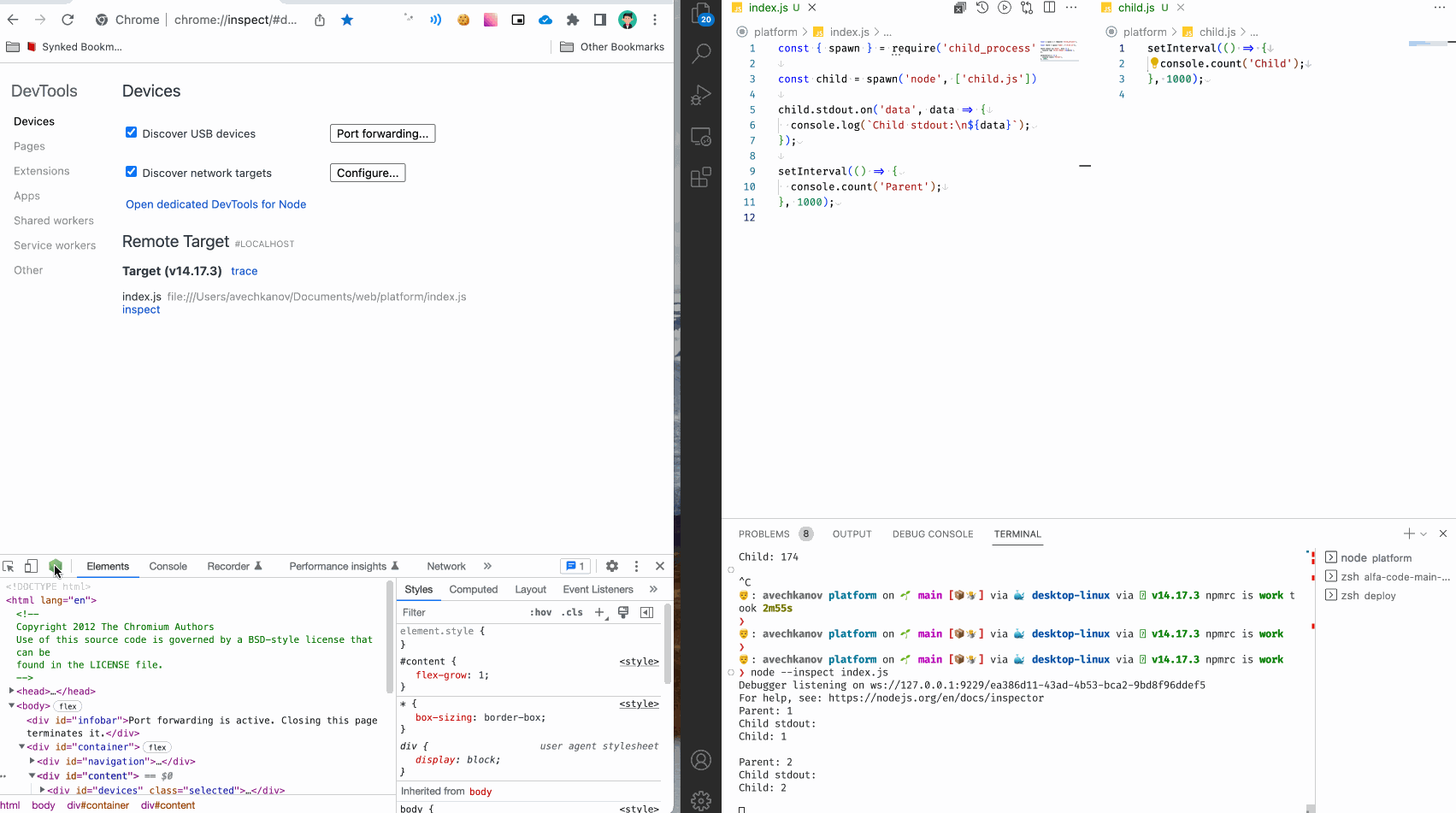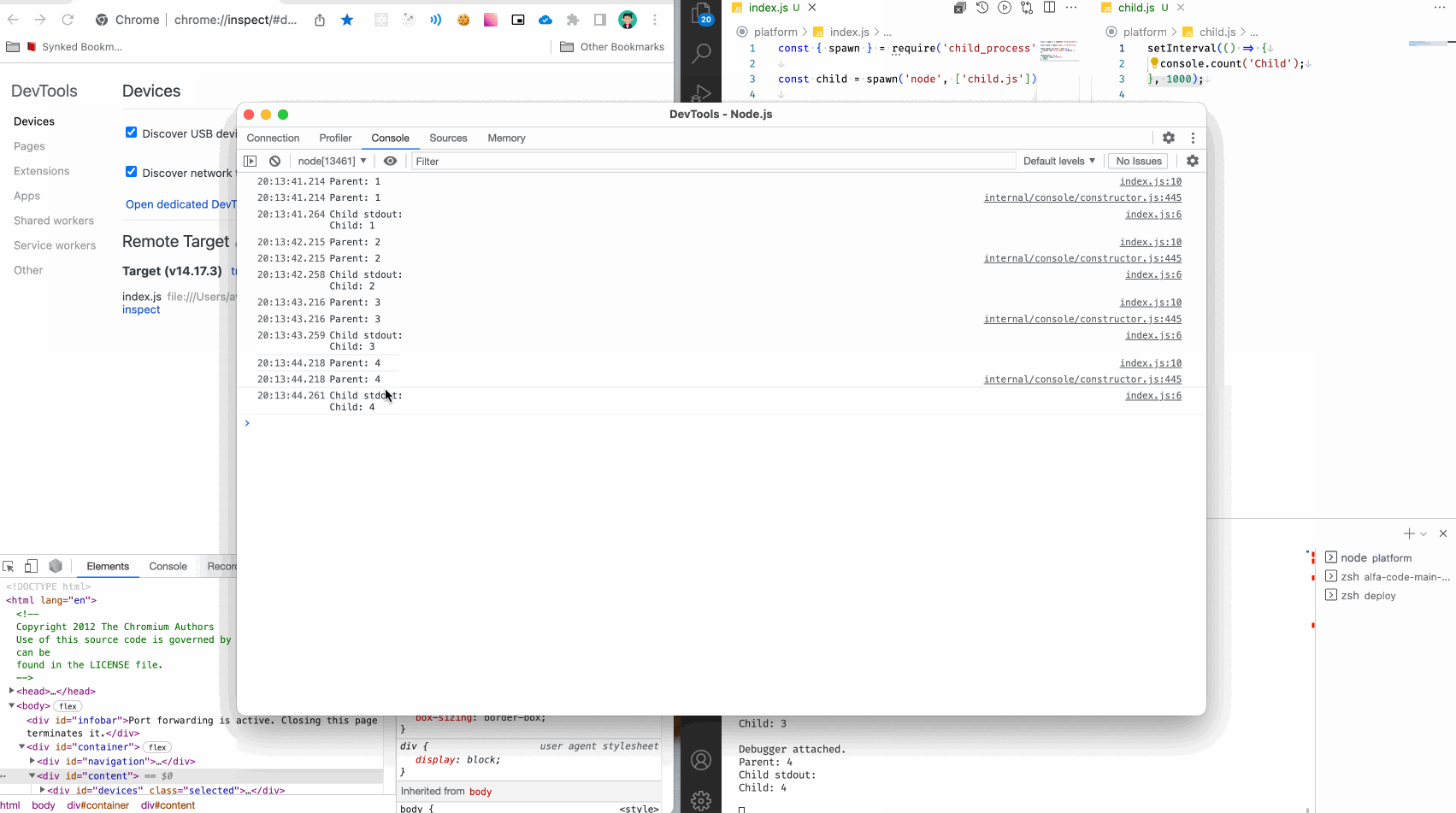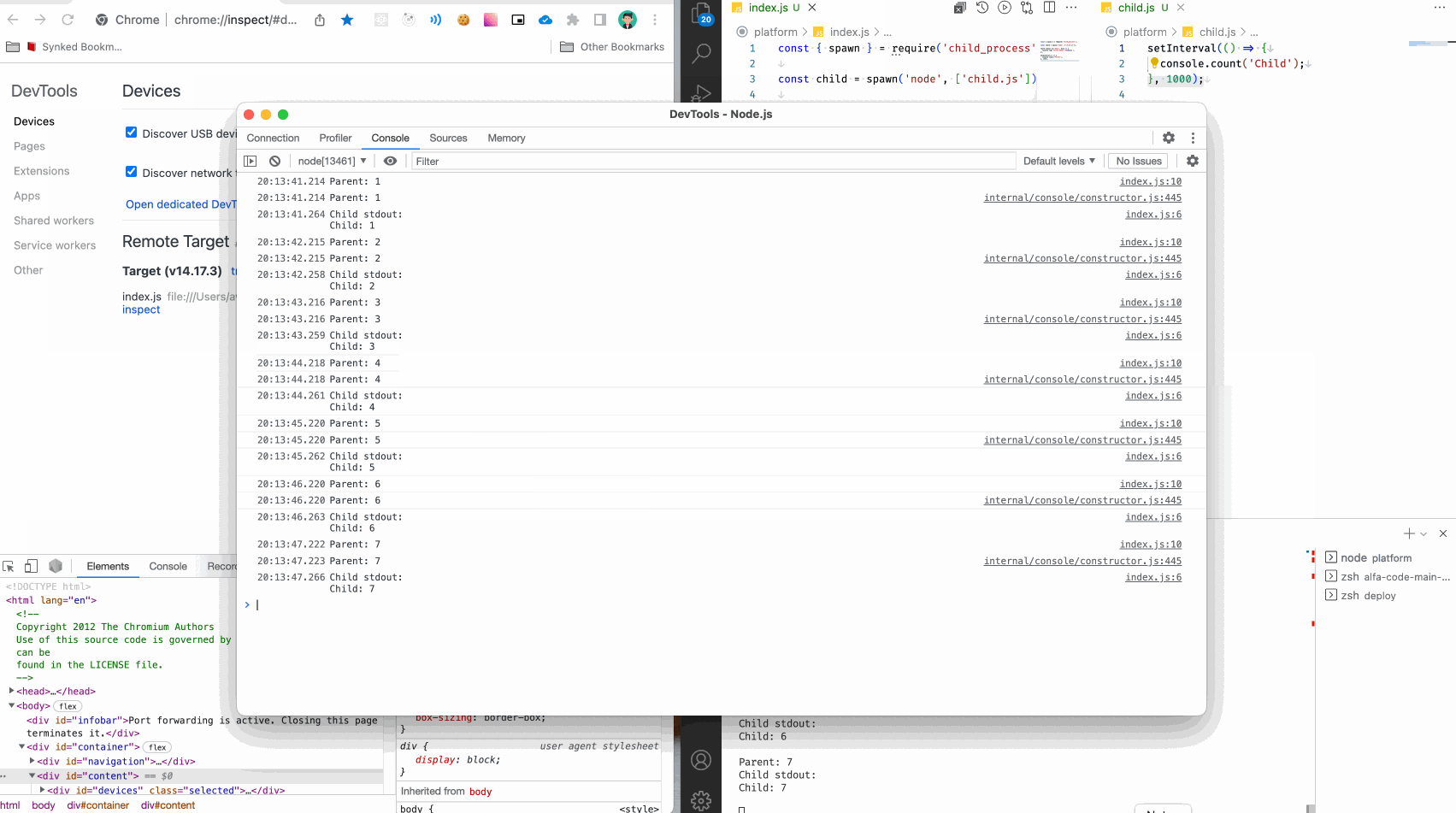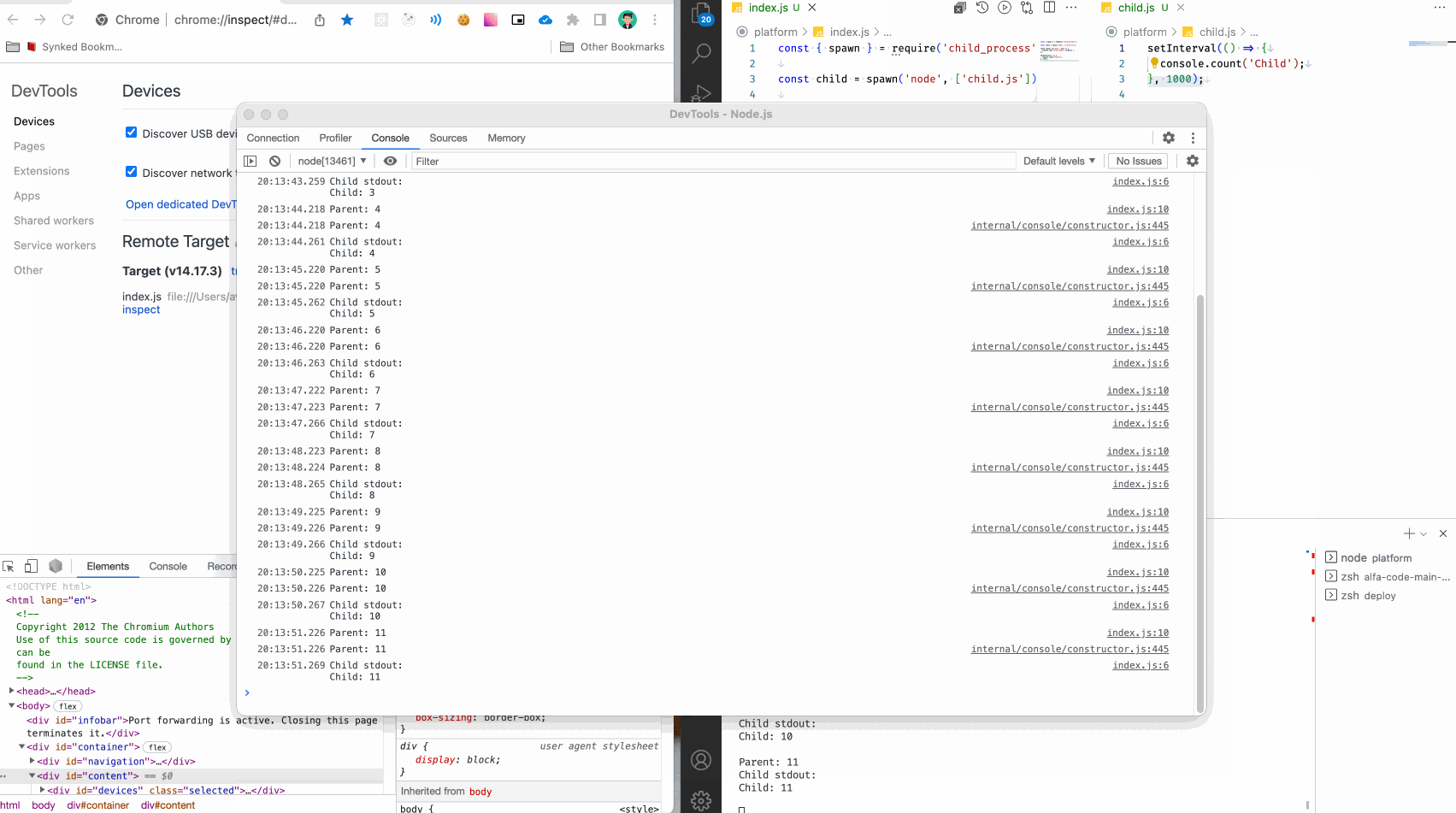
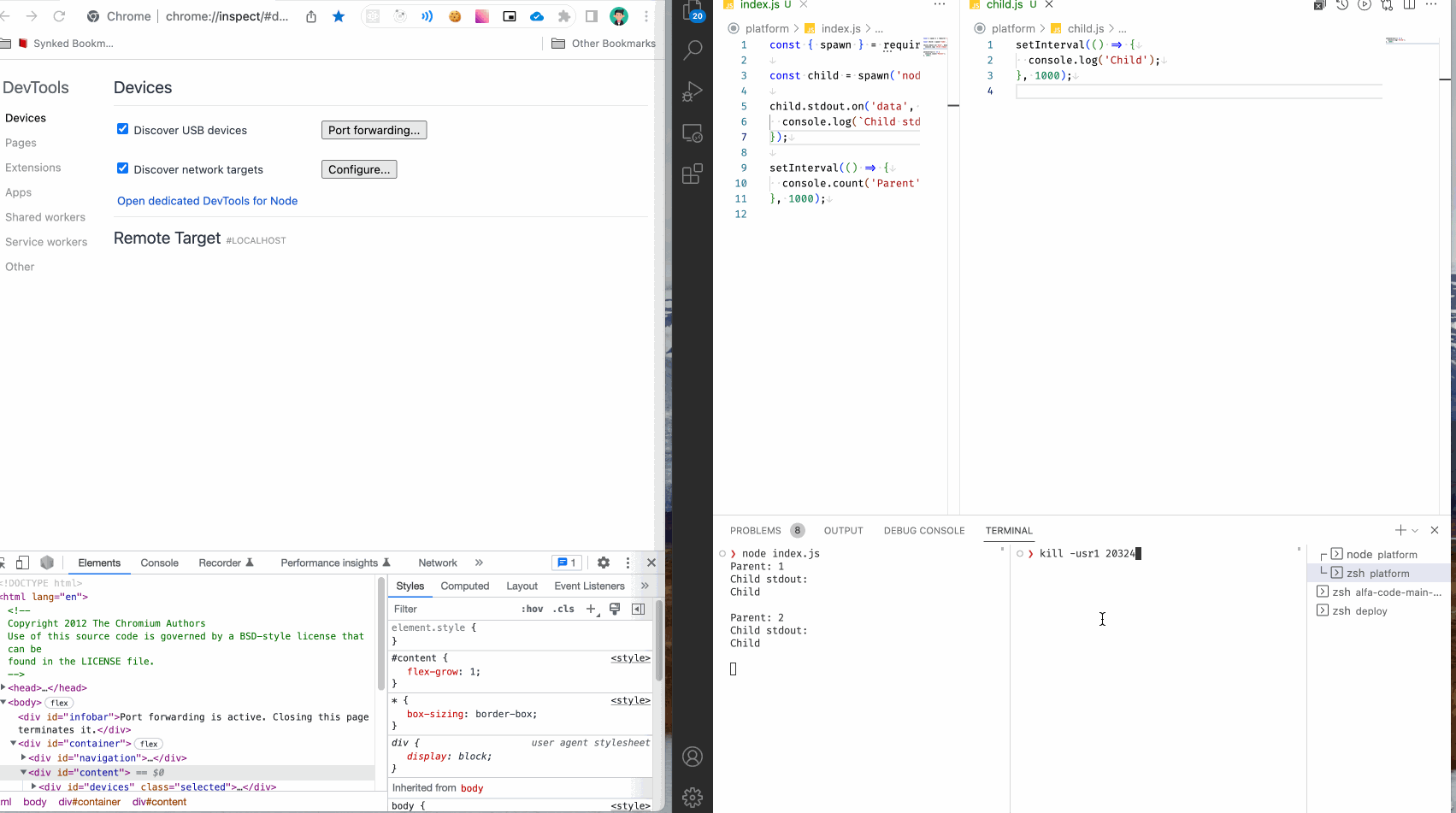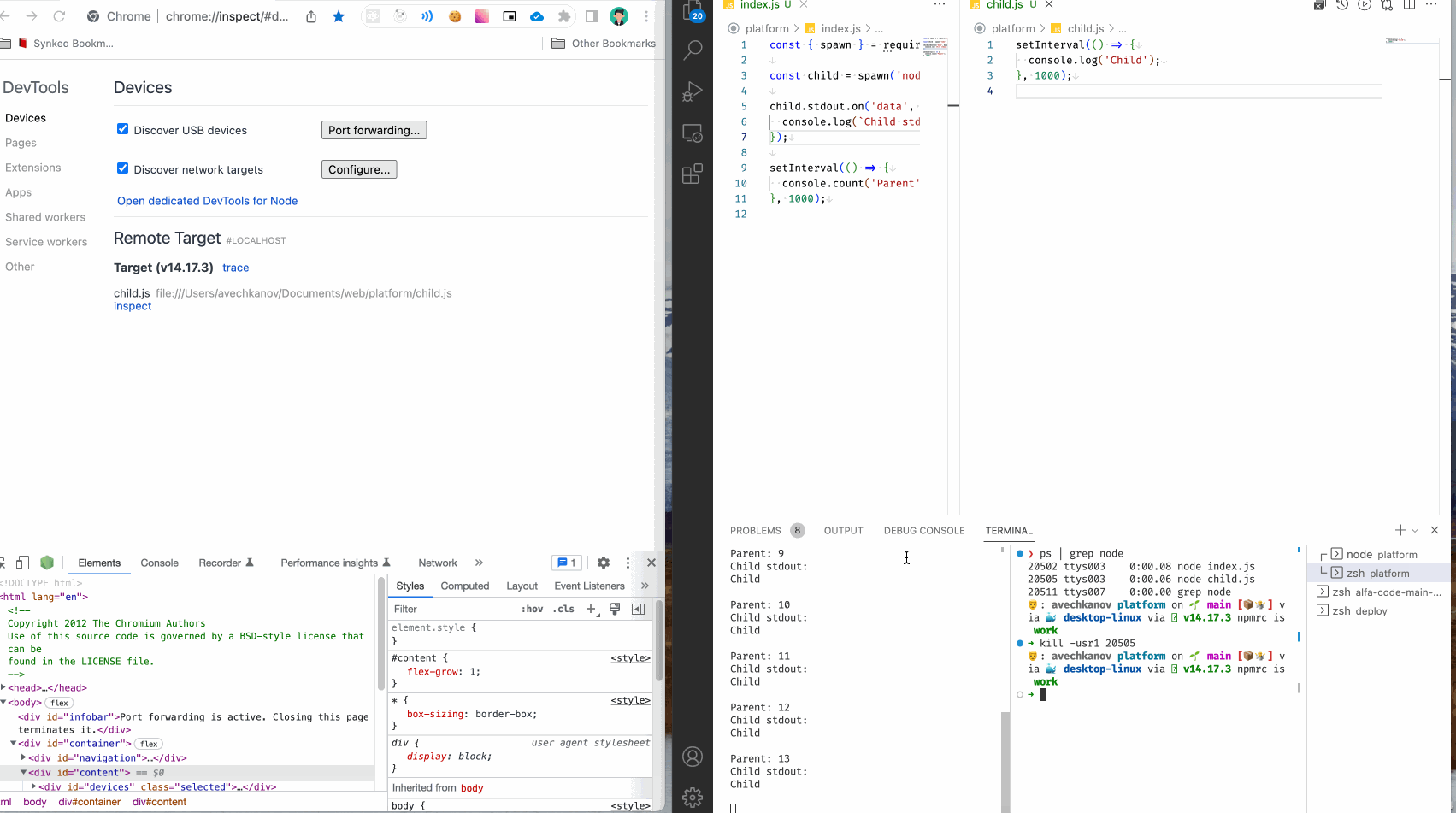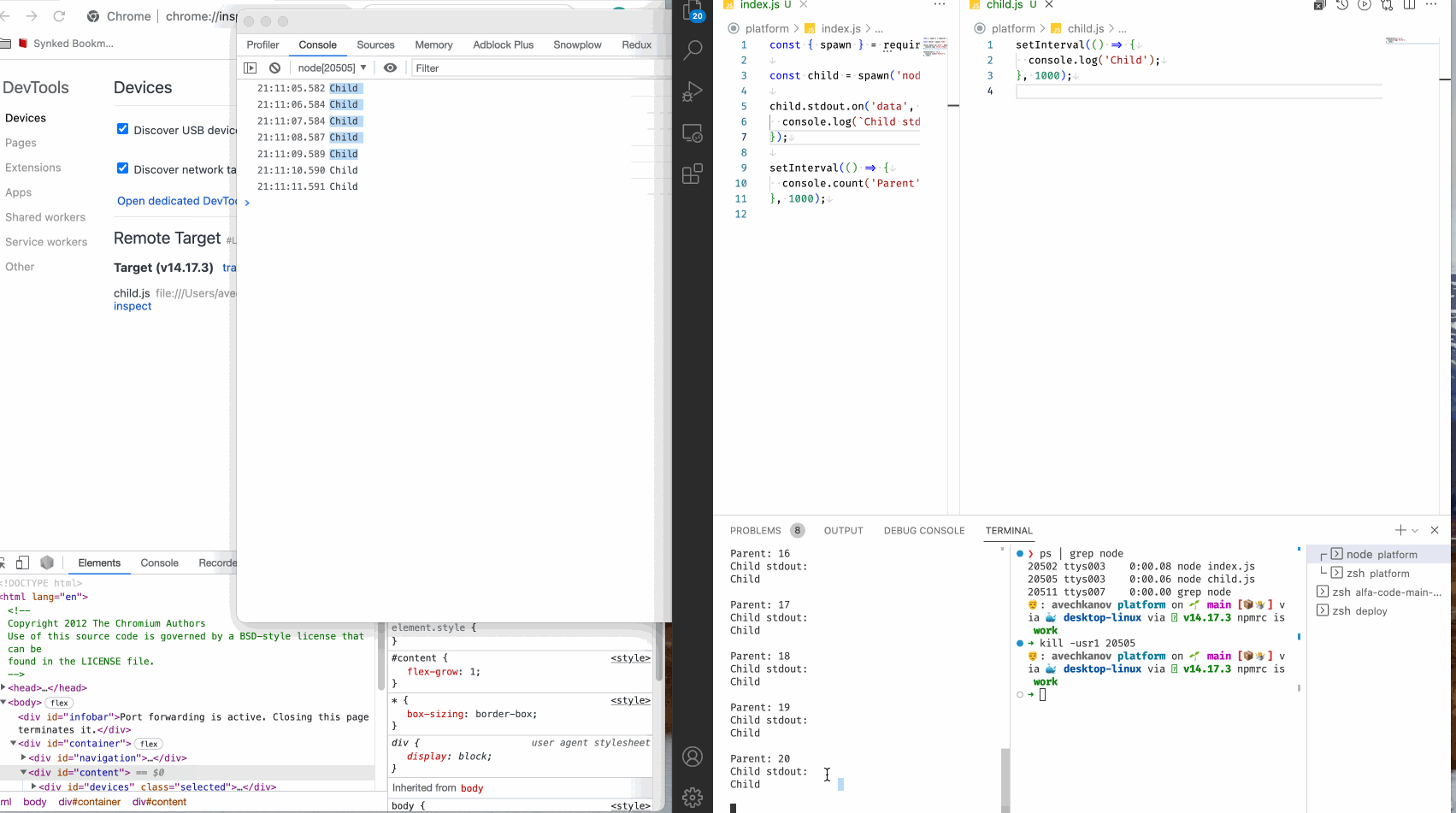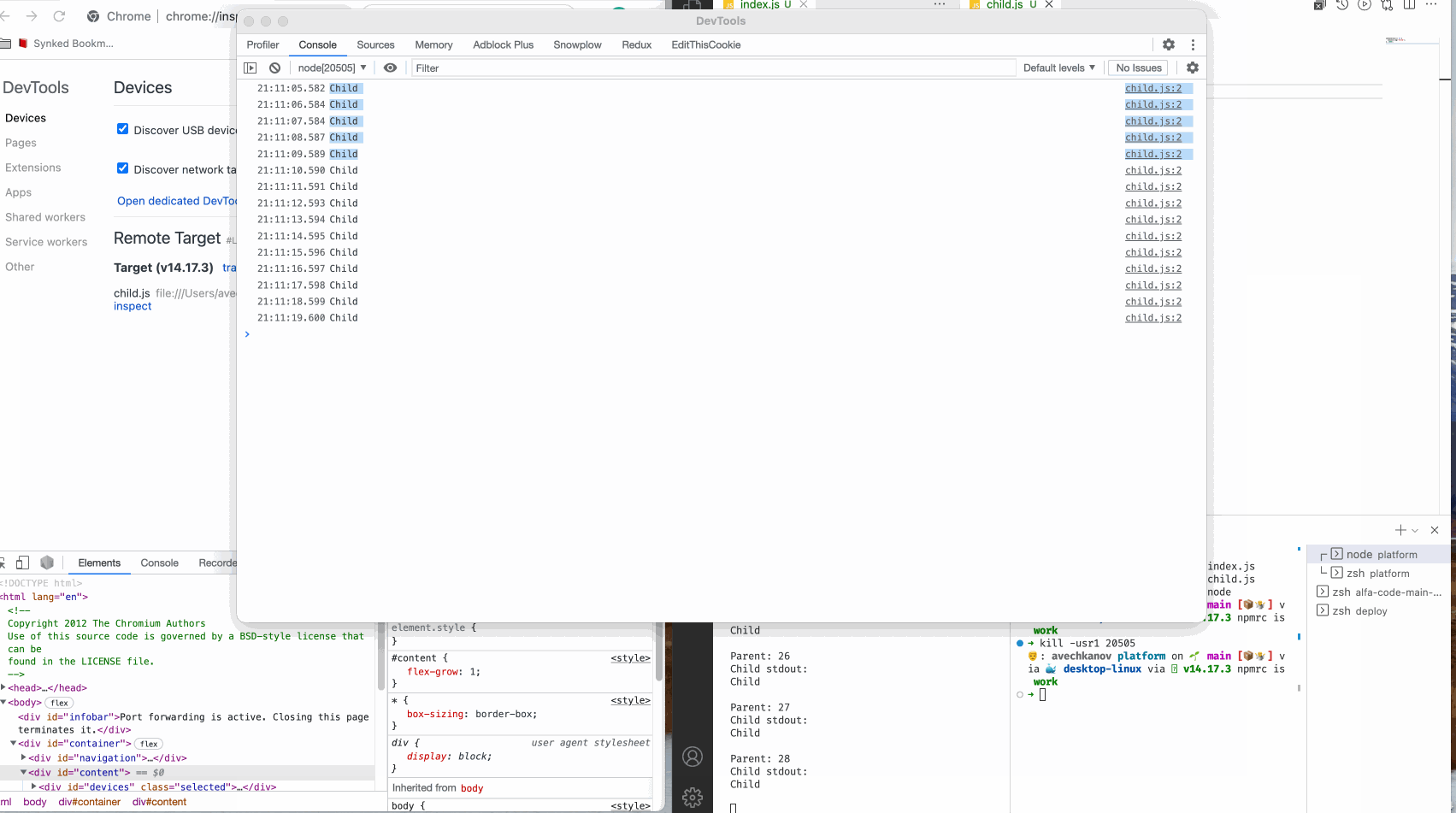
В консоли мы видим логи из родительского сервиса, и логи из дочернего.
Но! Во-первых, это неудобно - все сливается в кашу. Во-вторых, мы почти никогда не имеем доступ к коду фреймворков и сборщиков, чтобы подписаться на сообщения дочерних процессов.
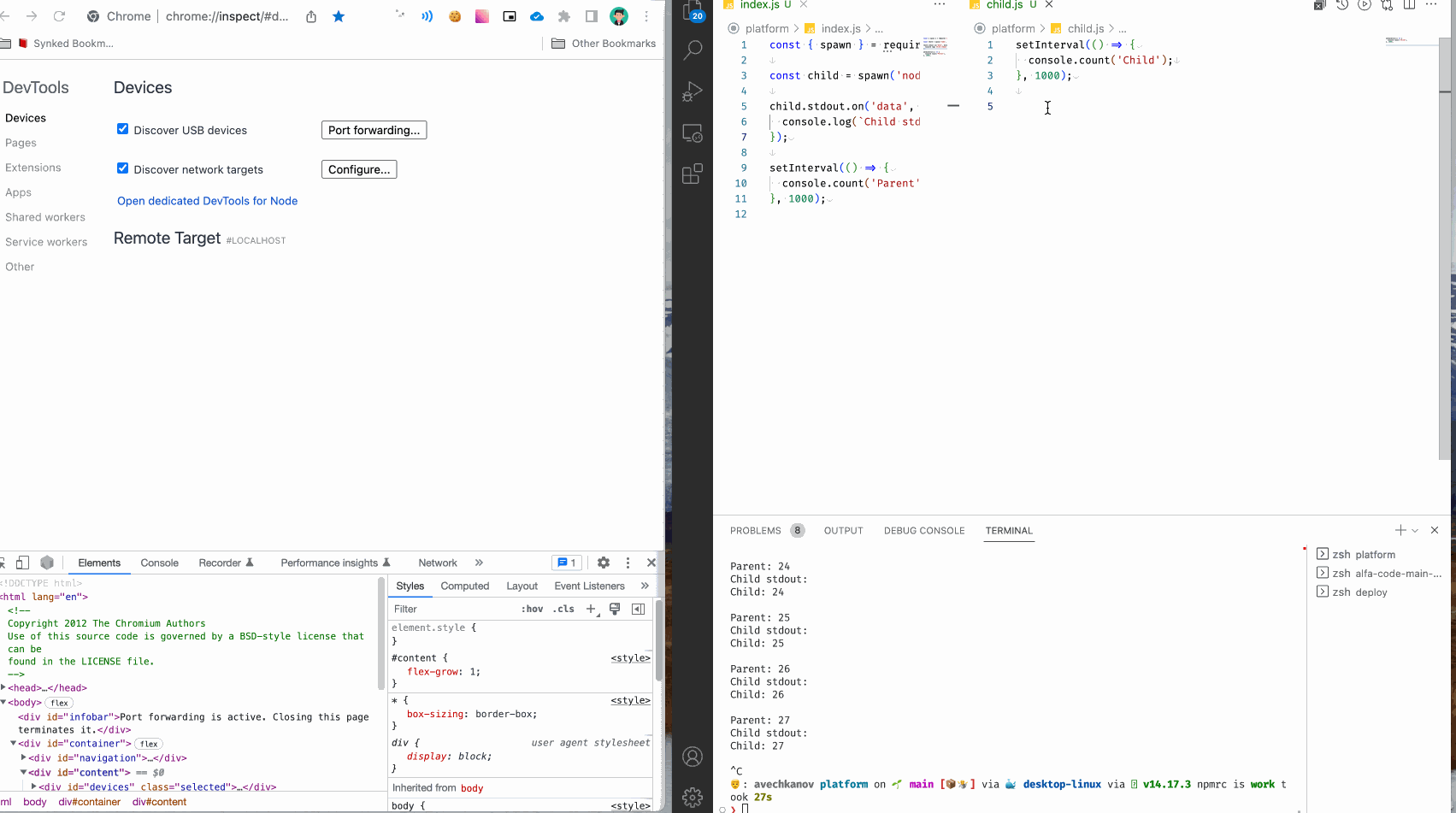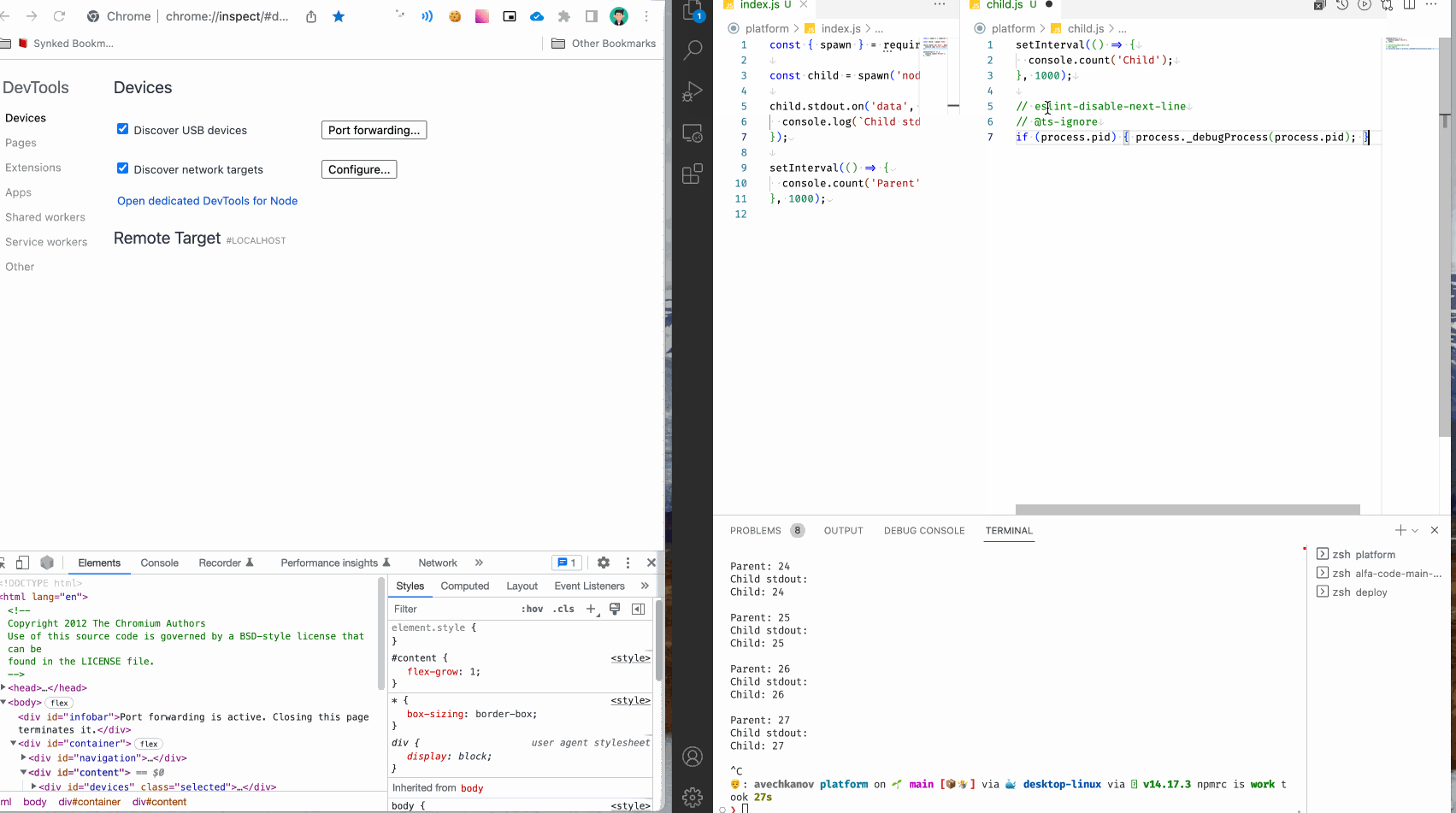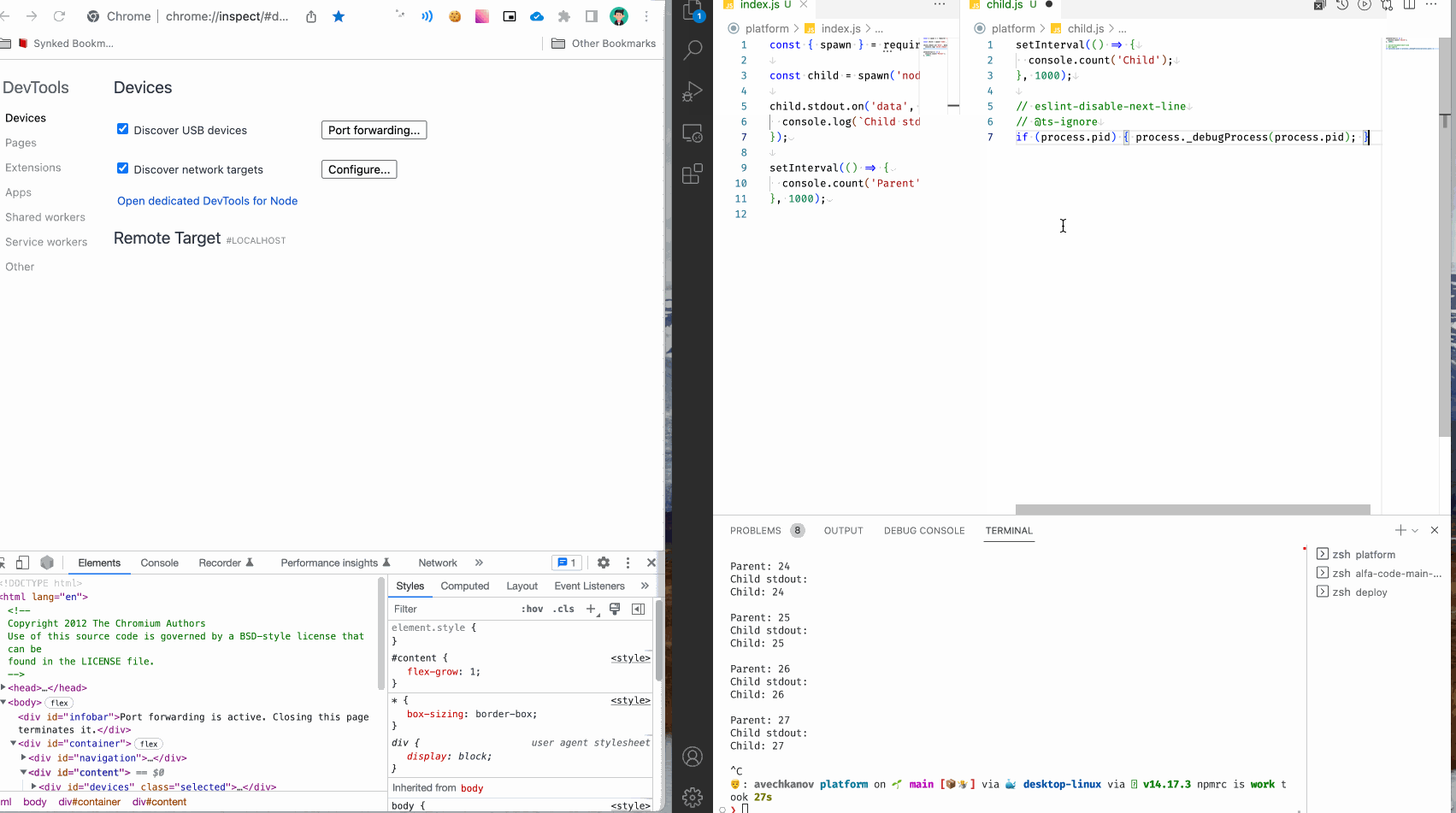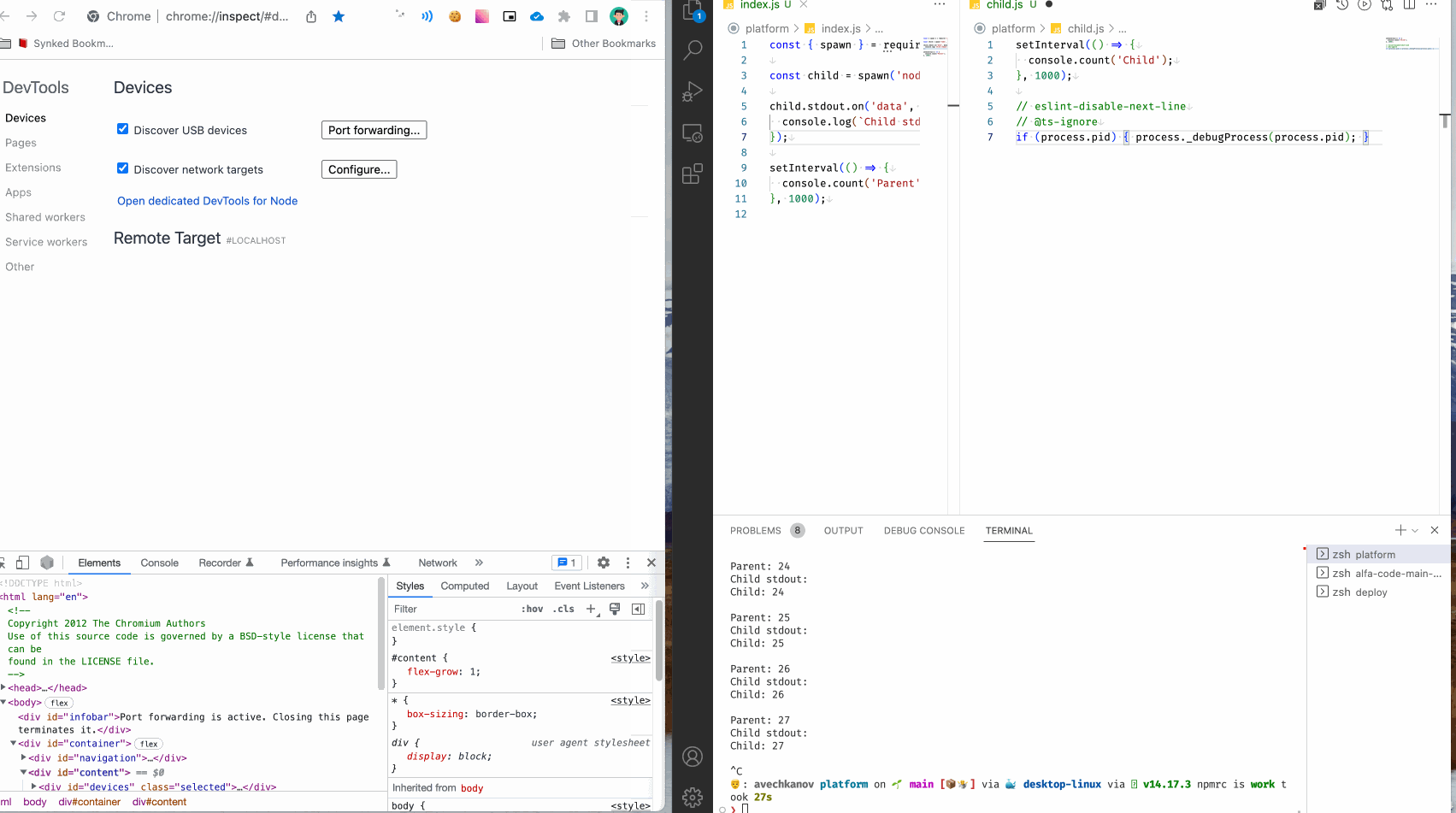
Можем поступить иначе. Добавьте следующую строчку в файл child.js и запустите родительский процесс, но теперь без флага --inspect.
process._debugProcess(process.pid);
Смотрим:
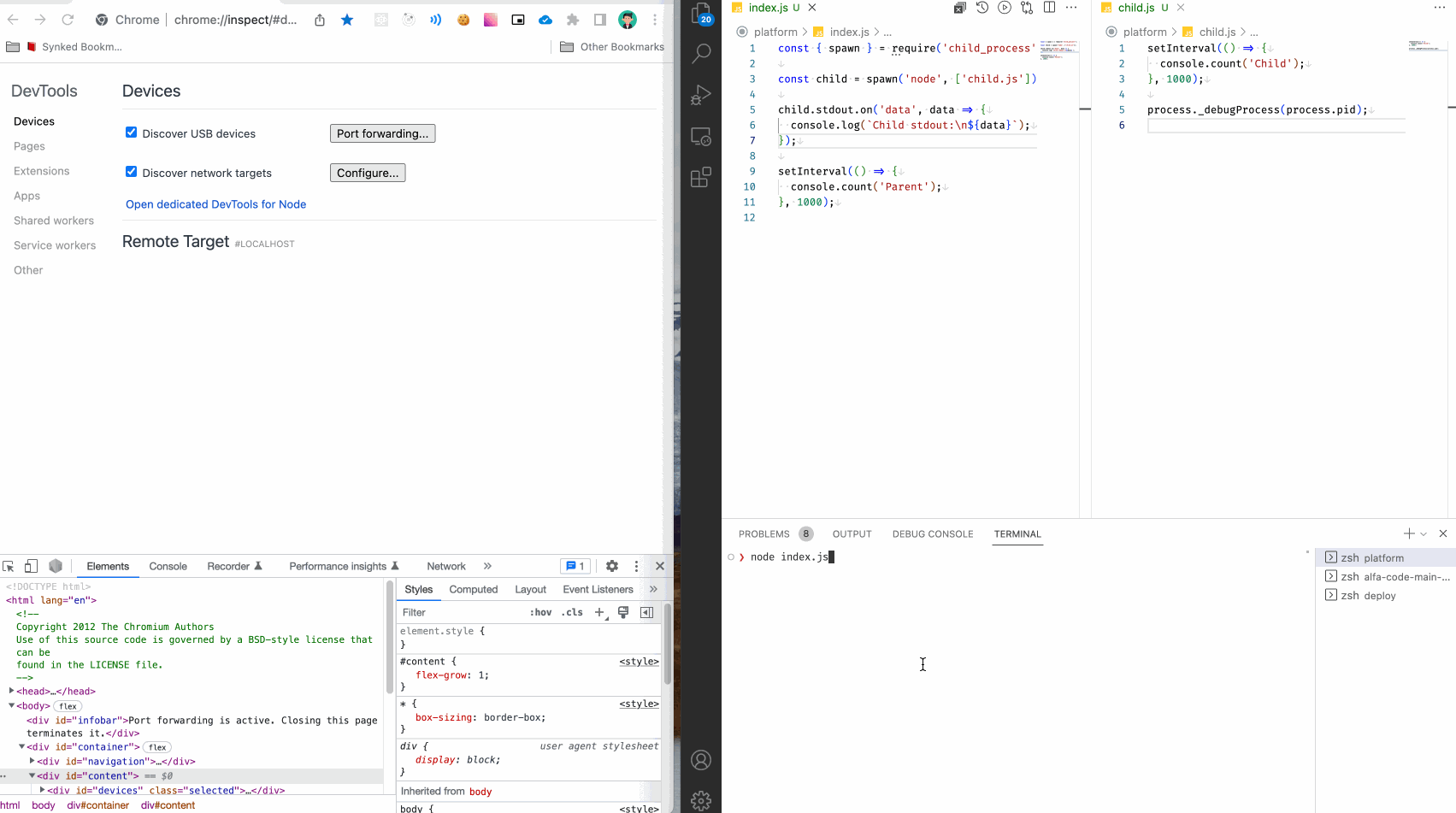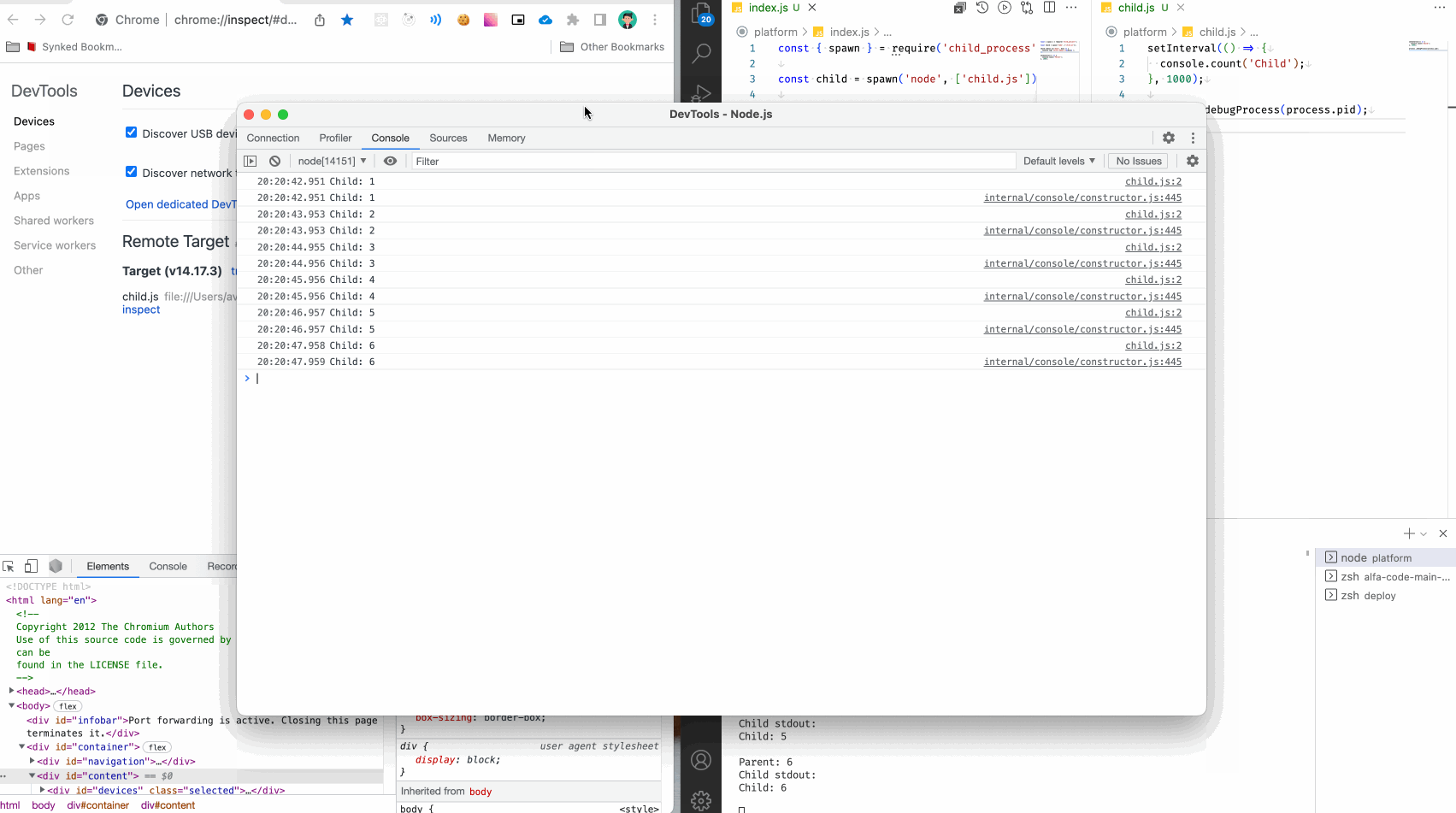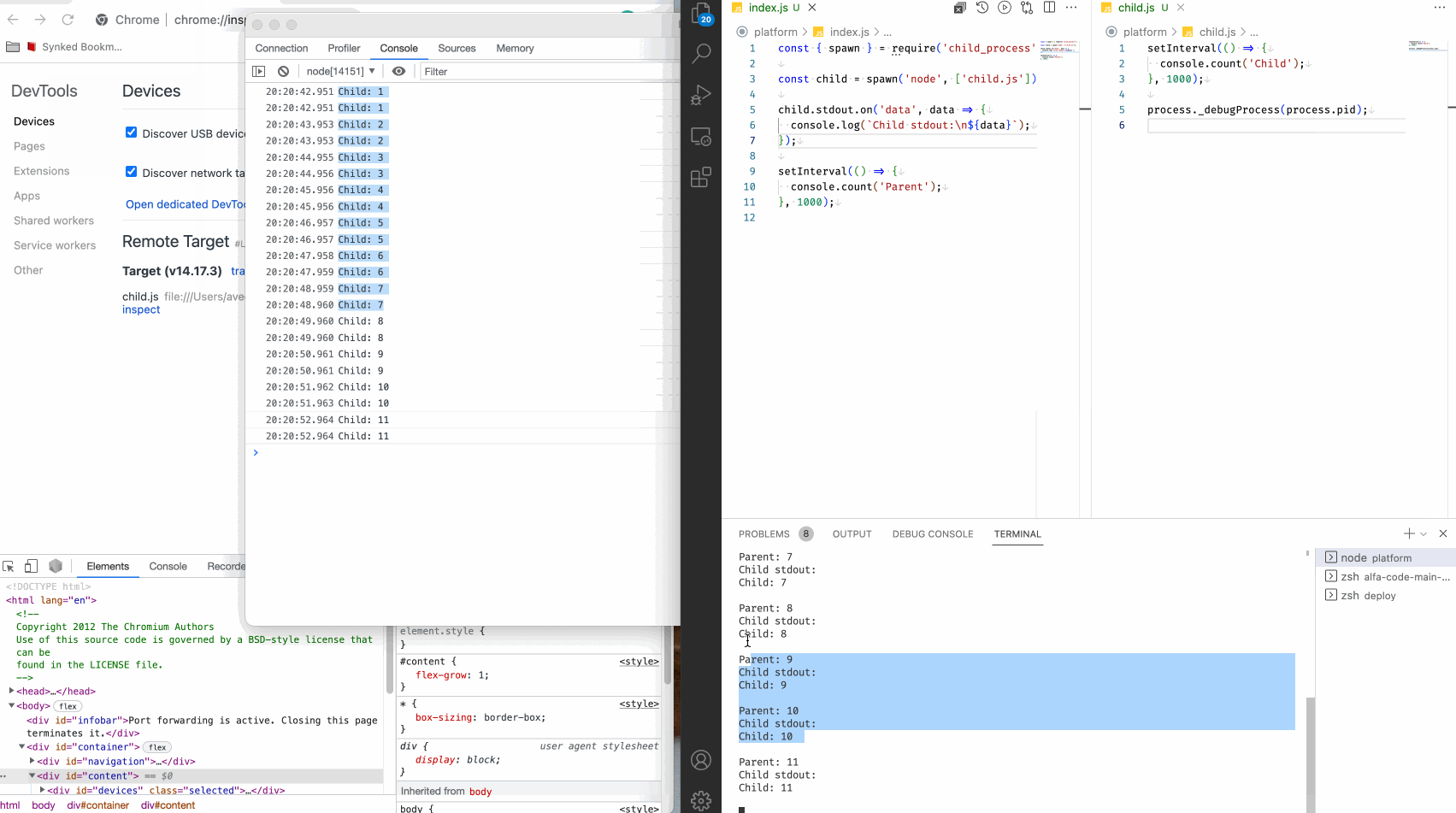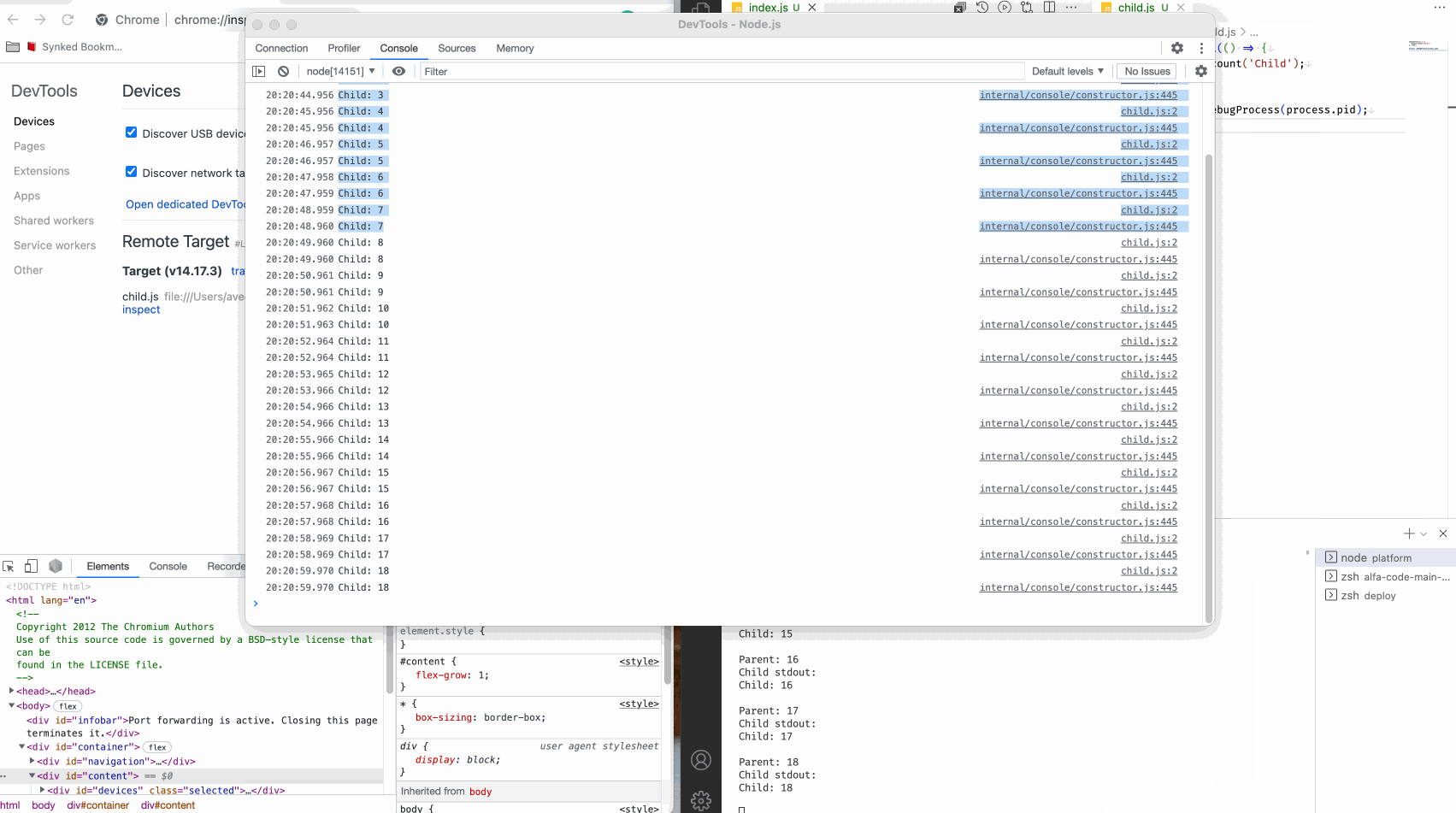
Мы видим как подключился инспектор, и подключился именно к дочернему процессу, как мы и хотели. В обычном терминале видим вывод родительского процесса, а в инспекторе вывод дочернего процесса.
Это случилось благодаря методу _debugProcess у глобального объекта process.
process - глобальная переменная на весь процесс nodeJS.
_debugProcess - метод позволяющий подключиться к инспектору на горячую.
process.pid - Уникальный идентификатор текущего процесса.
It' s awesome! Теперь можно в любом месте ваших программ вставить этот вызов и процесс nodeJS подключится к инспектору. Совсем не нужно думать, что это за процесс, сервер или сборщик. Можно даже сделать snippet для быстрой вставки команды. Я так и сделал:
Инспектор без перезагрузки процесса
В предыдущем способе все хорошо, но есть одно НО. Он требует перезагрузки процесса. Т.е. если вы вставили snippet, вам придется выполнить рестарт процесса, например сделать рестарт create-react-app, что может быть довольно затратным по времени.
Бывают случаи, когда перезагружать процесс вообще не желательно, например когда пытаешься найти баг и нужно подключить инспектор действительно "на горячую". И такой способ тоже имеется. Данный способ подойдет владельцам операционных систем UNIX Like (Такие, как MacOS или дистрибутивы Linux).
Изучим пару важных вещей: Сигнал и программу kill.
Сигнал в операционных системах семейства Unix — асинхронное уведомление процесса о каком-либо событии, один из основных способов взаимодействия между процессами. Когда сигнал послан процессу, операционная система прерывает выполнение процесса, при этом, если процесс установил собственный обработчик сигнала, операционная система запускает этот обработчик, передав ему информацию о сигнале, если процесс не установил обработчика, то выполняется обработчик по умолчанию (Выписка из вики).
На той же официальной доке про инспектор написано следующее:
Node.js также начнет прослушивать отладочные сообщения, если получит сигнал SIGUSR1. (SIGUSR1 недоступен в Windows.) В Node.js 7 и более ранних версиях это активирует устаревший API-интерфейс отладчика. В Node.js 8 и более поздних версиях он активирует Inspector API.
Вообще сигналы SIGUSR1 и SIGUSR2 это пользовательские сигналы, которые могут быть использованы для межпроцессной синхронизации и управления. Подробнее можете изучить тему этих сигналов в этом видео.
Важно понимать, что хоть мы и пишем на JS используя NodeJS, но сама нода написана на С++.
Ок, что же нам нужно сделать? Для начала определим требования.
Запущен родительский процесс, который в свою очередь запускает дочерний.
Необходимо не завершая процессы, подключить инспектор к дочернему процессу.
Первое, что нужно сделать, это найти нужный запущенный процесс. Сделать это можно с помощью следующей команды:
ps | grep node
ps - программа ps выводит все запущенные процессы.
| - передача текстового вывода в другую программу.
grep - программа фильтр, отбросит все ненужные строчки.
node - слово которое должно присутствовать в строке, по сути это регулярное выражение.
У меня получилось так:
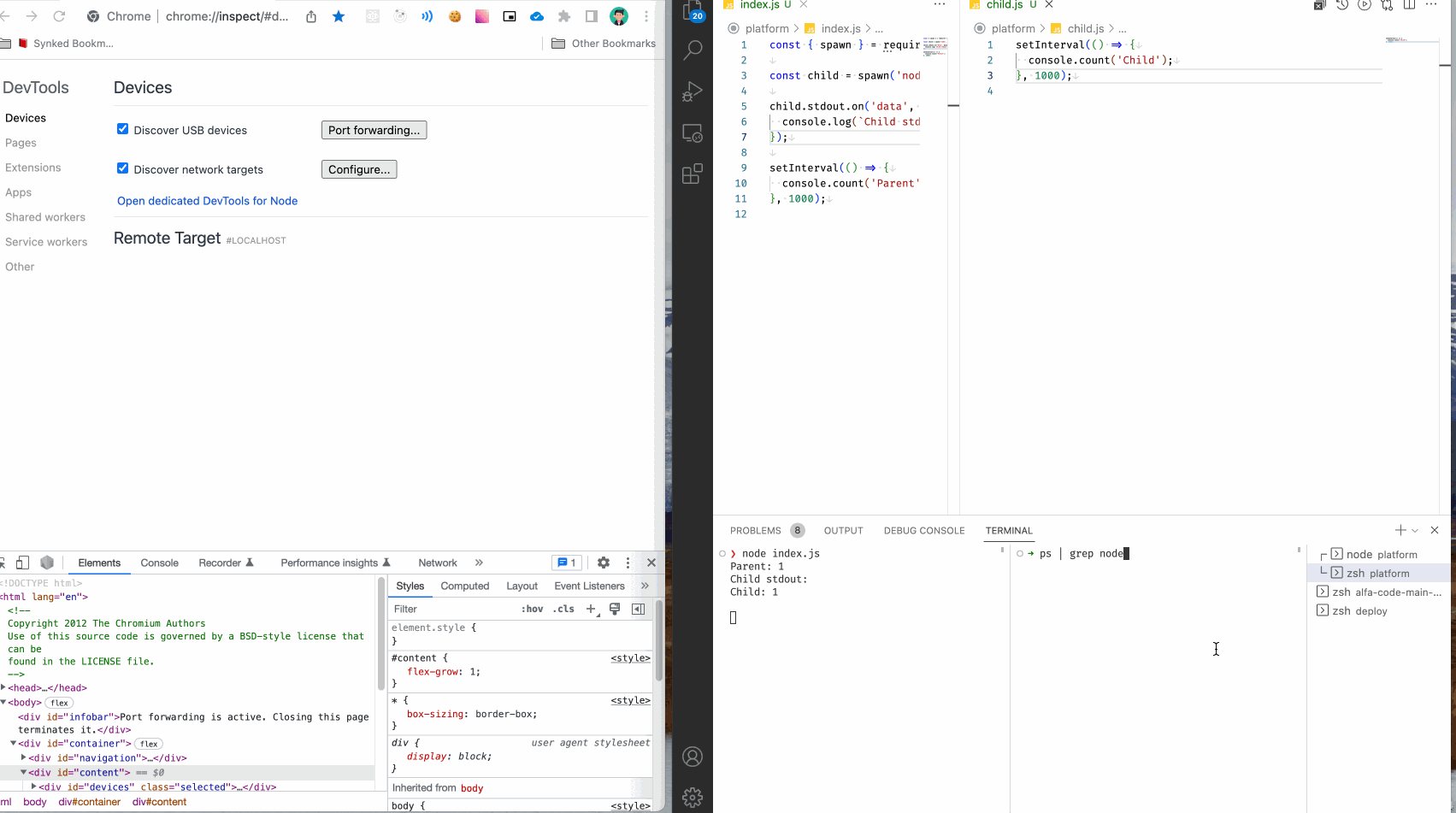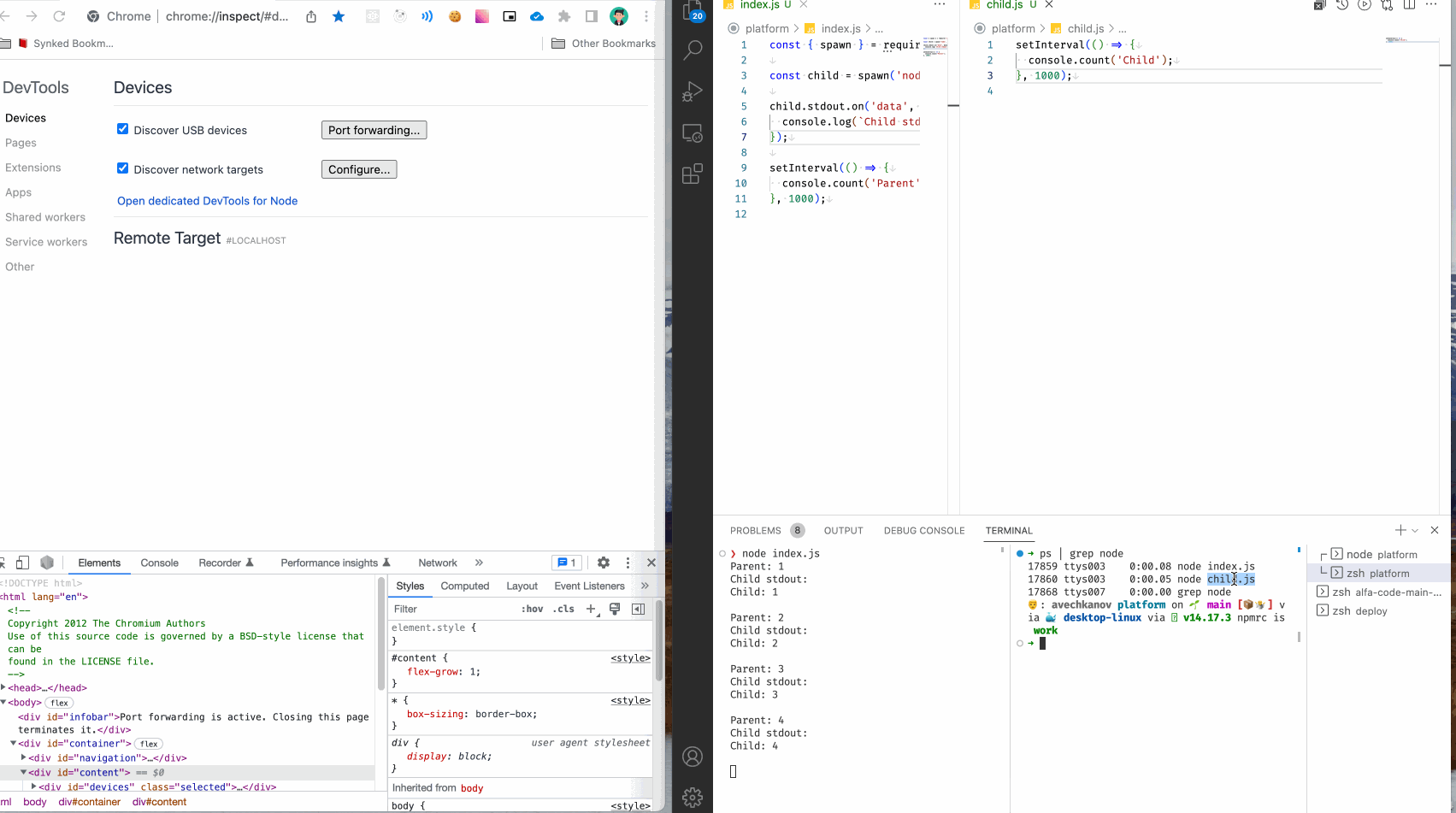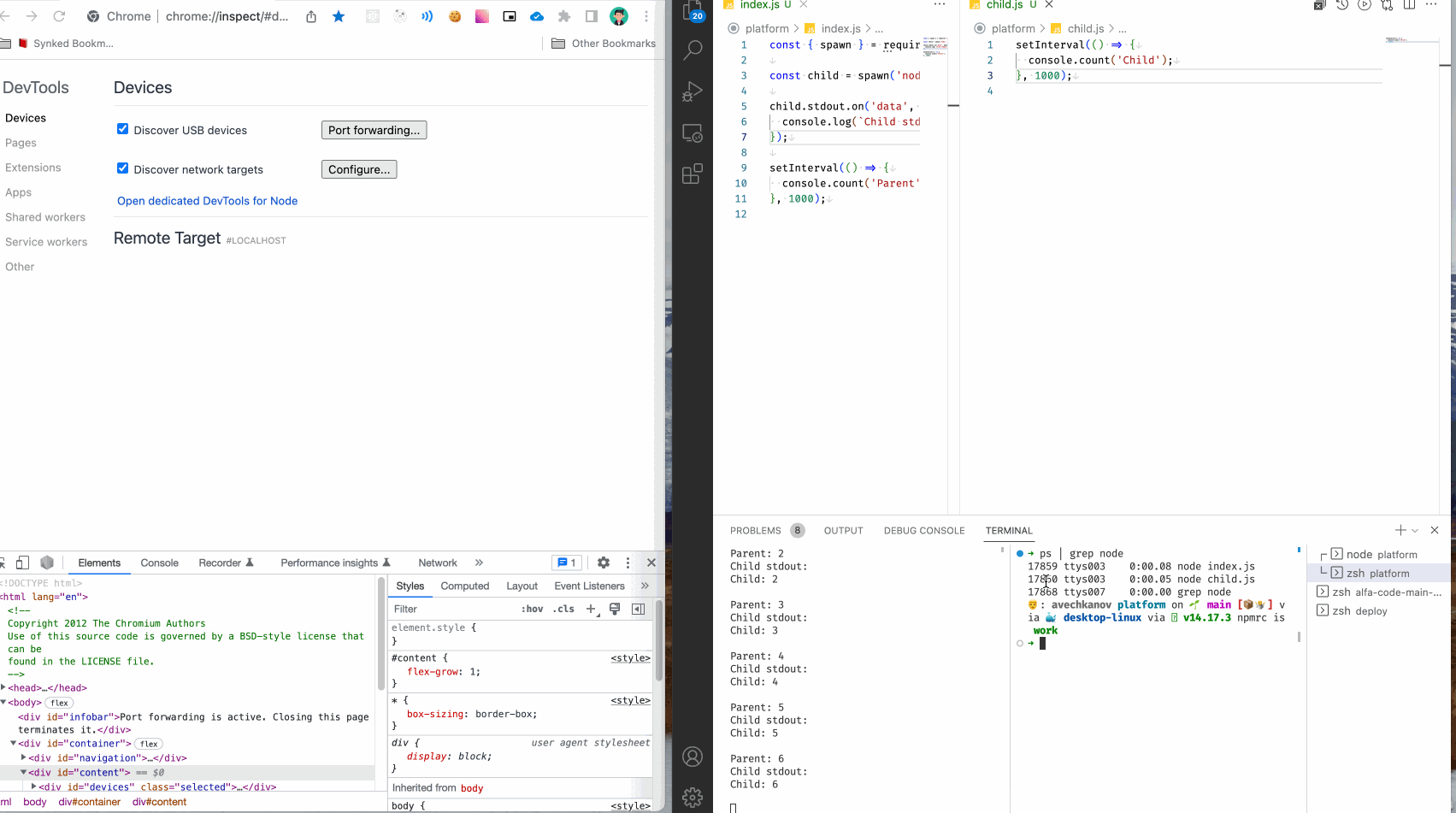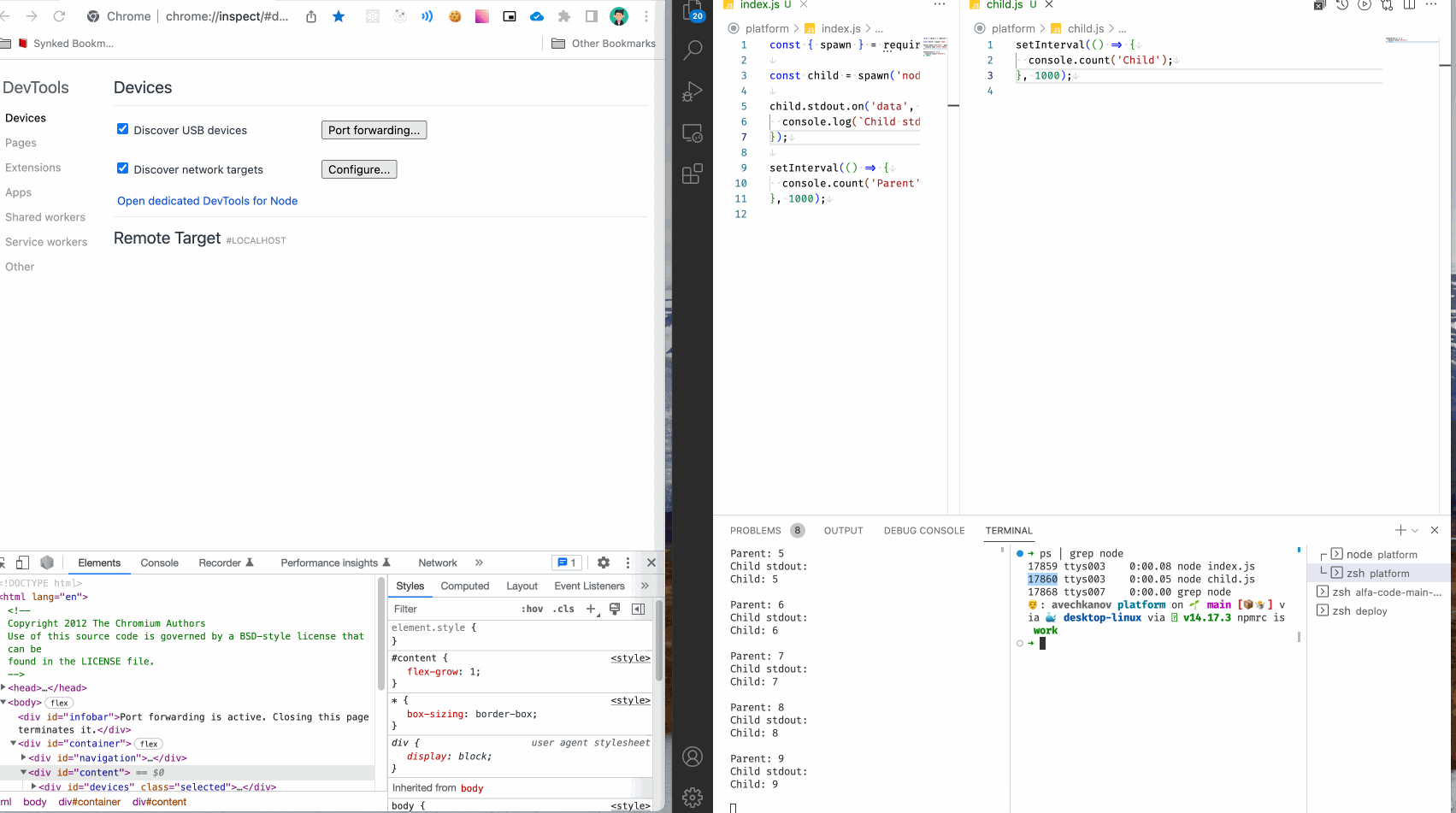
Нужный мне процесс 17860 ttys003 0:00.05 node child.js
Отлично, процесс найден, как же послать в него сигнал SIGUSR1? Для этого используется, программа kill. Обычно эта программа "убивает" процессы (на самом деле просто шлет сигналы об их завершении), но может использоваться иначе, для отсылки любых других сигналов в запущенные процессы.

Это все! Теперь достаточно просто послать нужный сигнал на нужный процесс:
kill -usr1 17860
Заключение
Я показал три способа как подключить инспектор к вашему NodeJS приложению. Наверняка найдется еще способы, но это то, чем я пользуюсь повседневно. Буду рад если вы дадите обратную связь написав комментарий. Спасибо и хорошего вам дня.
Как читать отчет о покрытии тестами, созданный с помощью Jest.
Jest поставляется с функцией создания отчетов, которые помогают нам понять покрытие тестами. Этот отчет включает покрытие выражений (statements), покрытие функций и покрытие ветвлений (braches).
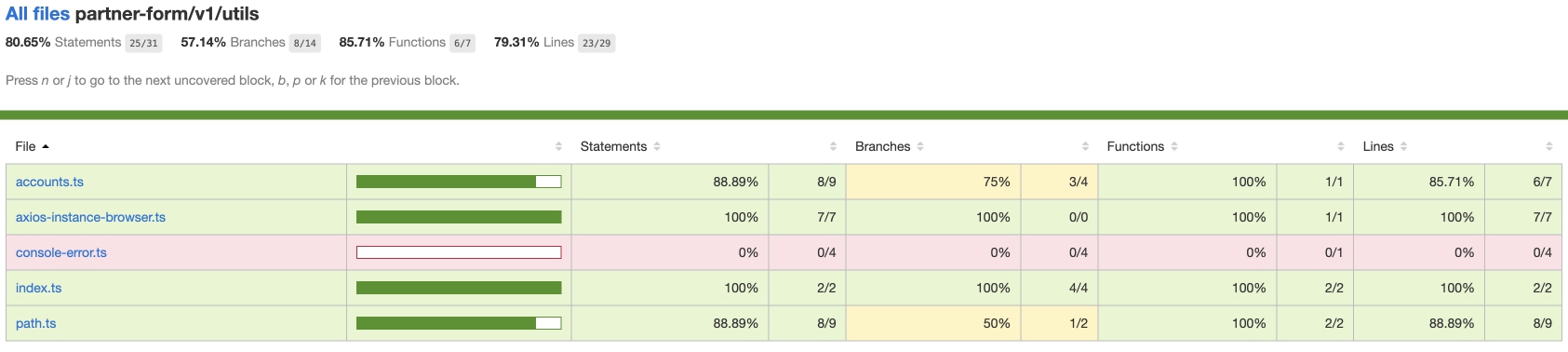
Это один из примеров отчета о тестовом покрытии, созданного для тестового приложения. В этом отчете говорится, что он имеет 84% покрытие выражений (statements), 100% ветвей и 100% функций и 84% покрытие строк в целом. Так же, возможно посмотреть отчет по каждому файлу в отдельности.
Так что же такое покрытие выражений, веток, функций, строк? Каждый параметр отвечает на свой собственный вопрос.
Function coverage (Покрытие функций) Была ли вызвана каждая функция (или подпрограмма) в программе?
Statement coverage (Покрытие выражений) Выполнено ли каждое выражение в программе?
Branch coverage (Покрытие ветвлений/веток) Выполнена ли каждая ветвь (также называемая DD-путем) каждой управляющей структуры (например, в операторах if и case)? Например, для заданного оператора if были ли выполнены как истинная, так и ложная ветви? Другими словами, было ли выполнено каждое решение в программе?
Line coverage (Покрытие строк) Была ли выполнена каждая исполняемая строка в исходном файле?
Для каждого случая указанный процент представляет собой выполненный код по сравнению с невыполненным кодом (executed code vs not-executed code), который равен дроби в процентном формате (например: 50% ветвей, 1/2).
Далее мы можем щелкнуть отдельный компонент или файл src и увидеть отчет о конкретном файле.
Например, index.js не охватывается ни одним оператором.
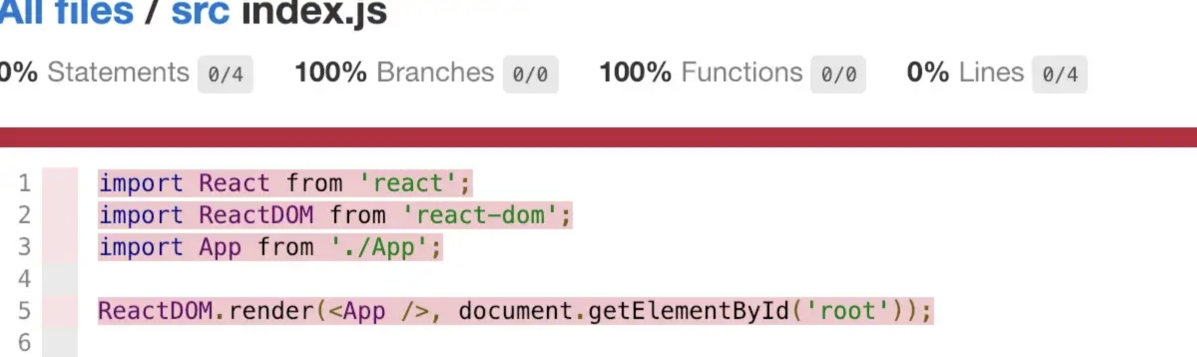
В файле отчета:
«E» означает «else path not taken» (путь Если не применен), что означает, что для помеченного оператора if/else был проверен путь if, но не else.

«I» означает «if path not taken» (путь Если не применен), что означает что блок if не был проверен.
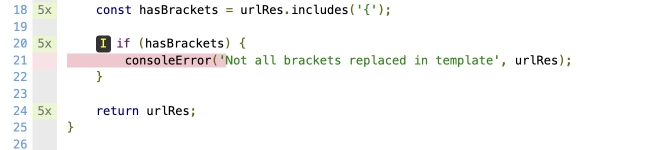
Nx в левом столбце — это количество раз, когда эта строка была выполнена.
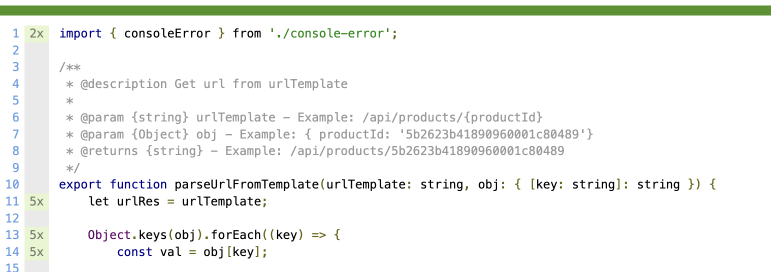
Невыполненные строки или фрагменты кода будут выделены красным цветом.
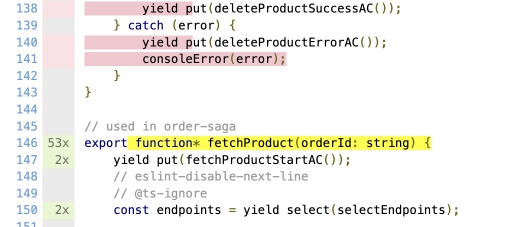
Отчет также предоставляет цветовые подсказки.
Pink: выражения не покрыты (statements not covered) и функции не покрыты (functions not covered)
Yellow: ветви не покрыты (branch is not covered).
Некоторые гайды упоминают цвет Orange (который должен обозначать непокрытые функции), но я такого не встречал. Кажется это чья-то ошибка, которая тянется из гайда в гайд.
Так же если вы направите курсор мыши на выделенные элементы, html отчет подскажет вам о чем идет речь.
Заключение
Таким образом, тестовое покрытие помогает нам понять, насколько эффективны наши тесты, охватываем ли мы весь исходный код или нет. Важно заметить, что тестовый охват не говорит на сколько хороши наши тесты - все что говорит отчет - это отрабатывал ли код или нет. Справедливости ради, замелю что в большинстве случаев этого хватает, чтобы понять какая часть бизнес логики не покрыта тестами.
Алгоритм Диффи-Хелмана: безопасный обмен ключами в интернете
Я задумал написать статью о безопасных способах передачи данных в Интернете. В первую очередь я задался вопросом "Как работает протокол SSH?". Исследования затянулись, я выяснил много нового и все оказалось совсем не так как представляют большинство. Но прежде чем изучать как работает протокол SSH, необходимо разобраться как работает алгоритм Диффи-Хелмана. Дело в том, что этот алгоритм используется и в протоколе SSH, и при настройке шифрования HTTPS, а так же в других протоколах передачи данных. Тема довольно обширная так, что я решил вынести это в отдельную статью и ссылаться на нее по необходимости.
В статье я расскажу историю алгоритма, его основной принцип работы, рассмотрим реализации данного алгоритма и попробуем реализовать алгоритм на практике.
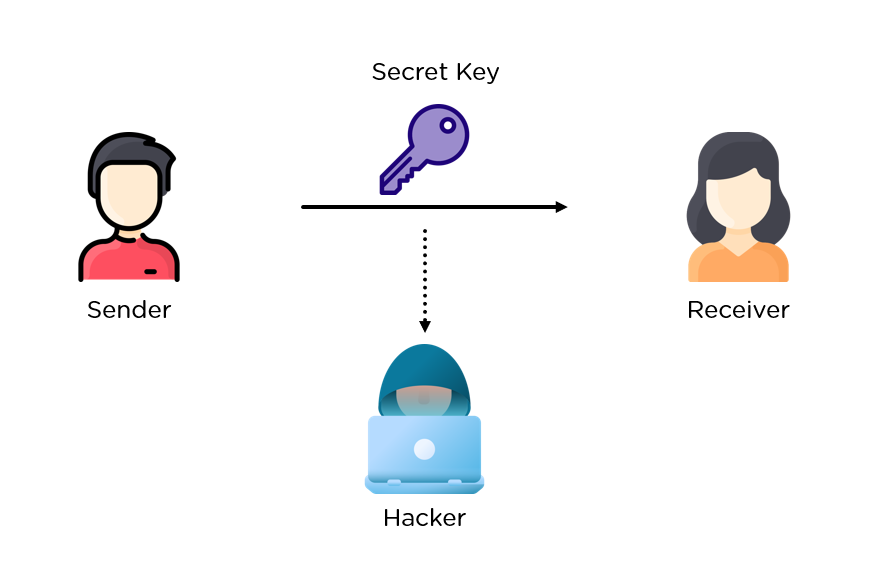
Алгоритм Диффи-Хелмана (Diffie–Hellman key exchange) - это криптографический протокол, который позволяет двум пользователям безопасно обмениваться секретными ключами через небезопасный канал связи.
Этот алгоритм (так же его называют протокол, метод) был разработан Уитфилдом Диффи и Мартином Хелманом в 1976 году. В то время они работали в лаборатории исследования компьютерных наук в Стэндфордском университете и занимались проблемой безопасного обмена ключами для шифрования данных.

Ранее для обмена ключами использовались алгоритмы, основанные на секретных ключах, которые должны были быть заранее распределены между пользователями. Но это было неудобно и небезопасно, так как ключи могли быть украдены или перехвачены злоумышленниками.
Диффи и Хелман предложили новый метод обмена ключами, который не требовал заранее распределенных секретных ключей. Они основали свой алгоритм на математической проблеме вычисления дискретного логарифма, которая считалась трудной для решения на тот момент.
Алгоритм Диффи-Хелмана (зачастую просто сокращают до аббревиатуры DH) стал первым протоколом, который позволял безопасно обмениваться ключами через небезопасный канал связи. Он стал основой для многих современных систем шифрования и используется во многих областях, включая интернет-банкинг, электронную почту и защиту данных в облаке.
Как же он работает? Давайте разбираться вместе.
Симметричное шифрование
Перед тем как разбирать сам алгоритм, давайте разберем термин Симметричное шифрование, он нам понадобится позднее.
Симметричное шифрование - это метод шифрования данных, при котором используется один и тот же ключ для шифрования и дешифрования информации. Это означает, что отправитель и получатель должны иметь доступ к одному и тому же ключу, чтобы зашифровать и расшифровать сообщение. Симметричное шифрование является быстрым и эффективным методом шифрования, но требует безопасного обмена ключами между отправителем и получателем.
Принцип работы алгоритма Диффи-Хелмана
Задача. Имеется Клиент и Сервер, которые хотят обмениваться сообщениями и не допустить утечки информации третьим лицам. Клиентом может быть как ваш браузер, так и клиент SSH, а возможно два сервера общаются между собой. Сейчас мы изучаем только алгоритм, а не конкретную его реализацию.
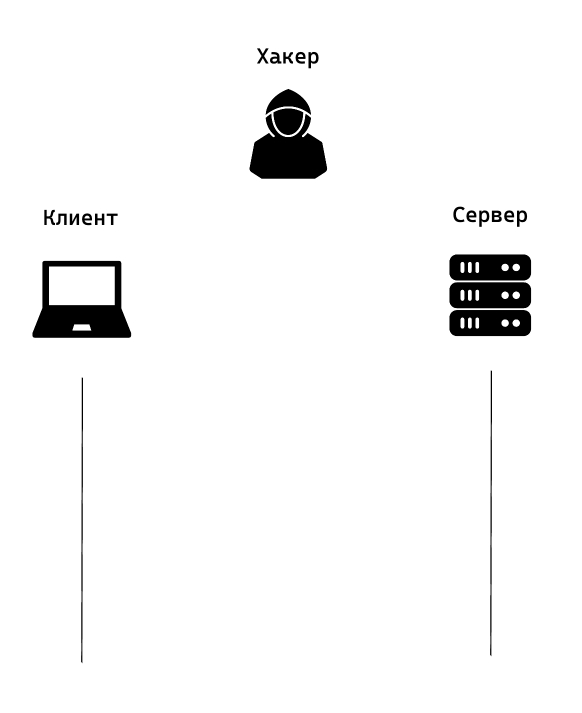
1) Этап первый
Клиент и Сервер договариваются о двух секретных числах:
p = 29, g = 3
Числа генерируются случайным образом, каждый раз новые, при каждом новом соединении. Данные числа иногда называют "публичными ключами".
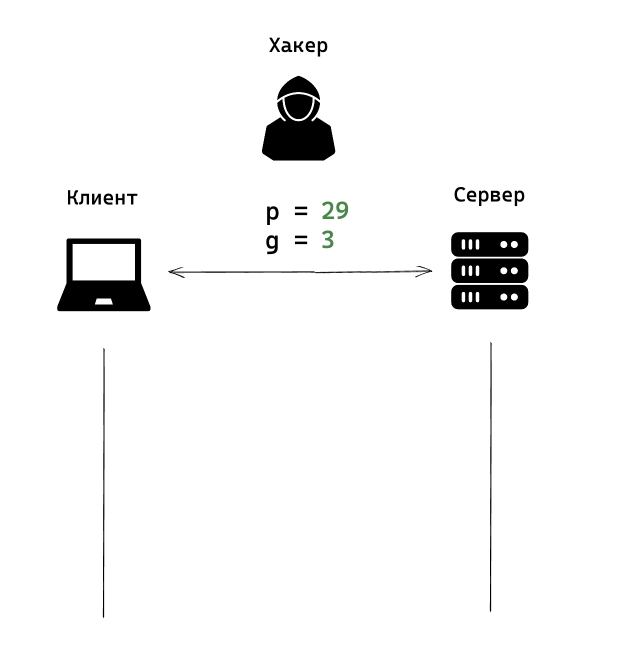
Конечно же эти цифры являются публичными и могут передаваться в открытом виде. Поэтому злоумышленник так же может получить эти значения. На изображениях числа отмеченные зеленым могут передаваться по открытому каналу связи.
2) Этап второй
Клиент и Сервер генерируют свое собственное секретное число. Эти случайные числа уже нельзя передавать по открытым каналам связи. На изображениях я отмечу их красным цветом.
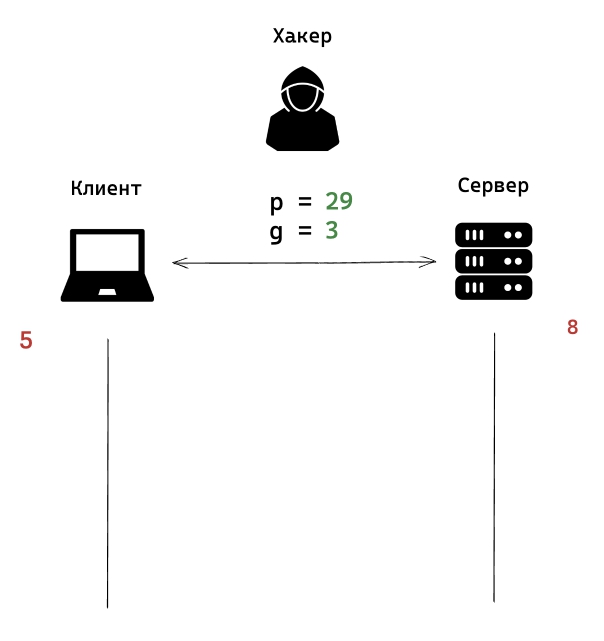
3) Этап третий
Клиент выполняет специальную операцию:
Число g, в нашем случае 3, возводит в число которое клиент выбрал случайным образом, в нашем случае это 5, и берется остаток от деления на число p, в нашем случае это 29. Получается число 11. Это число можно передавать по открытым каналам связи. Клиент передает это число на сервер.
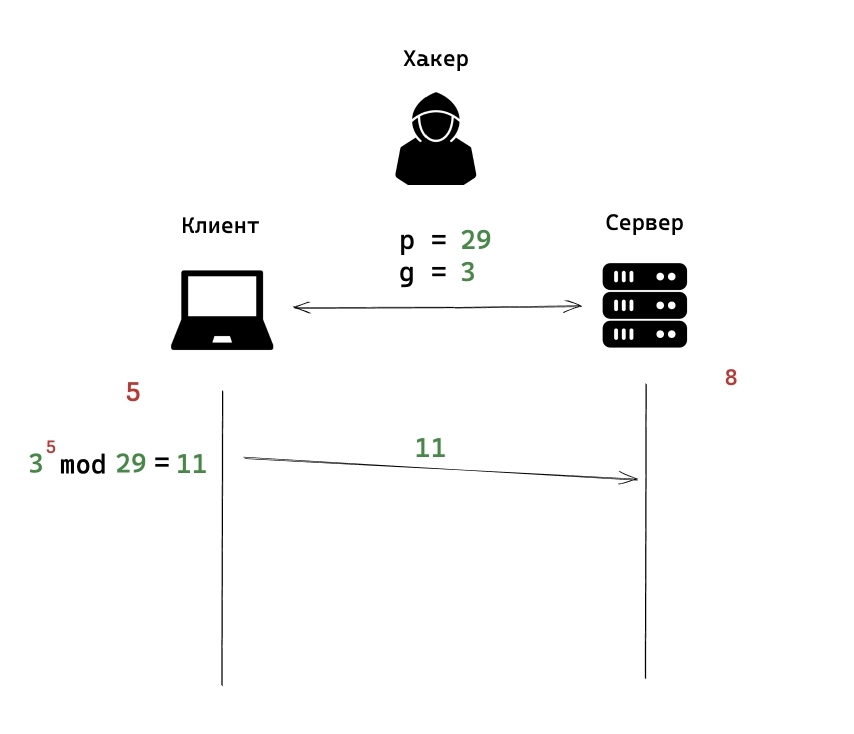
4) Этап четвертый
Сервер выполнят такой же расчет, но только со своим секретным случайным числом. В нашем случае 3 в степени 8 и берем остаток от деления на 29, равно 7.
Сервер пересылает получившиеся число клиенту.
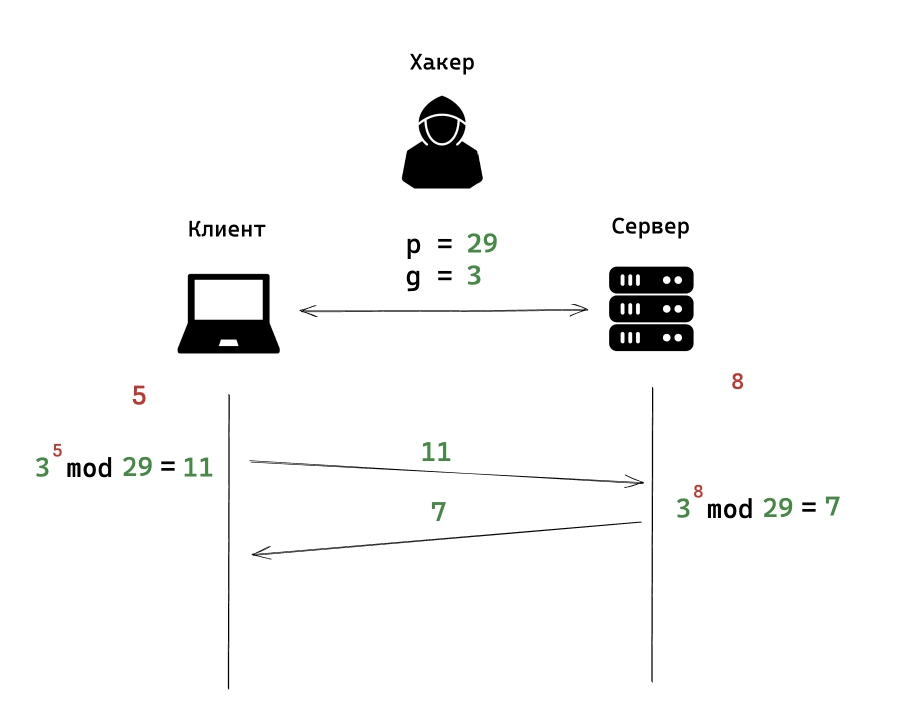
Да, эти получившиеся числа клиента и сервера может перехватить злоумышленник, но он не может узнать какие секретные числа были использованы для генерации этих публичных чисел.
5) Этап пятый - Генерация симметричного ключа
Теперь клиент и сервер снова производят похожие операции.
Клиент выполняет ту же функцию, что и выше, но только с числом полученным от сервера, в нашем случае это 7.
7 в степени 5 и остаток от деления на 29, равно 16.
Сервер производит то же самое, но с числом полученным от клиента, у нас это было число 11.
11 в степени 8 и остаток от деления на 29, равно 16.
Получившиеся число 16 и будет считаться секретным ключом для симметричного шифрования. Данный ключ (разделяемый ключ, симметричный ключ), никогда не передается по сети.
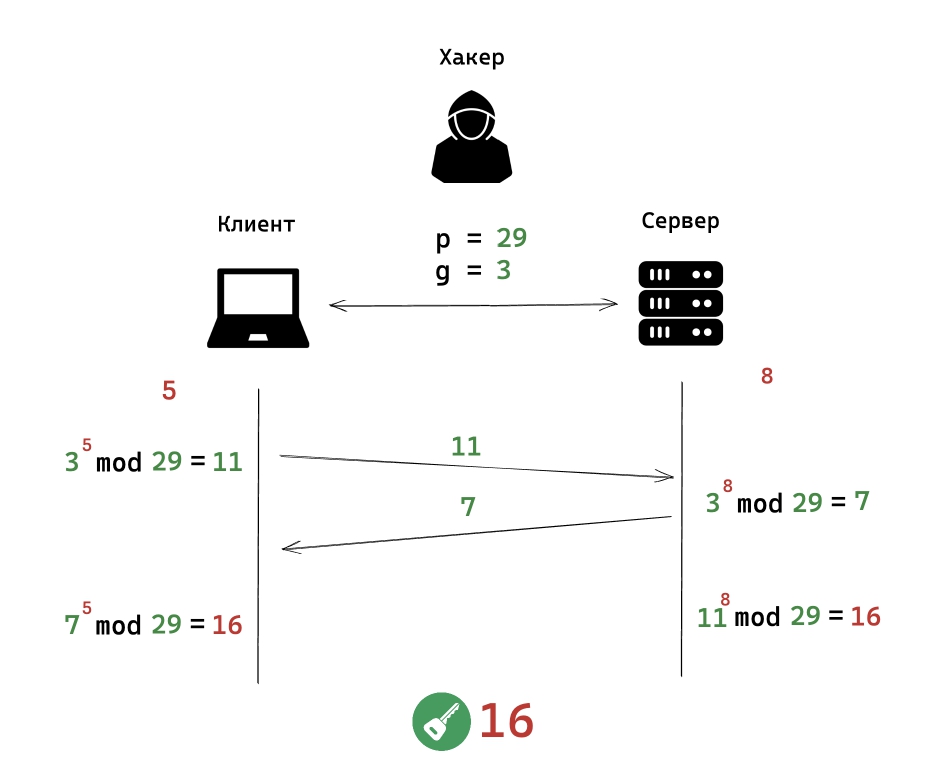
Как же получилось так, что клиент и сервер смогли вычислить одинаковое число? Все совсем не сложно. Дело в том, что и клиент и сервер выполняли одни и те же вычисления, но в разном порядке.
(3^5 mod 29)^8 mod 29 = (3^8 mod 29)^5 mod 29
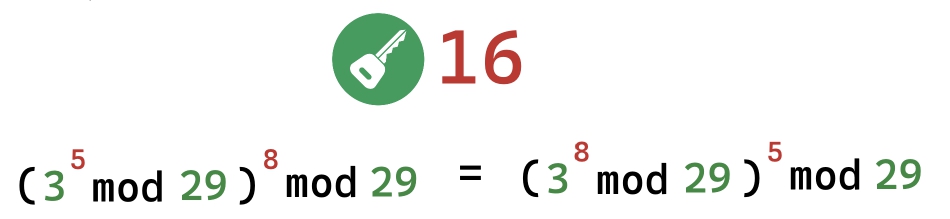
Благодаря тому, что данные вычисления являются коммутативными, клиент и сервер получают одни и те же результаты вычисления.
Название "коммутативный" происходит от латинского слова "commutare", что означает "менять местами". В математике это означает, что порядок операндов не влияет на результат операции. Например, операция сложения является коммутативной, так как порядок слагаемых можно менять местами, и результат останется тем же.
Да, хакер перехватил начальные числа p и g, так же он смог перехватить сгенерированные публичные ключи 11 и 7, но этого будет недостаточно, чтобы рассчитать общий симметричный ключ. Да, злоумышленник, все еще может выдать себя за сервер, или представиться серверу клиентом, но это уже другая история. Существуют множество способов провести аутентификацию пользователя, но к алгоритму Диффи-Хелмана это не имеет отношения. Разбираемый алгоритм служит именно для генерации секретного, симметричного ключа.
Теперь, клиент и сервер могут шифровать и расшифровывать сообщения с помощью симметричного ключа. Считаем, что безопасный канал связи настроен.
Условия работы алгоритма
Пример выше, был заведомо упрощен для понимания. В реальности условия для реализации алгоритма Диффи-Хелмана отличаются. Сгенерированные случайные числа должны отвечать определенным требованиям:
p - большое простое число минимум 2024 бита.
g - небольшое целое число (первообразный корень по модулю p).
Если эти условия соблюдаются, полученный ключ невозможно вычислить даже на современных суперкомпьютерах.
Секретные ключ клиента и сервера так же выбираются не обычной случайностью, но как именно мне выяснить не удалось. Вообще эта тема довольно сложная, оставим ее математикам.
Так же алгоритм обеспечивает Совершенную прямую секретность (Perfect forward secrecy). Если злоумышленник записал данные, которыми мы обменивались в течении соединения, а затем получил доступ к серверу, он не сможет их расшифровать. Почему? Просто, ни клиент, ни сервер не хранят симметричный ключ, он используется только в периоде соединения. Этот ключ не может быть восстановлен из переданных данных, поэтому злоумышленник не может узнать его, даже если он перехватит все сообщения, передаваемые по каналу связи. Таким образом, мы можем быть уверены в том, что в будущем никто не сможет расшифровать наши сообщения.
Так же стоит заметить, что базовый алгоритм Диффи-Хелмана редко используется на практике. Существуют различные вариации этого алгоритма и наиболее популярным является алгоритм Диффи-Хелмана на эллиптических кривых. Принцип работы довольно схож, но разберем мы его в другой раз. Для понимания принципа работы алгоритма, данного материала достаточно.
Практика
Ниже пример вышеописанного алгоритма на языке JavaScript. Поменяйте числа, и вы убедитесь, что для правильной работы алгоритма подходят не любые случайные числа.
1const p = 29
2const g = 3
3
4console.log('Публичное случайное число p: ', p);
5console.log('Публичное число g: ', g);
6
7const clientSecretNumber = 5
8const serverSecretNumber = 8
9
10console.log('Случайное секретное число клиента: ', clientSecretNumber);
11console.log('Случайное секретное число сервера: ', serverSecretNumber);
12
13function specialCalculation(g, n, p) {
14 return Math.pow(g, n) % p
15}
16
17console.log('Клиент производит вычисление...');
18const publicClientKey = specialCalculation(g, clientSecretNumber, p);
19console.log('Публичный ключ клиента: ', publicClientKey);
20
21console.log('Сервер производит вычисление...');
22const serverClientKey = specialCalculation(g, serverSecretNumber, p);
23console.log('Публичный ключ сервера: ', serverClientKey);
24
25console.log('Клиент и сервер обмениваются публичными ключами...');
26
27console.log('Клиент и сервер производят вычисление симметричного ключа...');
28
29const clientSymmetricKey = specialCalculation(serverClientKey, clientSecretNumber, p);
30console.log('Вычисленный симметричный ключ клиента: ', clientSymmetricKey);
31
32const serverSymmetricKey = specialCalculation(publicClientKey, serverSecretNumber, p);
33console.log('Вычисленный симметричный ключ сервера: ', serverSymmetricKey);
34Применение алгоритма Диффи-Хелмана.
Алгоритм Диффи-Хеллмана применяется во многих криптографических протоколах и стандартах, включая:
1. TLS/SSL: Протоколы передачи данных, обеспечивающие защищенное соединение между клиентом и сервером.
2. SSH: Протокол безопасной оболочки, используемый для безопасного удаленного доступа к серверам и обмена данными между ними.
3. IPSec: Протокол безопасности для защиты данных, передаваемых через сети, включая VPN-соединения.
Проблемы безопасности
В алгоритме Диффи-Хелмана существуют проблемы безопасности. Например, атака MITM (Man-in-the-Middle) может быть использована для перехвата и изменения передаваемых данных. Также возможна атака на основе подбора ключа, когда злоумышленник пытается угадать секретный ключ, используемый для шифрования данных. Для обеспечения безопасности протокола Диффи-Хелмана необходимо использовать надежные простые числа и другие меры защиты. Но все же данный алгоритм является одним из наиболее распространенных и широко используемых.
Заключение
Алгоритм Диффи-Хелмана является одним из самых важных алгоритмов криптографии. Он позволяет двум сторонам безопасно обмениваться секретными ключами через небезопасный канал связи. Алгоритм Диффи-Хелмана используется во многих протоколах безопасности, таких как SSL/TLS, SSH и VPN. Важно отметить, что алгоритм Диффи-Хелмана не обеспечивает аутентификацию сторон, поэтому он должен использоваться в сочетании с другими методами аутентификации, такими как цифровые сертификаты.
Да, соглашусь, что тема довольно сложная и если попробовать реализовать алгоритм самостоятельно, возникают новые вопросы и нюансы, но нам это и не нужно. Реализация уже есть. Главное уловить общий смысл. Понимание алгоритма понадобится, когда я буду писать о безопасном протоколе передачи данных SSH.
Если вам понравилась статья, не стесняйтесь поделиться ее в соц. сетях. Спасибо.
Материалы
Переносы строк CRLF и LF, Каретка и клавиша Shift
Если разработчик работает за одной разновидностью операционной системы, то он вряд ли столкнется с проблемой описанной ниже. Но как только ему приходится разрабатывать на разных операционных системах (Windows, Linux, MacOs) - вот тут могут появиться вопросы. Вопросы по поводу переносов строк в разных операционных системах.
В этой статье я отвечу на вопросы: Что такое переносы строк? Какими последовательностями символов они обозначаются, и наверное самый главный вопрос, почему с ними такая путаница?
Если совсем кратко, то при использовании любого текстового редактора, набирая в нем текст, вы делаете переносы строк. Чаще всего, эти переносы строк никак не отображаются в браузере. Для обычного пользователя, это просто перенос строки и все. Но ведь для машины любой текст это просто набор нулей и единиц. Как же тогда редактору понять где нужно сделать переносы строк, отображая очередной текст в текстовом редакторе? Правильно, нужно использовать специальную последовательность нулей и единиц, которые подскажут редактору, где нужно делать переносы. То есть нажимая клавишу Enter, вы не просто делаете перенос строки, а вставляете в ваш текст специальный символ переноса строки. Обычно в редакторах такие символы не отображаются, но их конечно же можно сделать видимыми (Чуть позже я покажу, как можно включить отображение скрытых символов в разных редакторах).
И вот в чем путаница. Исторически сложилось так, что для переноса строчек, в разных операционных системах использовались разные последовательности символов. То есть если вы написали файл в одно операционной системе, и в ней у вас отлично работают переносы строк, то может быть так, что на другой OS все склеится в одну большую строчку, так как в этой операционной системе переносы строка задаются иначе.
Честно говоря, эту проблему сложно заметить, так как различные OS научились определять форматы переносов строк и адаптируют свои программы таким образом, чтобы переносы строк отображались правильно. Но это не исключает того фактора, что внутри самого текстового файла хранятся разные последовательности символов для переноса строк. Если вы разработчик, рано или поздно вы с этим столкнетесь.
Итак, давайте разбираться.
Новая строка
Новая строка (часто называется (line ending), концом строки (end of line или EOL), следующей строкой (next line или NEL) или разрывом строки (next line)) — это специальный управляющий символ или последовательность управляющих символов в спецификациях кодировки символов, таких как ASCII, EBCDIC, Unicode и других. Много названий, но суть одна. Этот символ или последовательность символов, используется для обозначения конца строки текста и начала новой.
Таких специальных последовательностей символов наберется с десяток. На разных старых компьютерах могут использоваться совсем специфические символы для переноса строк. Но, нас это уже мало интересует. Самые распространенные из низ это последовательности LF и CRLF.
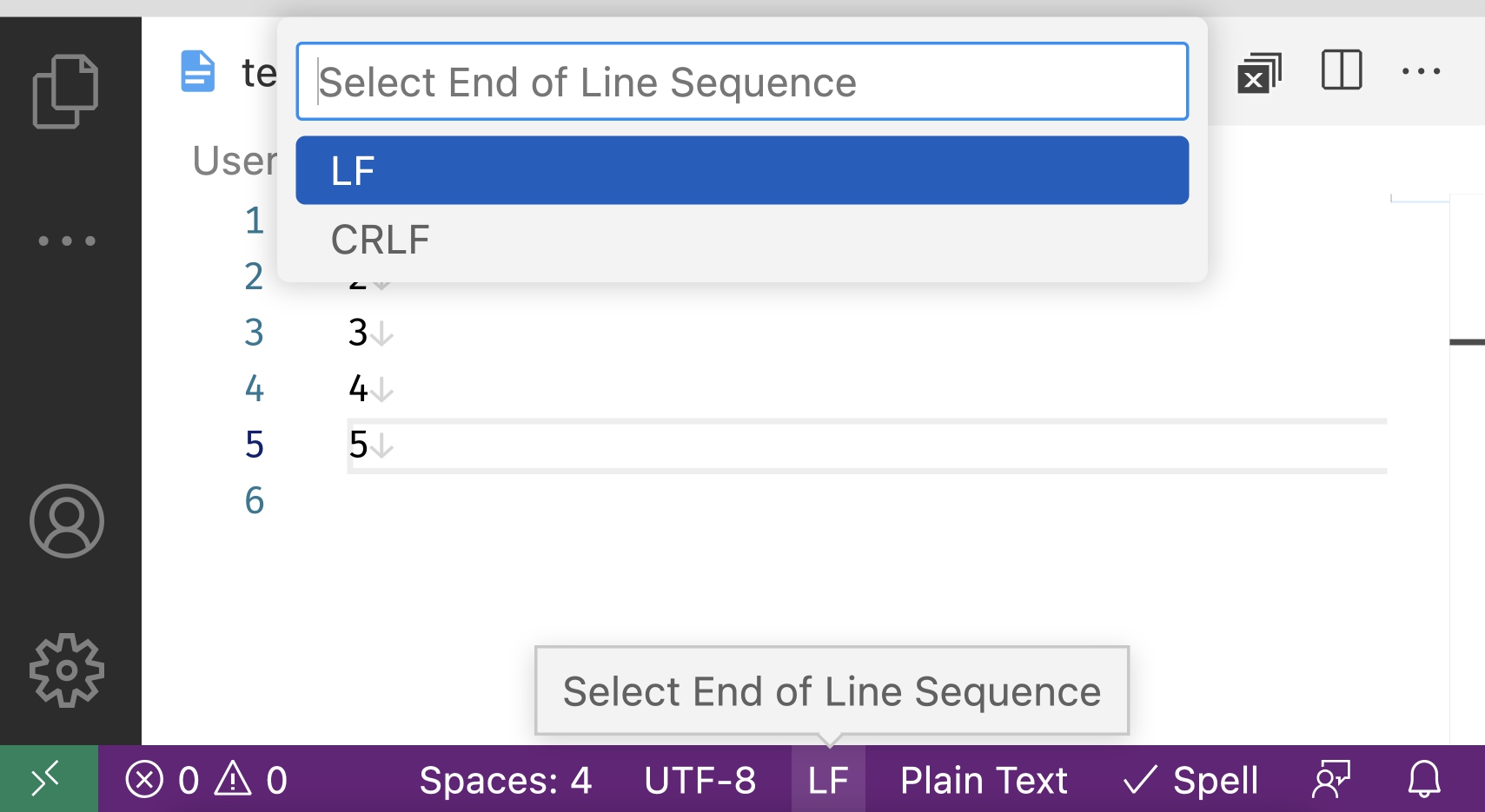
LF (0A в HEX) - расшифровывается как Line Feed или Подача Линии (нет, не кормящая линия)
CR (0D в HEX) - расшифровывается как Caret Return или возврат каретки.
Операционные системы Linux, MacOS для обозначения переноса строк используют последовательность LF.
OS Windows использует две последовательности одна за другой - CR LF.
Почему так? Будем разбираться дальше. Но перед тем как мы продолжим, обязательно посмотрите видео ниже.
Что такое Каретка, LF и CR
Отлично, теперь мы знаем откуда все пошло. Наш мигающий символ места ввода называется Каретка, а когда мы нажимаем Enter, создаем перенос строки, то есть возвращаем каретку на новую строчку.
Итого:
LF (line feed) - это виртуальная подача бумаги на одну линию.
CR (caret return) - это виртуальный сдвиг каретки, что бы мы могли начать печатать с новой строки.
Ок, но для чего все это? С печатной машинкой все понятно. Не сдвинешь каретку, не сможешь больше печатать, не подашь бумагу, будешь печатать поверх старого. То есть нужно 2 действия, но зачем это все в редакторе. Ведь в цифровом документе невозможно напечатать текст поверх предыдущего. Зачем этот сдвиг или подача бумаги? Все очень хитро.
Телетайпы
Перед тем как я затрону историю появления последовательностей переноса строк, хочу познакомить вас с телетайпами, иначе дальше можно не уловить смысл.
Телетайп (англ. teletype, TTY) — электромеханическая печатная машина, используемая для передачи между двумя абонентами текстовых сообщений по простейшему электрическому каналу (обычно по паре проводов).

Посмотрите видео ниже, чтобы лучше представлять как они работают.
Обратите внимание, что данные уже передаются в цифровом виде, но вот подача бумаги и перевод каретки все еще физические действия которые занимают довольно много времен.
История переноса строк
Следующая история из статьи на вики.
В середине 1800-х годов, задолго до появления телетайпов, операторы азбуки Морзе и телеграфисты изобрели и использовали символы азбуки Морзе для кодирования и форматирования текста с пробелами в текстовых сообщениях. В частности, в азбуке Морзе для обозначения новой строки.
Позже, в эпоху современных телетайпов, были разработаны стандартизированные управляющие коды набора символов, помогающие форматировать текст с пробелами. Кодировка ASCII была разработана одновременно Международной организацией по стандартизации (ISO) и Американской ассоциацией стандартов (ASA), последняя была организацией предшественницей Американского национального института стандартов (ANSI). В период с 1963 по 1968 год проекты стандартов ISO поддерживали использование только CR+LF или LF в качестве новой строки, в то время как проекты ASA поддерживали только CR+LF.
То есть уже в те годы, один стандарт предписывал использовать сразу две последовательности символов для переноса строки (CR+LF), а другой позволял указывать только одну (LF).
Последовательность CR + LF использовалась во многих ранних компьютерных системах, в которых использовались телетайпы - например для Teletype Model 33 ASR. Разделение новой строки на две последовательности скрывало тот факт, что печатающая головка не могла вовремя вернуться из крайнего правого положения в начало следующей строки для печати следующего символа. Любой символ, напечатанный после CR, часто печатался в виде пятна в середине страницы, в то время как печатающая головка все еще перемещала каретку обратно в первое положение. Вот что об этом писал Qualline, Steve (Автор книги по текстовому редактору VIM) «Решение состояло в том, чтобы сделать новую строку двумя символами: CR, чтобы переместить каретку в первый столбец, и LF, чтобы переместить бумагу вверх». На самом же деле, и этого было мало. Часто приходилось отправлять лишние символы — посторонние CR или NUL, — которые игнорируются телетайпом, но дают печатающей головке время для перемещения к левому полю. Многим ранним видеодисплеям также требовалось несколько символов для прокрутки дисплея.
То есть по факту, двойные последовательности для переноса строк это всего лишь "костыль" который нужен был для того, чтобы все печаталось корректно. На телетайпе, можно было выполнить физическую подачу бумаги и перенос каретки одной последовательностью управляющих символов (LF), но это приводило к тому, что печать следующей строчки начиналась еще до того, как каретка доедет до начала строки. Эту проблему решили, не исправлением телетайпов, а просто программным путем, делая задержки для телетайпа.
Приложения/редакторы должны были напрямую общаться с машиной Teletype и следовать ее соглашениям, поскольку концепция драйверов устройств, скрывающих такие детали оборудования от приложения, еще не была хорошо разработана. Поэтому текст обычно составлялся для удовлетворения потребностей телетайпов. Это соглашение использовалось в большинстве миникомпьютерных систем от DEC. CP/M (Control Program for Microcomputers — операционная система для массового рынка, созданная в 1974 году для процессоров Intel 8080/85) также использовала его для печати на тех же терминалах, что и мини-компьютеры. Оттуда MS-DOS (1981 г.) приняла CR + LF для совместимости между операционными системами, и это соглашение было унаследовано более поздней операционной системой Microsoft Windows.
Операционная система Multics начала разрабатываться в 1964 году и использовала только LF в качестве новой строки. Multics использовала драйвер устройства для преобразования этого символа в любую последовательность, необходимую принтеру (включая дополнительные символы заполнения), а один байт был более удобен для программирования. То, что кажется более очевидным выбором было — не использовать CR, поскольку CR предоставлял полезную функцию наложения одной строки на другую для создания эффектов полужирного шрифта, подчеркивания и зачеркивания. Возможно, что более важно, использование только LF в качестве разделителя строки уже было включено в проекты возможного стандарта ISO/IEC 646. Unix последовала практике Multics, а более поздние Unix-подобные системы последовали за Unix. Это создавало конфликты между Windows и Unix-подобными операционными системами, из-за чего файлы, созданные в одной операционной системе, не могли быть правильно отформатированы или интерпретированы другой операционной системой.
Понятия возврата каретки (CR) и перевода строки (LF) тесно связаны между собой и могут рассматриваться как по отдельности, так и вместе. В физических носителях пишущих машинок и принтеров две оси движения, «вниз» и «поперек», необходимы для создания новой строки на странице. Хотя конструкция машины (пишущей машинки или принтера) должна учитывать их по отдельности, абстрактная логика программного обеспечения может объединить их вместе как одно событие. Вот почему новая строка в кодировке символов может быть определена как CR и LF, объединенные в одну (обычно называемую CR+LF или CRLF).
Заключение
Мы разобрались в истории и теперь знаем откуда такая путаница с переносами строк. По сути - все из-за бага с телетайпами и костыля в виде символа перевода каретки который помог решить эту проблему. Вывод который я могу сделать из этой истории: Пишите код сразу правильно, иначе костыль сделанный на время останется с вами навсегда. В следующей статье я опиши способы автоматической замены и приведения символов переносов строк к одному варианту. Буду рад если оставите комментарий.
На десерт
Ну, и на десерт, видео от автора про пишущую машинку, о том как работает клавиша shift на печатных машинках.
Ссылки на материалы:
CRLF vs. LF: Normalizing Line Endings in Git
Newline
Кеширование в веб приложениях. Часть 2. Заголовок Expires.
В предыдущей статье я рассказал (точнее начал рассказывать) про кеширование на клиентской стороне. И в частности мы разобрали заголовок Cache-Control.
По правде говоря я не с того начал. Начать стоило с заголовка Expires. Заголовок Expires появился раньше и до сих пор используется некоторыми веб-сайтами. В данной статье я расскажу историю этого заголовка и отличия от Cache-Control

Заголовок Expires появился в HTTP 1.0 в 1996 году. Он был предназначен для указания даты и времени, после которых ресурс считается устаревшим и должен быть повторно загружен с сервера. Это позволяло уменьшить нагрузку на сервер и ускорить загрузку страницы, так как браузер мог использовать закэшированный ресурс, если он еще не устарел. Однако, в HTTP 1.1 был введен более гибкий заголовок Cache-Control (его мы разбирали в прошлой статье), который позволяет более точно управлять кэшированием ресурсов. Несмотря на это, заголовок Expires все еще поддерживается и используется во всех новых версиях протокола HTTP для обратной совместимости.
Заголовок выглядит как Expires: HTTP-date где HTTP-date один из 3-х форматов даты в формате GMT. Но это уже детали.
Отлично. Давайте приступим к практике. Создадим сервер использую NodeJS и Hapi (Вы можете использовать любой фреймворк). Так же сразу добавим отправку на клиента заголовок Expires (34-я строчка):
response.header('Expires', 'Sat, 1 Oct 2050 01:00:00 GMT');
1const Hapi = require('@hapi/hapi');
2
3// Создаем сервер на порту 3000
4const server = Hapi.server({
5 host: 'localhost',
6 port: 3000
7});
8
9// При запуске сервера создаем ложную дату последней модификации файла
10const lastModified = new Date();
11
12// Создаем несколько простых роутов для теста
13server.route({
14 method: 'GET',
15 // Тут заложим роут / и /n где n не обязательный, любой, параметр
16 path: '/{n?}',
17 handler: function (request, h) {
18 // Генерируем случайное число, по нему мы визуально поймем, поменялся ли контент на веб странице.
19 const randomNum = Math.random();
20 // Выводим число в консоль сервера, просто чтобы понять, происходил ли вызов handler
21 console.log('randomNum: ', randomNum);
22
23 // Создаем HTML контент с двумя перекрестными ссылками.
24 const content = `
25 <p>${ Math.random(randomNum) }</p>
26 <a href="/"> Главная страница </a>
27 <br/>
28 <a href="/2"> Страница 2 </a>
29 `
30
31 // Создаем объект ответа.
32 const response = h.response(content);
33
34 // Добавляем заголовок Expires.
35 response.header('Expires', 'Sat, 1 Oct 2050 01:00:00 GMT');
36
37 return response;
38 }
39});
40
41server.route({
42 method: 'GET',
43 path:'/hello',
44 handler: function (request, h) {
45 const content = 'Это страница hello.';
46
47 // Создаем объект ответа.
48 const response = h.response(content);
49
50 // Добавляем заголовок Expires.
51 response.header('Expires', 'Sat, 1 Oct 2050 01:00:00 GMT');
52
53 return response;
54 }
55});Запустим сервис и проверим в Postman.
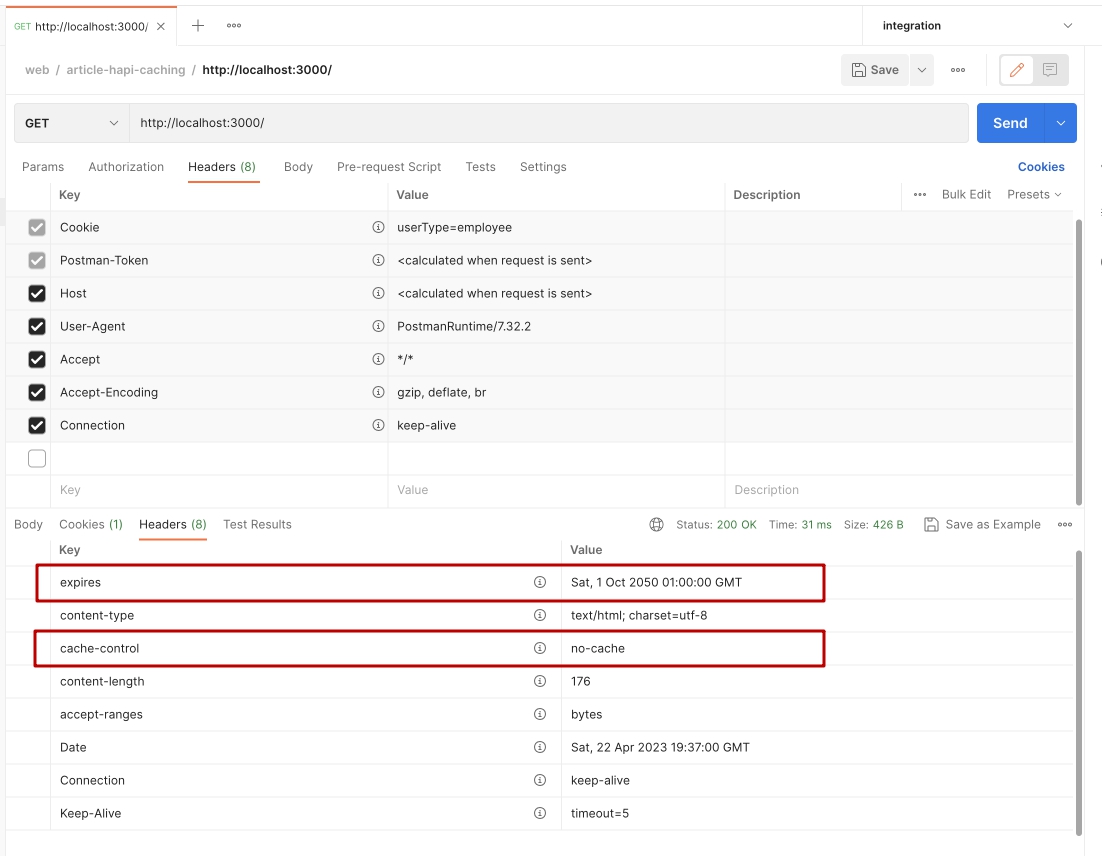
В ответе от сервера видим одновременно два заголовка: Expires и Cache-Control
Дело в том, что большинство серверов по умолчанию уже используют некоторые политики кеширования и в частности сервер HapiJS по умолчанию отправляет заголовок Cache-Control со значением no-cache. В случае когда клиент получает два заголовка, решение всегда в пользу более нового - то есть старый Expires учитываться не будет. Нам такой вариант не подходит. Отключим стандартное поведение сервера для роутов специальной опцией.
1options: {
2 cache: false // отключение кэширования
3}Должен получиться следующий код:
1const Hapi = require('@hapi/hapi');
2
3// Создаем сервер на порту 3000
4const server = Hapi.server({
5 host: 'localhost',
6 port: 3000
7});
8
9// При запуске сервера создаем ложную дату последней модификации файла
10const lastModified = new Date();
11
12// Создаем несколько простых роутов для теста
13server.route({
14 method: 'GET',
15 // Тут заложим роут / и /n где n не обязательный, любой, параметр
16 path: '/{n?}',
17 handler: function (request, h) {
18 // Генерируем случайное число, по нему мы визуально поймем, поменялся ли контент на веб странице.
19 const randomNum = Math.random();
20 // Выводим число в консоль сервера, просто чтобы понять, происходил ли вызов handler
21 console.log('randomNum: ', randomNum);
22
23 // Создаем HTML контент с двумя перекрестными ссылками.
24 const content = `
25 <p>${ Math.random(randomNum) }</p>
26 <a href="/"> Главная страница </a>
27 <br/>
28 <a href="/2"> Страница 2 </a>
29 `
30
31 // Создаем объект ответа.
32 const response = h.response(content);
33
34 // Добавляем заголовок последней модификации ресурса.
35 response.header('Expires', 'Sat, 1 Oct 2050 01:00:00 GMT');
36
37 return response;
38 },
39 options: {
40 cache: false // отключение кэширования
41 }
42});
43
44server.route({
45 method: 'GET',
46 path:'/hello',
47 handler: function (request, h) {
48 const content = 'Это страница hello.';
49
50 // Создаем объект ответа.
51 const response = h.response(content);
52
53 // Добавляем заголовок Expires.
54 response.header('Expires', 'Sat, 1 Oct 2050 01:00:00 GMT');
55
56 return response;
57 },
58 options: {
59 cache: false // отключение кэширования
60 }
61});
62
63// Запускаем сервер
64async function start() {
65
66 try {
67 await server.start();
68 }
69 catch (err) {
70 console.log(err);
71 process.exit(1);
72 }
73
74 console.log('Сервер запущен по адресу:', server.info.uri);
75}
76
77start();Перезапускаем сервер и проверяем.
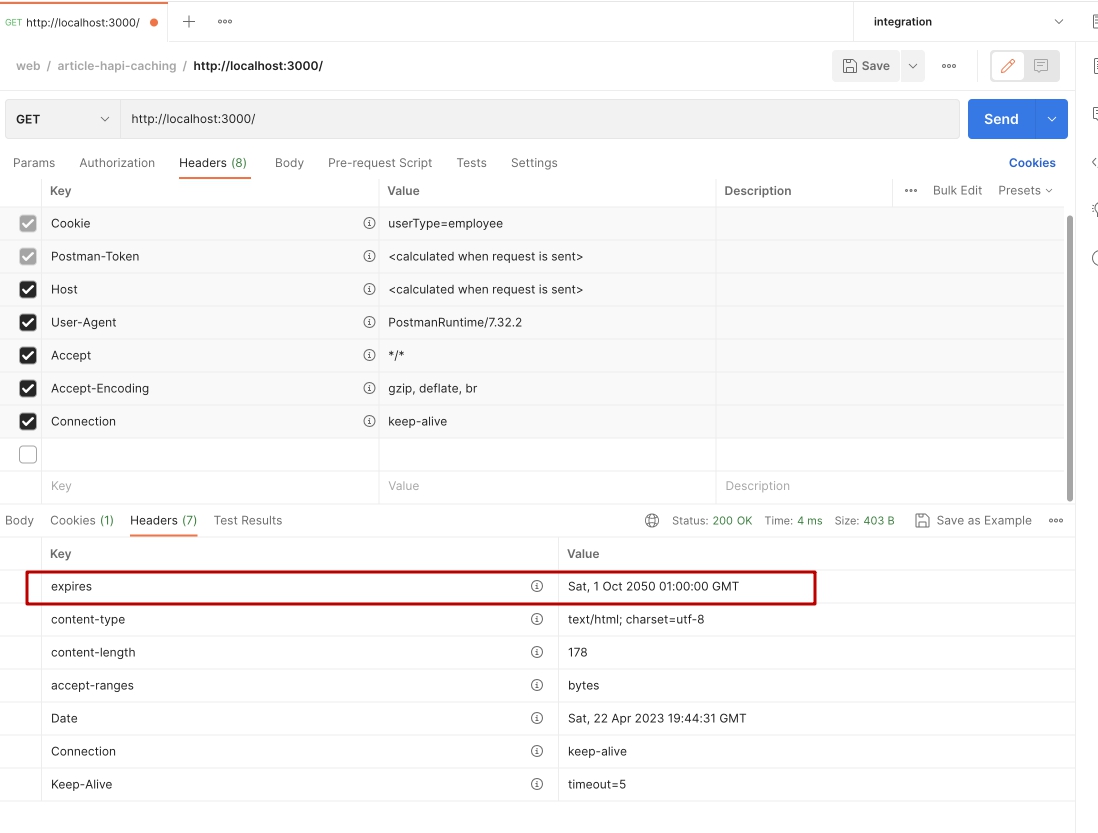
Отлично. Теперь видим что заголовок всего один и тот что нам нужен. Напомню, что запросы в таких программах как Postman или прямая перезагрузка страницы всегда будет делать запрос на сервер, проверять не изменился ли файл на сервере.
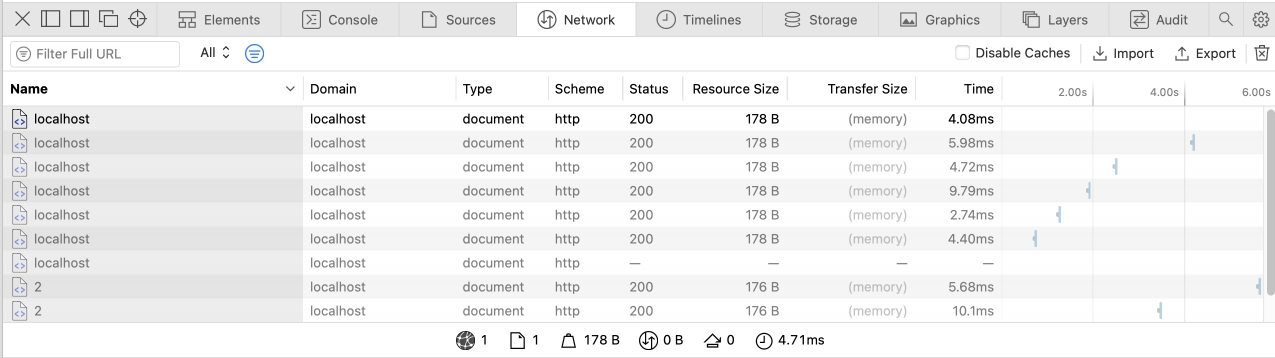
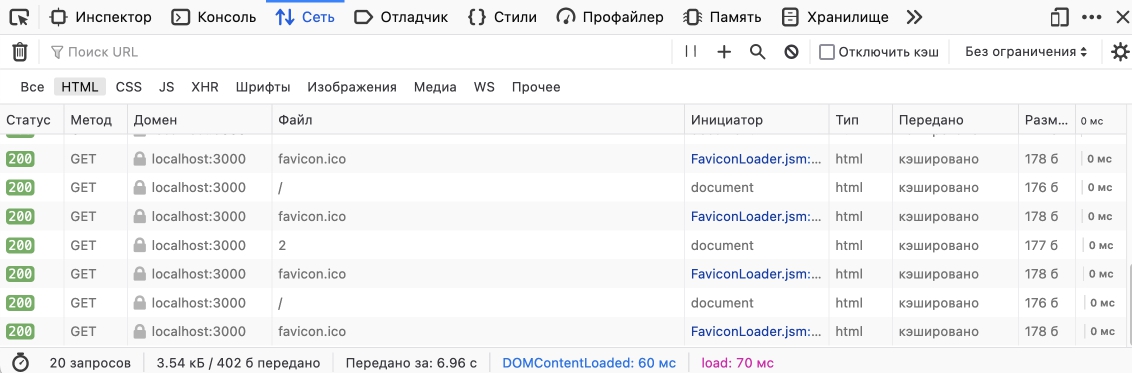
Как раз, для того чтобы проверить, работает ли заголовок Expires мы делали несколько роутов. Откроем адрес htttps://localhost:3000/ в браузере, так же откроем DevTools и попробуем перейти по ссылкам.
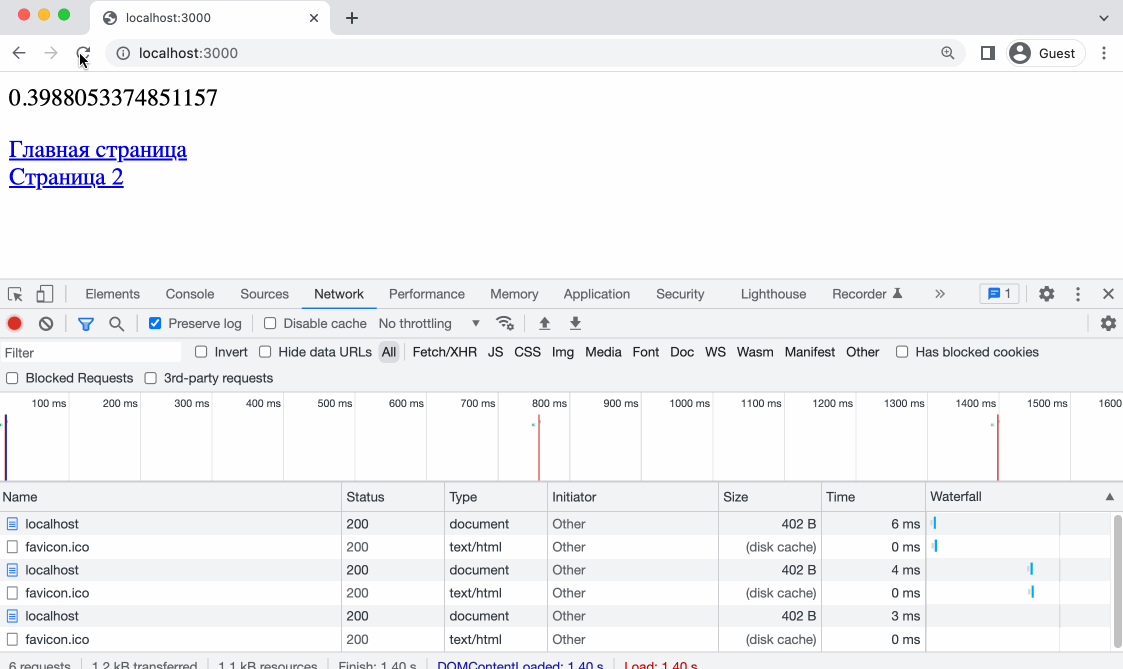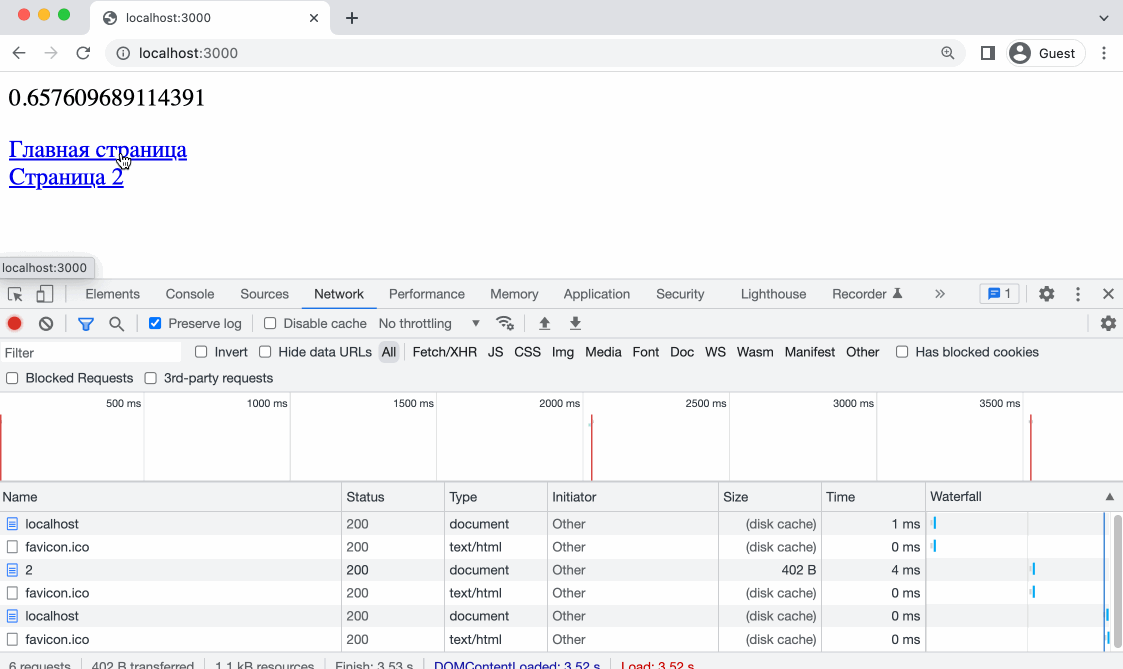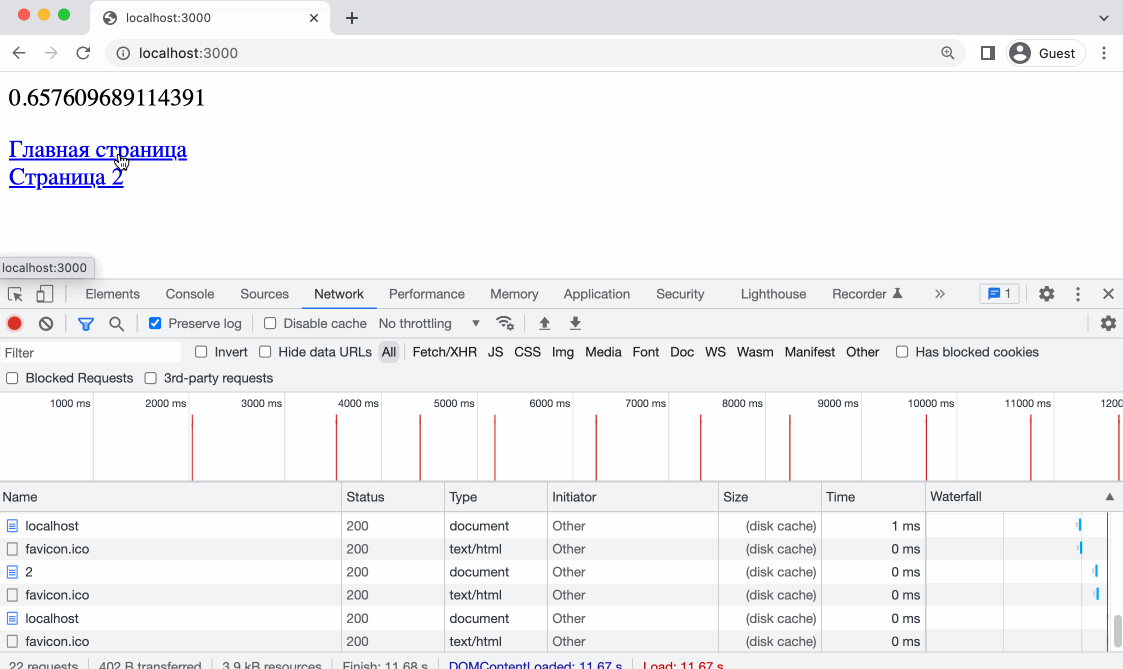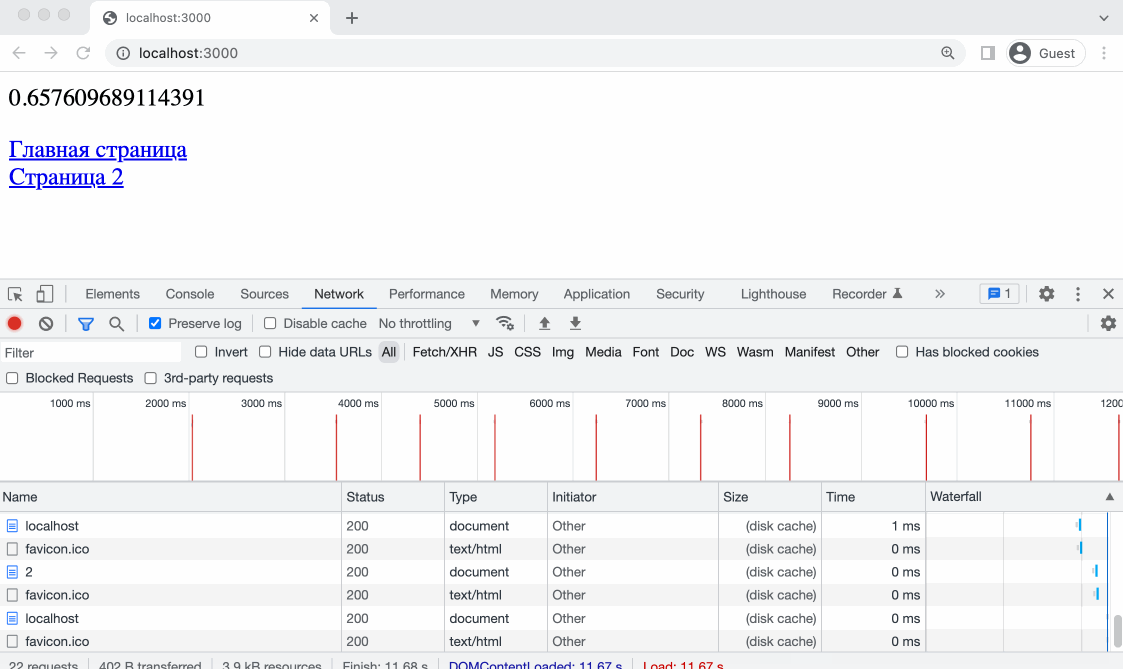
Контент кешируется - отлично! Обратите внимание - при прямой перезагрузке страницы браузер делает принудительный запрос контента, но при кликах по ссылкам наше случайное число больше не меняется, а это значит что контент взят из кеша и никакие запросы на сервер не выполнялись. Так же это можно понять по колонке Size в DevTools - вы увидите надпись Disk Cache или Memory Cache.
Memory Cache - это кэш, который хранится в оперативной памяти браузера. Кэш в оперативной памяти быстрее, чем кэш на диске, поэтому он используется для хранения небольших ресурсов, таких как изображения, стили и скрипты.
Disk Cache - это кэш, который хранится на жестком диске компьютера. Кэш на диске медленнее, чем кэш в оперативной памяти, но он может хранить большие объемы данных, такие как видео и аудио файлы.
Когда вы открываете веб страницу, браузер загружает ресурсы и кэширует их в Memory Cache или Disk Cache, в зависимости от того, какой тип кэша лучше подходит для каждого ресурса. Разные браузеры имеют собственные политики занесения данных в кеш.
На этом можно было бы и закончить, но как всегда дьявол кроется в деталях.
Как мы знаем, Cache-Control используется для более гибкой настройки кеширования. Если заголовок Cache-Control указывает на запрет кэширования, то Expires не имеет смысла. Но что произойдет если оставить заголовок Cache-Control, но указать в его значениях, к примеру, только опцию публичности? Для этого, давайте вручную, добавим это заголовок.
1// Добавляем в заголовок только одну опцию и ни слова про время жизни кеша.
2response.header('Cache-Control', 'public');Не забудьте добавить эти заголовки в оба роута.
Перезагружаем сервер, проверяем. И все работает. Старинца загружена из кеша.
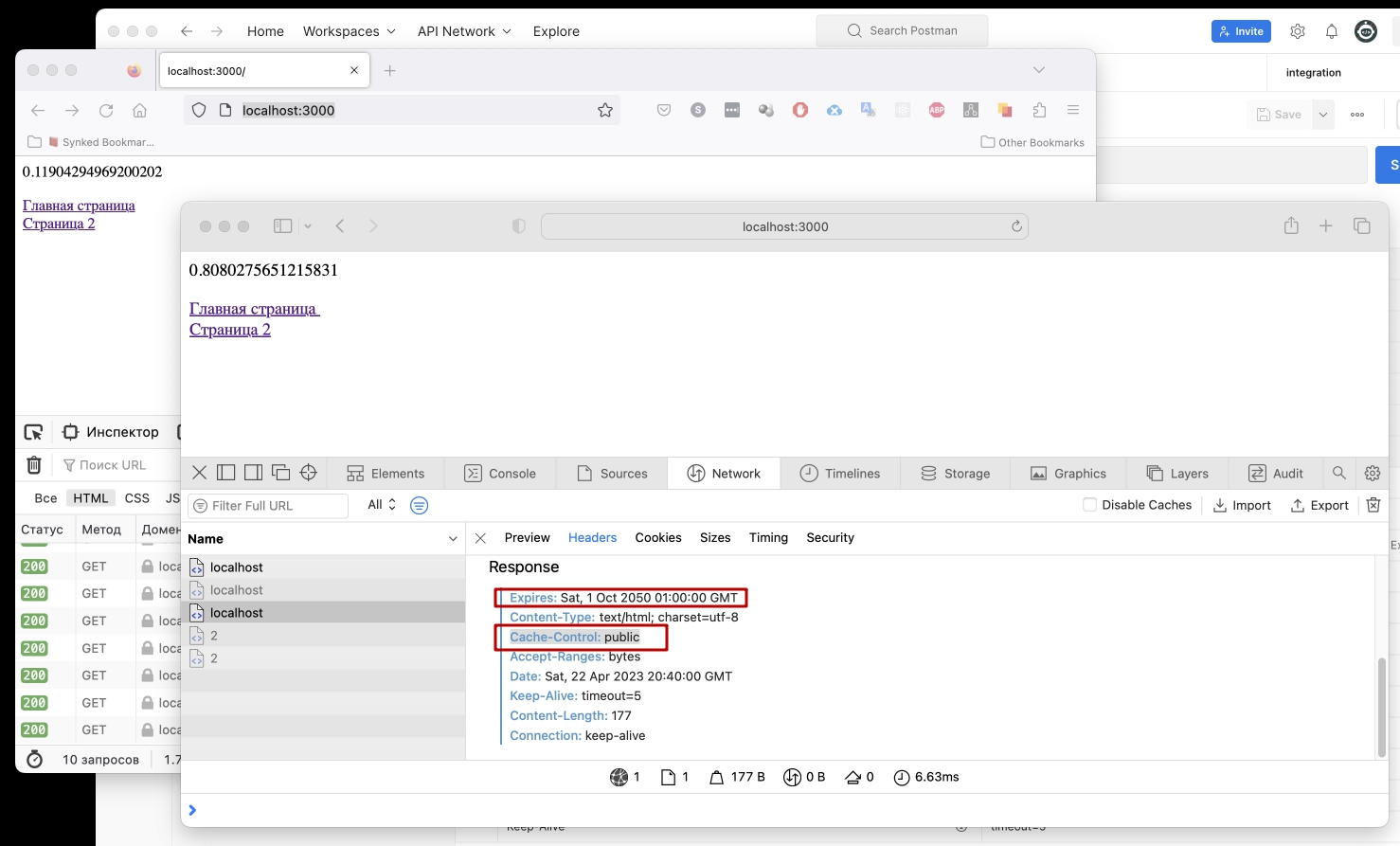
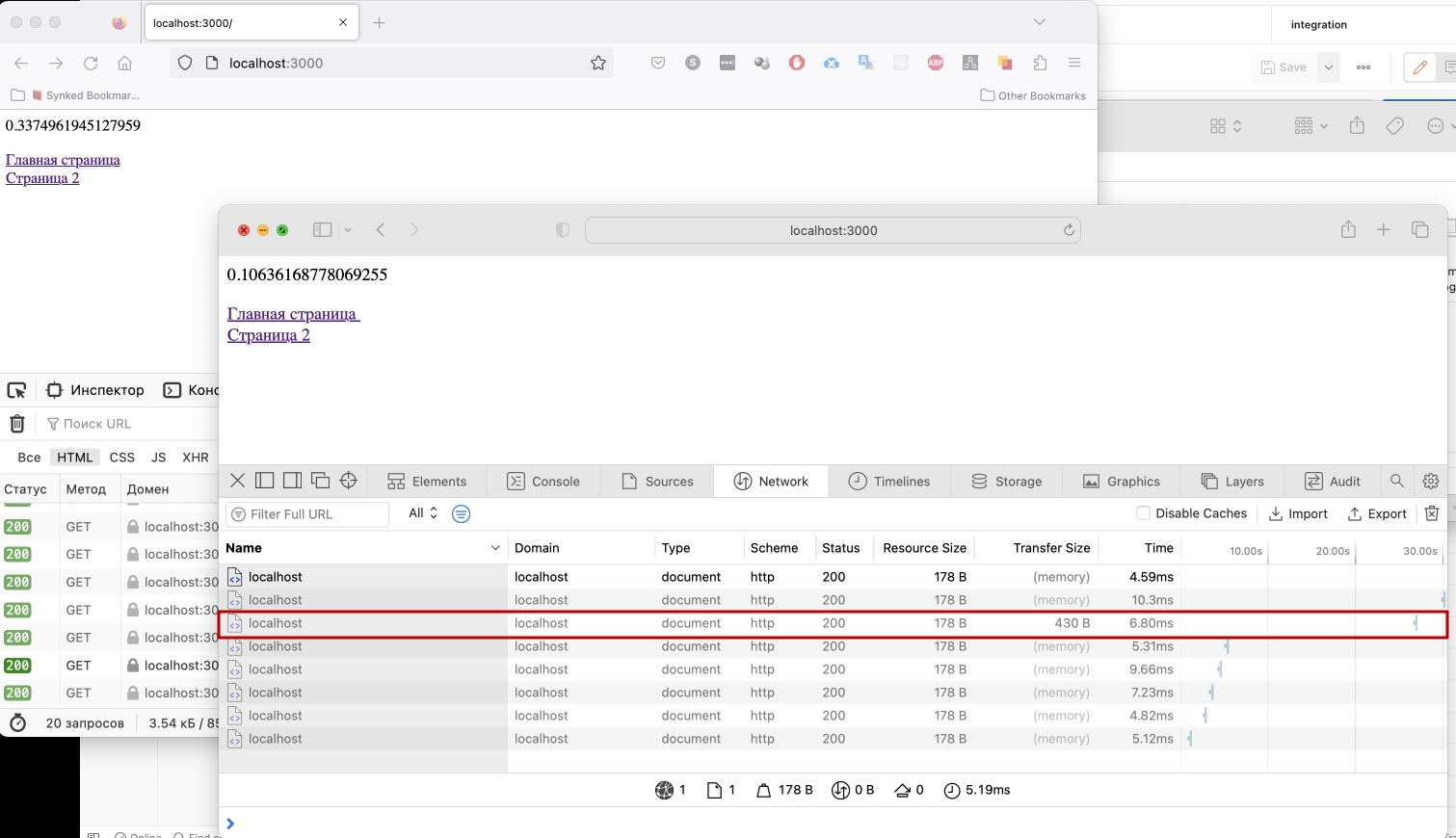
Я проверил в 3-х браузерах: Chrom, Firefox и Safari. Само наличие заголовка Cache-Control не перечеркивает работу заголовка Expires. Это происходит в том случае, если заголовок Cache-Control имеет запрещающие опции, например no-cache или no-store, а так же если Cache-Control переопределяет время жизни кеша в абсолютных секундах: Cache-Control: max-age=30
В последнем случае при использовании двух заголовков кеш буден храниться 30 секунд, а не до 50-го года.
Пока писал статью, ответил еще на несколько вопросов.
Какое максимальное время жизни для кеша?
В rfc2616 сказано так: To mark a response as "never expires," an origin server sends an Expires date approximately one year from the time the response is sent. HTTP/1.1 servers SHOULD NOT send Expires dates more than one year in the future. (Ответ нашел тут)
Какие есть проблемы при использовании заголовка Expires?
Expires работает только с датами в формате GMT, что может привести к проблемам, если на сервере и клиенте установлены разные часовые пояса. Cache-Control использует относительное время, что позволяет избежать этих проблем.
Кроме того, некоторые браузеры и прокси-серверы могут игнорировать заголовок Expires, поэтому его использование не всегда гарантирует правильное кэширование ресурсов.
Заключение
Таким образом нужно помнить, что заголовок Expires устарел и нужно использовать Cache-Control. Но Expires все еще работает, и например, в случае невозможности использовать протокол HTTP1.1 а только HTTP1.0 то заголовок Expires будет полезен.
Сам по себе заголовок Expires очень простой и не требует ответных заголовков от клиента.
Вообще, может показаться, что я чрезмерно уделяю внимание этому "старью", но лично на мой взгляд глубокое понимание происходящего позволит предотвратить глупые и банальные ошибки.
Если статья была полезной, не забудь поделиться с другом! Удачи!
Ссылки на материалы:
Репозиторий с примерами: (https://github.com/Hydrock/article-hapi-caching/blob/main/examples/client-side/index.js)
Спецификация HTTP1.0 (https://www.w3.org/Protocols/HTTP/1.0/spec#Expires)
MDN Expires (https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Expires)
MDN Cache-Control (https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cache-Control)
Кеширование в веб приложениях. Часть 1. Заголовок Cache-Control.
Кеширование является одной из наиболее распространенных техник оптимизации производительности веб приложений. В своей работе я использую сервер HapiJS. Это довольно надежный сервис, со своим большим комьюнити и обширными инструментариями. Но вы, конечно, можете использовать любой другой веб сервер. В HapiJS кеширование может быть реализовано как на стороне клиента, так и на стороне сервера. В этой статье мы рассмотрим оба типа кеширования, а также одновременное использование клиентского и серверного кеширования. Статья будет полезна, не только разработчикам использующим Hapi фреймворк, но и всем остальным веб разработчикам, так как затрагивает описание и предназначение заголовков HTTP.

В статье я буду приводить примеры которые я загрузил на Github. Настоятельно рекомендую не просто читать статью, а скачивать примеры и пробовать описанное в статье самостоятельно. Так информация запоминается лучше и ваше время не пройдет зря. Я буду много экспериментировать, чтобы точно понять как работает та или иная технология.
Для начала вспомним, что означает слово "Кеш"? Согласно ресурсу etymonline, слово "Кеш" ("Cache") происходит от сленга франко-канадских звероловов и означает «укрытие для припасов и провизии» (1660 г.). Так же слово можно перевести как склад, тайник или схрон.
В компьютерных технологиях Кэш - это место, где компьютер хранит копии данных, которые часто запрашиваются программами или пользователем. Кэш позволяет ускорить работу компьютера, так как он может быстро получить доступ к данным из кэша, вместо того, чтобы каждый раз их загружать с более медленного устройства, например, жесткого диска или интернета. Это особенно полезно для часто используемых данных, таких как картинки, видео, файлы и веб-страницы.
Отлично! С понятием разобрались. Как же нам ускорить наше приложение используя Кеш в веб приложении на HapiJS? Об этом ниже.
Кэширование на стороне клиента
Чтобы сэкономить на передаче данных между сервером и браузером, вы можете указать последнему сохранить ресурсы в памяти браузера до определенного времени.
Протокол HTTP определяет несколько заголовков HTTP, чтобы указать, как клиенты, такие как браузеры, должны кэшировать ресурсы. Чтобы узнать больше об этих заголовках и решить, какие из них подходят для вашего варианта использования, ознакомьтесь с этим полезным руководством, составленным Google.
В первой части этого этой статьи показано, как легко настроить hapi для отправки этих заголовков клиентам.
Cache-Control и Last-Modified
Заголовок Cache-Control сообщает браузеру и любым промежуточным кэшам (между браузером и сервером могут находиться промежуточные сервера и прокси), можно ли кэшировать ресурс и на какой срок. Например, Cache-Control:max-age=30, must-revalidate, private означает, что браузер может кэшировать ресурс в течение тридцати секунд, а private означает, что он не должен кэшироваться промежуточными кэшами, а только браузером. Директива ответа must-revalidate указывает, что ответ может быть сохранен в кеше и может повторно использоваться, пока он свежий. Если ответ устаревает, его необходимо проверить на исходном сервере перед повторным использованием.
Давайте напишем простой сервер на Hapi. Создайте файл index.js и напишите следующий код. Затем запустите командой node ./index.js
1const Hapi = require('@hapi/hapi');
2
3// Создаем сервер на порту 3000
4const server = Hapi.server({
5 host: 'localhost',
6 port: 3000
7});
8
9// Создаем простой роут для теста
10server.route({
11 method: 'GET',
12 path:'/',
13 handler: function (request, h) {
14 return 'Это корневая страница.';
15 }
16});
17
18// Запускаем сервер
19async function start() {
20
21 try {
22 await server.start();
23 }
24 catch (err) {
25 console.log(err);
26 process.exit(1);
27 }
28
29 console.log('Сервер запущен по адресу:', server.info.uri);
30}
31
32start();После запуска откроем адрес http://localhost:3000 в браузере:
Давайте обновим корневой роут добавив опции кеширования:
1// Создаем несколько простых роутов для теста
2server.route({
3 method: 'GET',
4 path:'/',
5 handler: function (request, h) {
6 return 'Это корневая страница.';
7 },
8 options: {
9 cache: {
10 // Отправляем от сервера клиенту заголовок
11 // cache-control: max-age=30, must-revalidate, private
12 // Время указываем в миллисекундах, в самом заголовке время в секундах
13 expiresIn: 30 * 1000,
14 privacy: 'private'
15 }
16 }
17});Конечно же после каждого изменения перезапускаем сервер. Проверим в devtools браузера, действительно ли мы получаем в ответ от сервера нужный нам заголовок?
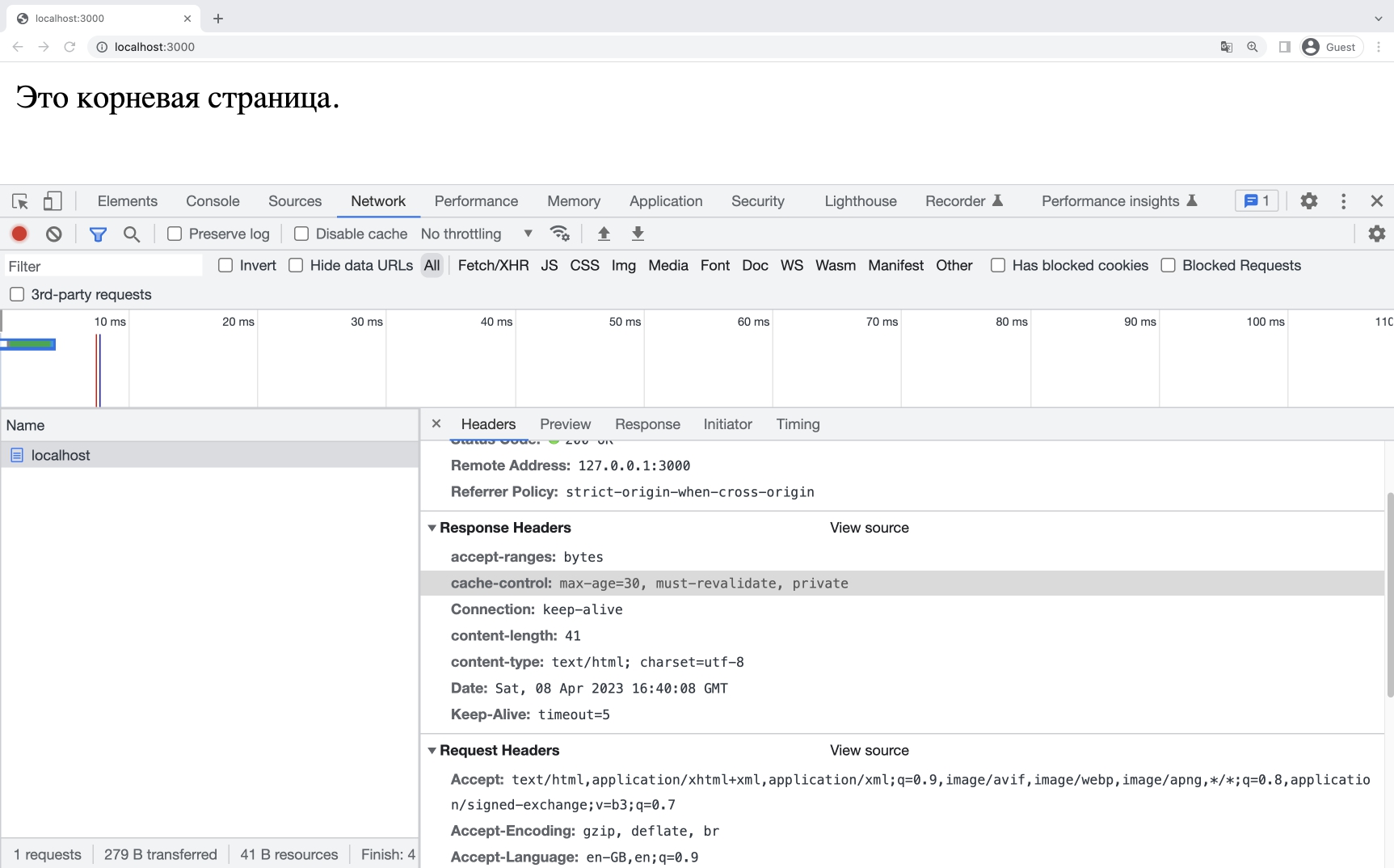
Да, видим заголовок, но почему тогда код ответа при запросе на этот адрес всегда 200? Напомню что статус 200 означает OK - запрос выполнен удачно. Причем в документации сказано, что по умолчанию, такие ответы кешируемые, если нет других инструкций.
Но если мы сделаем несколько запросов подряд, мы все еще видим статус 200, а не ожидаемый статус 304 NOT MODIFIED. Почему? Давайте разбираться вместе.
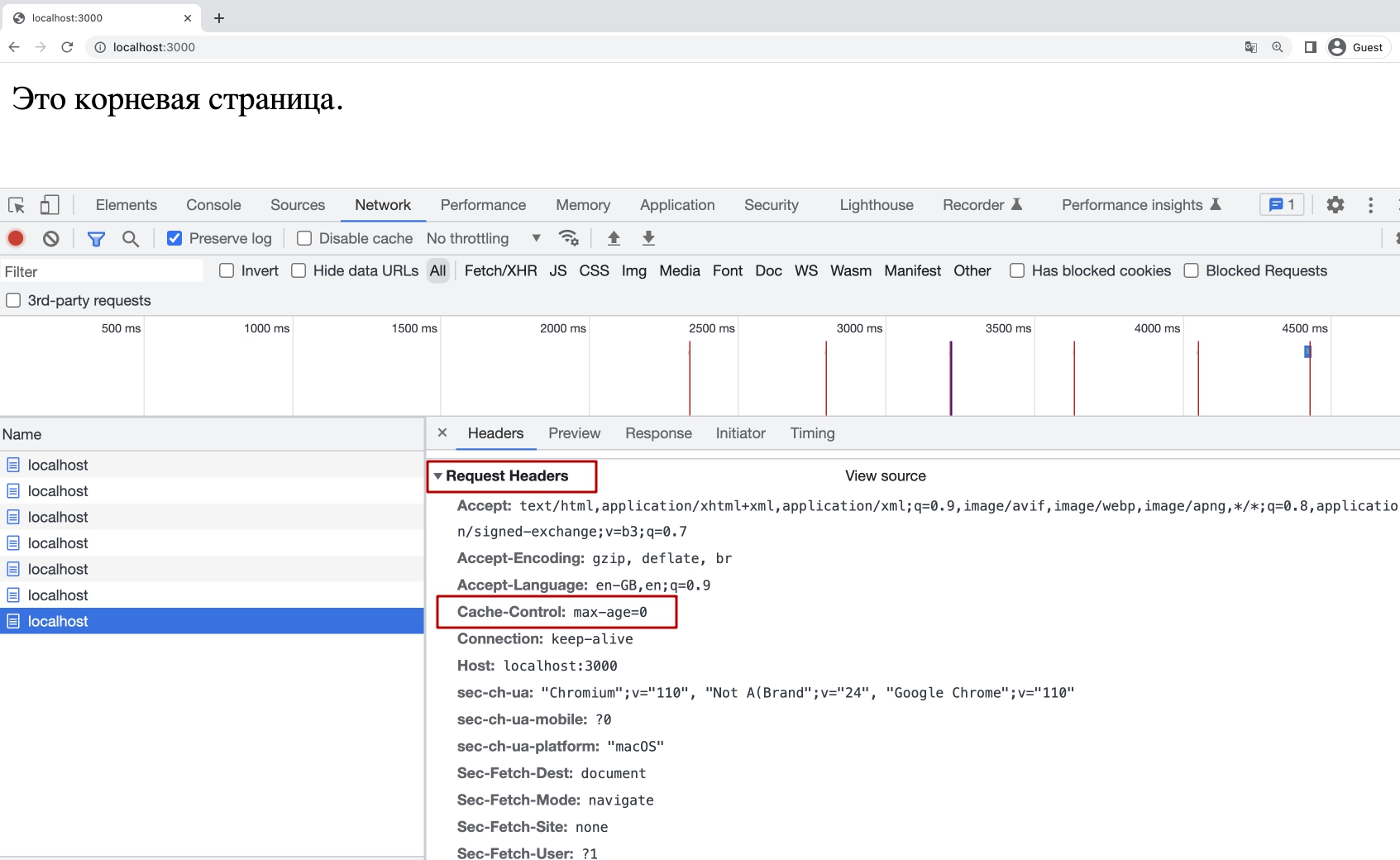
Сначала я обратил внимание на то, что клиенты тоже отправляют серверу заголовок Cache-Control. Этот заголовок от клиента так же может указать серверу свои собственные требования. Причем в разных браузерах политика по отправляемым значениям может быть разная.
Например Google Chrome отправляет заголовок Cache-Control: max-age=0.
А вот Mozilla Firefox отправляет заголовок Cache-Control: no-cache.
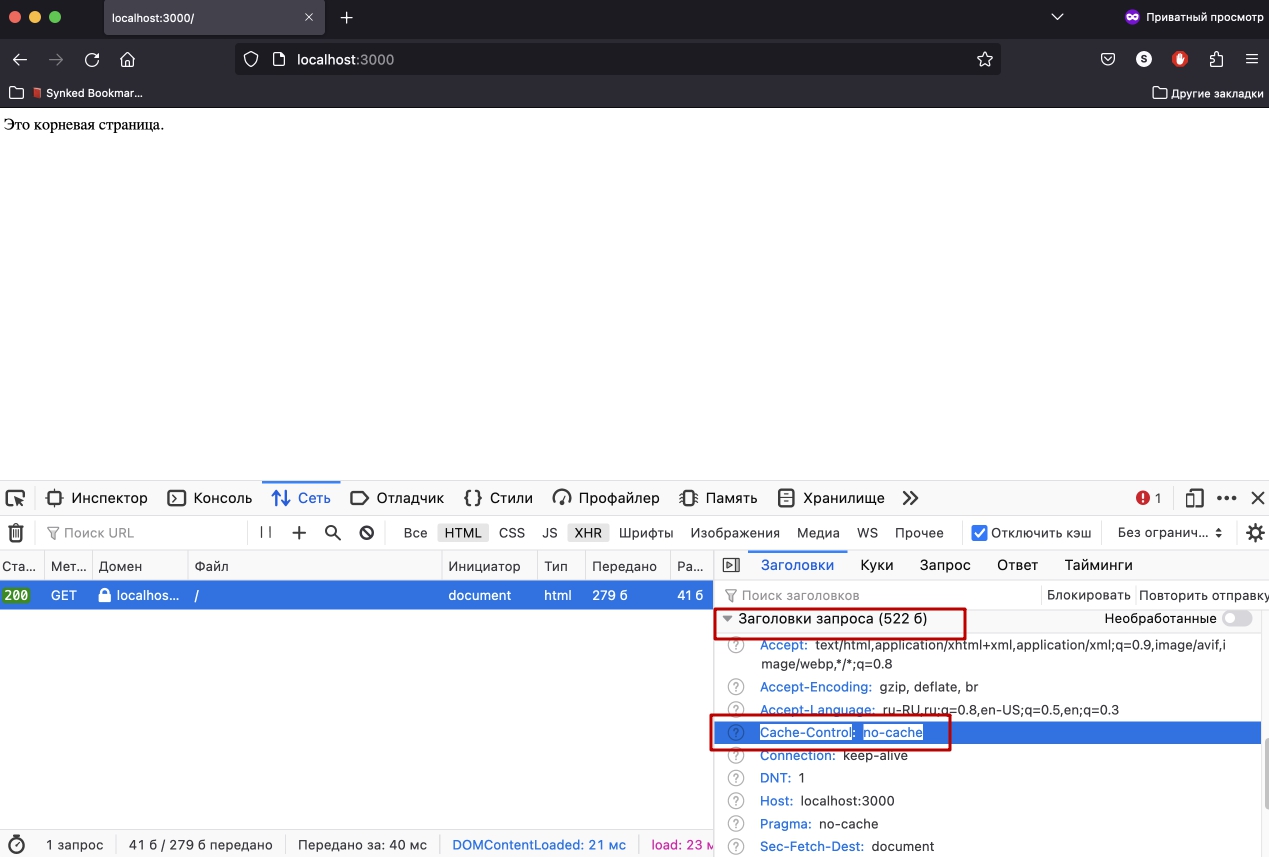
Safari так же отправляет заголовок Cache-Control: no-cache
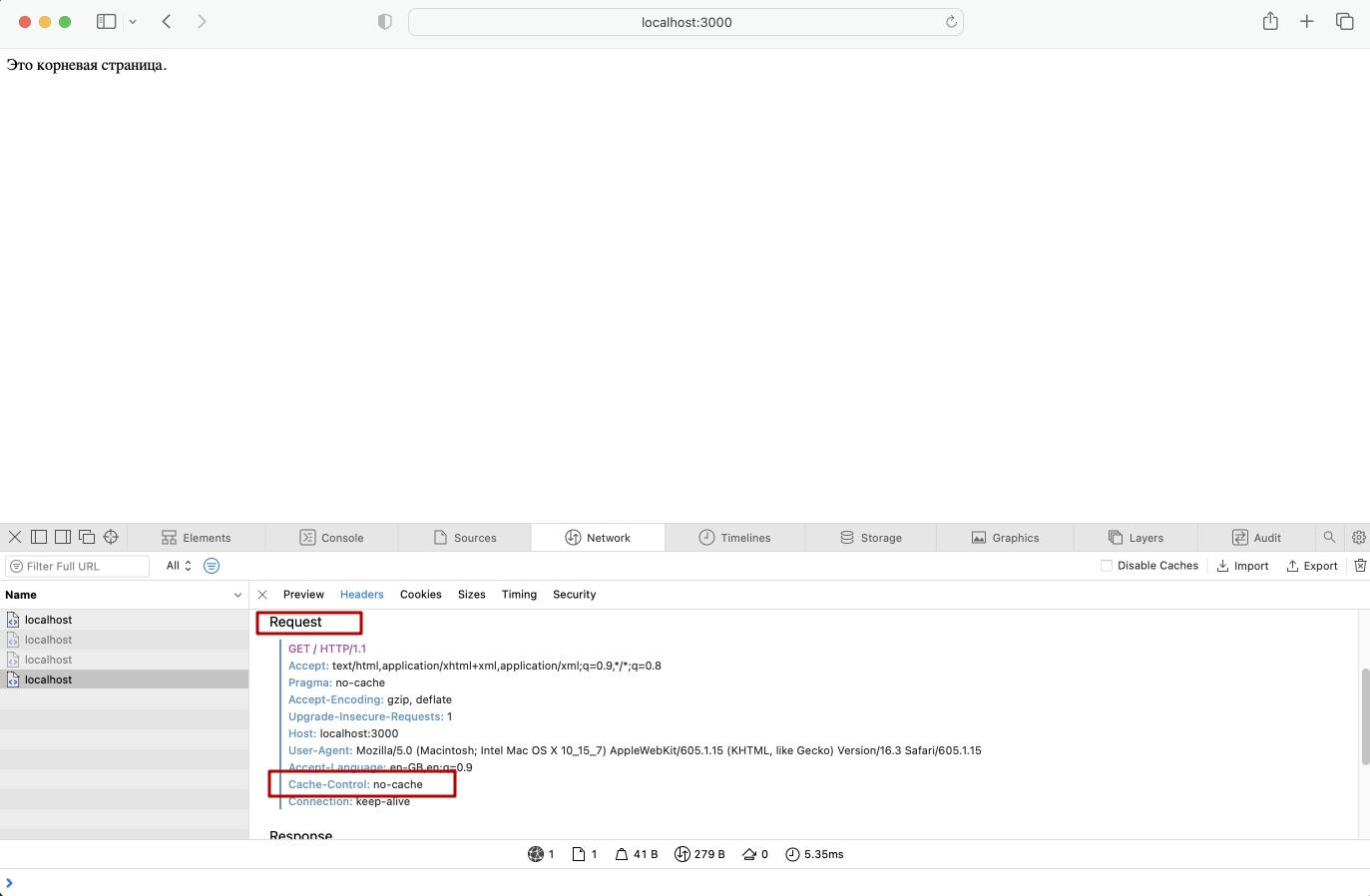
Так же для экспериментов я буду использовать Postman. Эта программа позволяет удобно разрабатывать и тестировать ваши HTTP запросы.
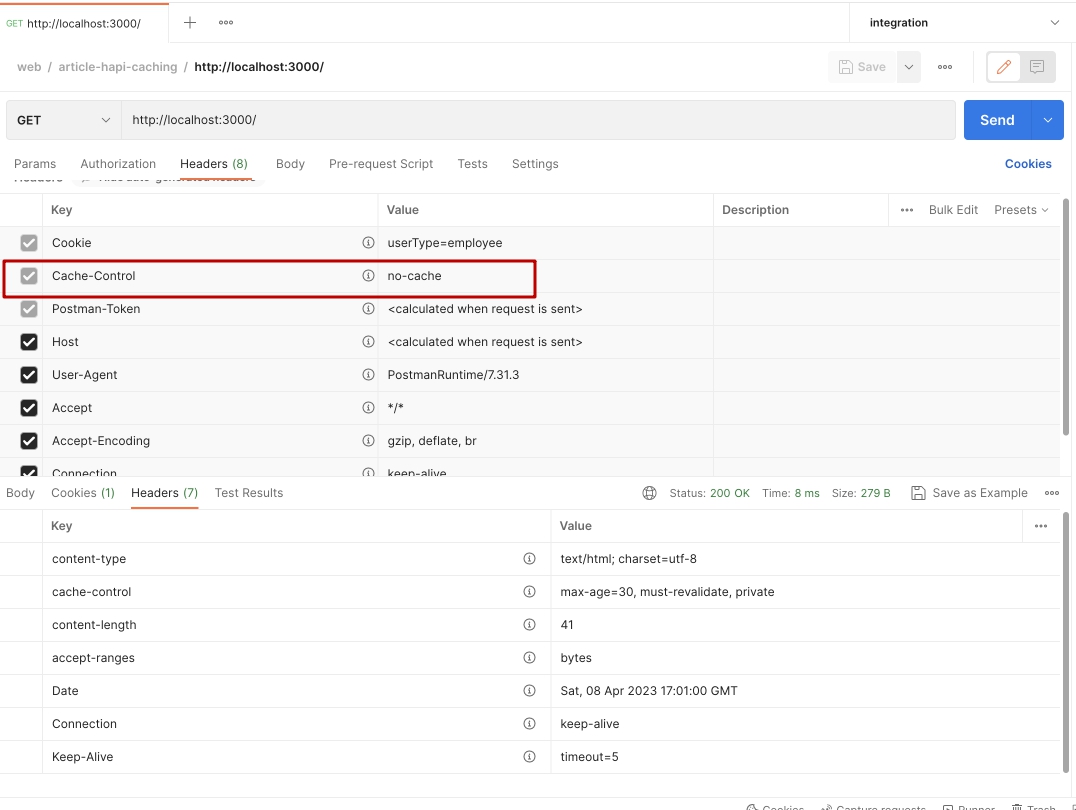
Что же отправляет Postman? А все тот же Cache-Control: no-cache. Причем значение заблокировано и управляется клиентом (Postman-ом).
На что же влияет этот заголовок отправляемый с клиента серверу? Такой заголовок позволят указать дополнительные параметры кеширования на сервере.
Ок. На браузеры мы повлиять не можем. Но что же с Postman? Можно ли в нем отправку? Ведь это нам нужно для теста.
Заголовок Cache-Control используется для управления кешированием в разных точках сети: на стороне клиента (браузера) и на стороне сервера.
Когда клиент отправляет запрос на сервер, он может добавлять заголовок Cache-Control, чтобы указать, как должен обрабатываться этот запрос на стороне сервера. Например, он может указать, что сервер должен закешировать ответ на некоторое время. Также клиент может отправить другие инструкции, например, требование перезагрузки кеша, чтобы обеспечить получение самой свежей версии ресурса.
Когда сервер отправляет ответ клиенту, он может также добавлять заголовок Cache-Control, чтобы указать, как должен обрабатываться этот ответ на стороне клиента. Например, он может указать, что браузер должен закешировать ответ на определенное время, чтобы уменьшить количество запросов к серверу и ускорить загрузку страниц. Также сервер может отправить другие инструкции, например, требование проверки наличия новой версии ресурса на сервере перед использованием закешированной версии.
Таким образом, заголовок Cache-Control может использоваться как на стороне клиента, так и на стороне сервера, чтобы управлять кешированием и оптимизировать работу сети.
Отлично, с этим разобрались. К кешированию на сервере мы вернемся позже, пока мы разбираем кеширование на клиента.
Давайте отключим заголовок Cache-Control отправляемым из Postman на сервер, ведь мы все равно пока не кешируем контент на сервере, а наличие этого заголовка в запросе лишь запутывает нас в наших экспериментах.
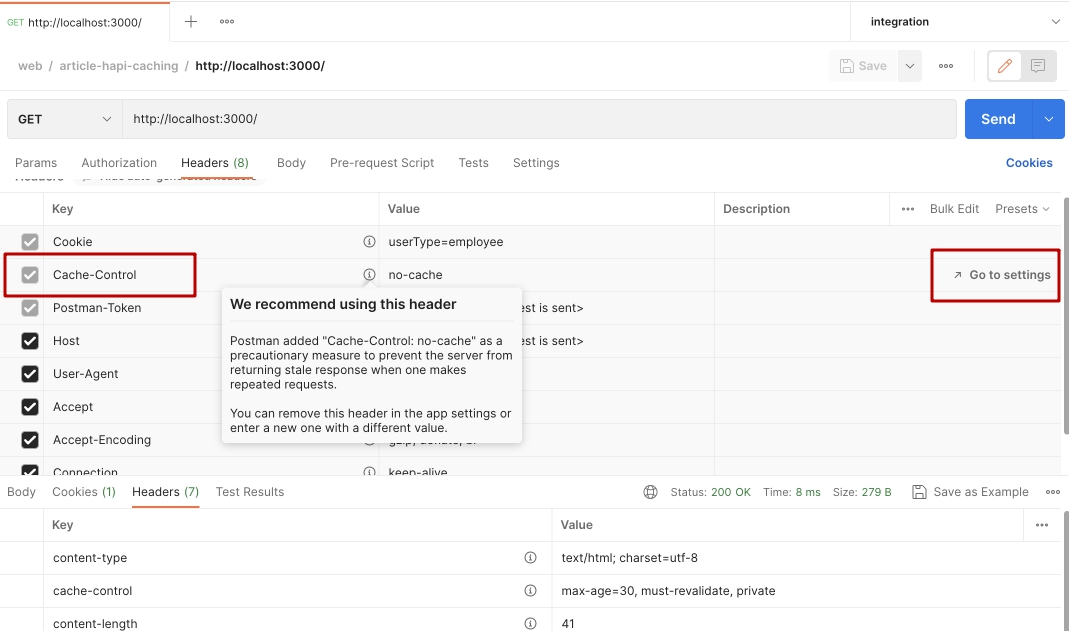
Дело в том, что Postman по умолчанию всегда отправляет заголовок Cache-Control: no-cache. Т.е. Postman говорит серверу - "не кешируй запросы на сервере, я тут пытаюсь протестировать API".
Вы можете отключить это поведение в настройках на уровне всего приложения, либо просто определив собственный заголовок на вкладке Headers.
Для тестов я отключу этот заголовок на уровне всего приложения:
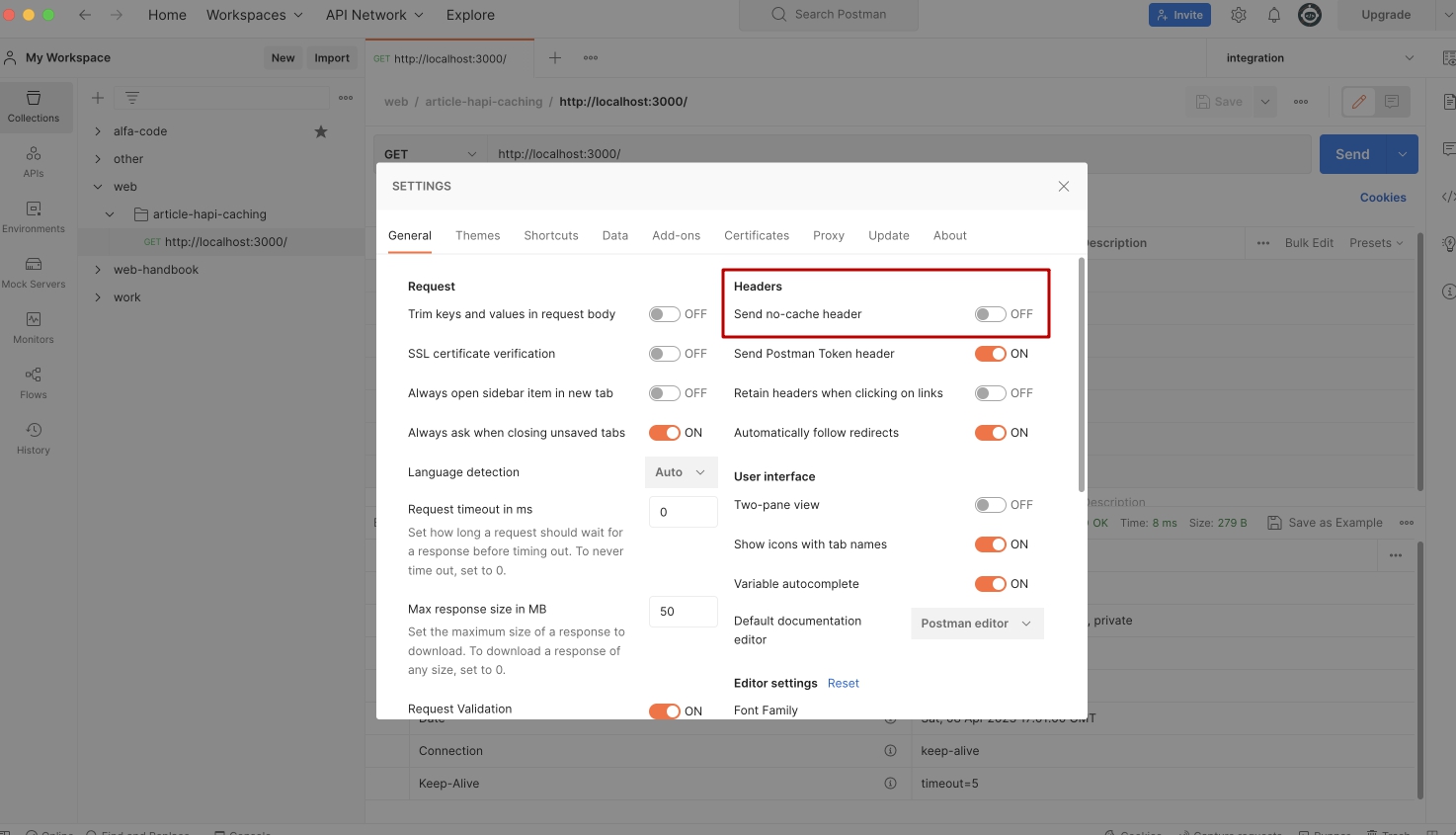
Пробуем выполнить очередной запрос на сервер. Наконец видим что в запросе заголовка Cache-Control нет. Но этот заголовок есть в ответе, как и ожидалось.
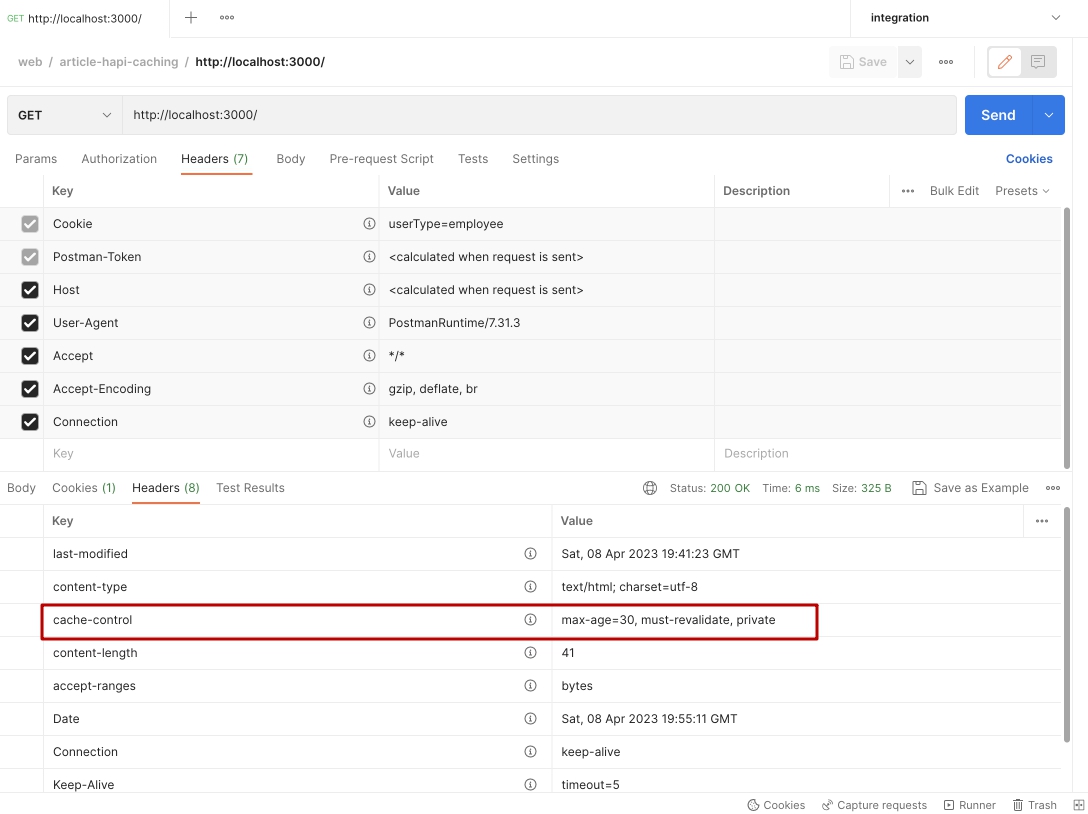
Но в ответе все еще 200? То есть кеш на стороне клиента не используется? Почему? Что мы делаем не так?
Дело в том, что для принятия решения серверу, о том нужно ли на запрос отдать клиенту свежий контент со статусом 200, или же просто вернуть статус 304 без тела как указание - использовать данные из кеша, недостаточно одного сохраненного кеша на стороне клиента.
Необходим заголовок Last-Modified (заголовок от сервера к клиенту) и его пара, заголовок If-Modified-Since (заголовок от клиента к серверу)
Давайте рассмотрим для чего нужны эти заголовки.
HTTP заголовок "Last-Modified" (Последнее изменение) используется для указания даты и времени последнего изменения ресурса (html документа, картинки и др.) на сервере. Это позволяет браузерам и другим клиентским приложениям узнать, был ли ресурс изменен с момента последнего запроса, и если да, то загрузить обновленную версию.
Данный заголовок обычно добавляется автоматически, сервером. Например, если вы отдаете с сервера статику (картинки, pdf документы и прочее), сервер сам может узнавать последнюю дату изменения файла и подставлять заголовок Last-Modified.
Чаще всего, пользователи Hapi для раздачи статики используют @hapi/inert. Данный плагин автоматически проставит нужные заголовки.
Но в нашем случае мы просто отвечаем строкой "Это корневая страница." По сути, наш контент генерируется каждый раз заново и при таком подходе кешировать данные на клиенте незачем. Но мы все же добавим к ответу сервера заголовок "Last-Modified", это нам нужно для эксперимента.
1// При запуске сервера создаем ложную дату последней модификации файла
2const lastModified = new Date();
3
4// Создаем простой роут для теста.
5server.route({
6 method: 'GET',
7 path:'/',
8 handler: function (request, h) {
9 return h.response('Это корневая страница.').header('Last-Modified', lastModified.toUTCString());
10 },
11 options: {
12 cache: {
13 // Отправляем от сервера клиенту заголовок
14 // cache-control: max-age=30, must-revalidate, private
15 // Время указываем в миллисекундах, в самом заголовке время в секундах
16 expiresIn: 30 * 1000,
17 privacy: 'private'
18 }
19 }
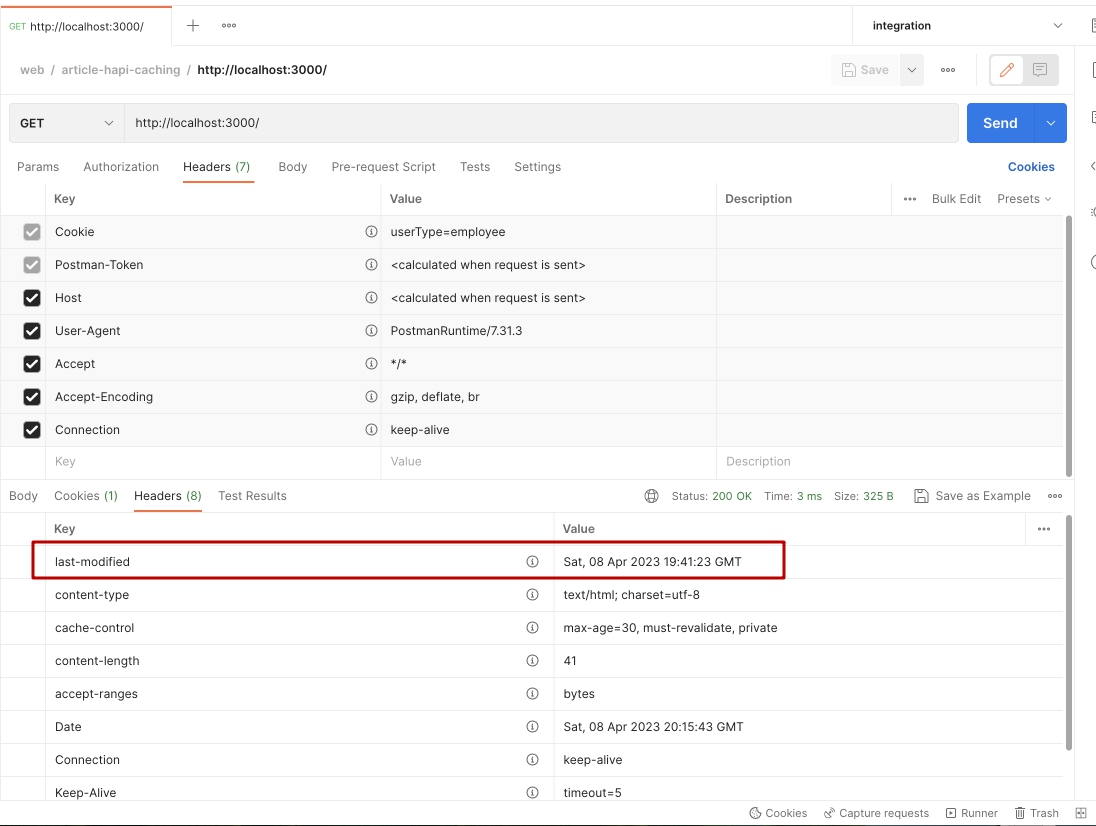
20});После перезапуска сервера, проверим ответ в Postman:
Сделаю небольшое отступление. Вы могли заметить, что заголовки пишутся то с заглавной буквы, то со строчной, в одних клиентах с заглавной, в других строчными.
Согласно стандарту HTTP, названия всех заголовков должны быть регистронезависимыми, то есть сервер должен быть способен обрабатывать их независимо от того, написаны они заглавными буквами или строчными.
Однако, по традиции, в HTTP-заголовках используется так называемый "kanonische Form".
"Kanonische Form" - это термин, который используется в контексте HTTP-заголовков для обозначения определенного стиля написания заголовков. Рекомендуется использовать для достижения единообразия и лучшей читаемости.
Термин "Kanonische Form" происходит из немецкого языка, где он означает "каноническая форма". В контексте HTTP-заголовков он обычно относится к стилю написания заголовков, где первая буква каждого слова заголовка (кроме предлогов, союзов и т. д.) является заглавной, а все остальные буквы - строчными.
Например, в "Content-Type" первая буква каждого слова является заглавной, а в "Accept-Encoding" - только первая буква первого слова. Такой стиль написания заголовков упрощает чтение и облегчает восприятие информации, а также помогает обеспечить единообразие в их записи.
Хотя термин "Kanonische Form" официально не определен в стандарте HTTP, он широко используется в сообществе разработчиков и экспертов по протоколу HTTP.
Таким образом, хотя сервер может обрабатывать заголовки HTTP, написанные как заглавными, так и строчными буквами, рекомендуется использовать "Kanonische Form" для их записи и заглавные буквы для обозначения методов и версии протокола HTTP.
Продолжим. Мы вернули от сервера 2 заголовка: Cache-Control который просит браузер закешировать контент на 30 секунд, и заголовок Last-Modified который сообщает о том когда этот файл был последний раз изменен.
Но мы все еще видим статус 200? Что на этот раз теперь не так?
Да, в этот раз браузер закешировал данные веб страницы, но ведь при следующем запросе контент на сервере мог измениться, поэтому клиент все равно, повторно, создает соединение с сервером при очередном запросе. В этот раз уже сервер должен решить, что отправить клиенту, либо если кеш совпадаем с файлом который сервер желает отдать клиенту и тогда сервер просто отправляет клиенту статус 304 NOT MODIFIED, что разрешает браузеру использовать кеш, либо если кеш отличается от файла на сервере, и тогда сервер отправляет статус 200, контент и новые заголовки Cache-Control и Last-Modified.
Но как сервер узнает, отличается ли кеш на клиенте от файла на сервере? Для этого, ранее, мы отправляли в браузер заголовок Last-Modified.
Теперь в работу вступает его "брат", заголовок If-Modified-Since (Есть еще заголовок If-Unmodified-Since - но об этом в другой раз).
Заголовок If-Modified-Since используется в протоколе HTTP и позволяет серверу проверить, был ли изменен запрашиваемый ресурс после указанной даты и времени. Если ресурс не был изменен, сервер возвращает код состояния HTTP 304 Not Modified, указывая на то, что клиент может использовать свою кэшированную версию ресурса, не загружая его заново.
Добавим этот заголовок в запрос, со значением переданным с сервера.
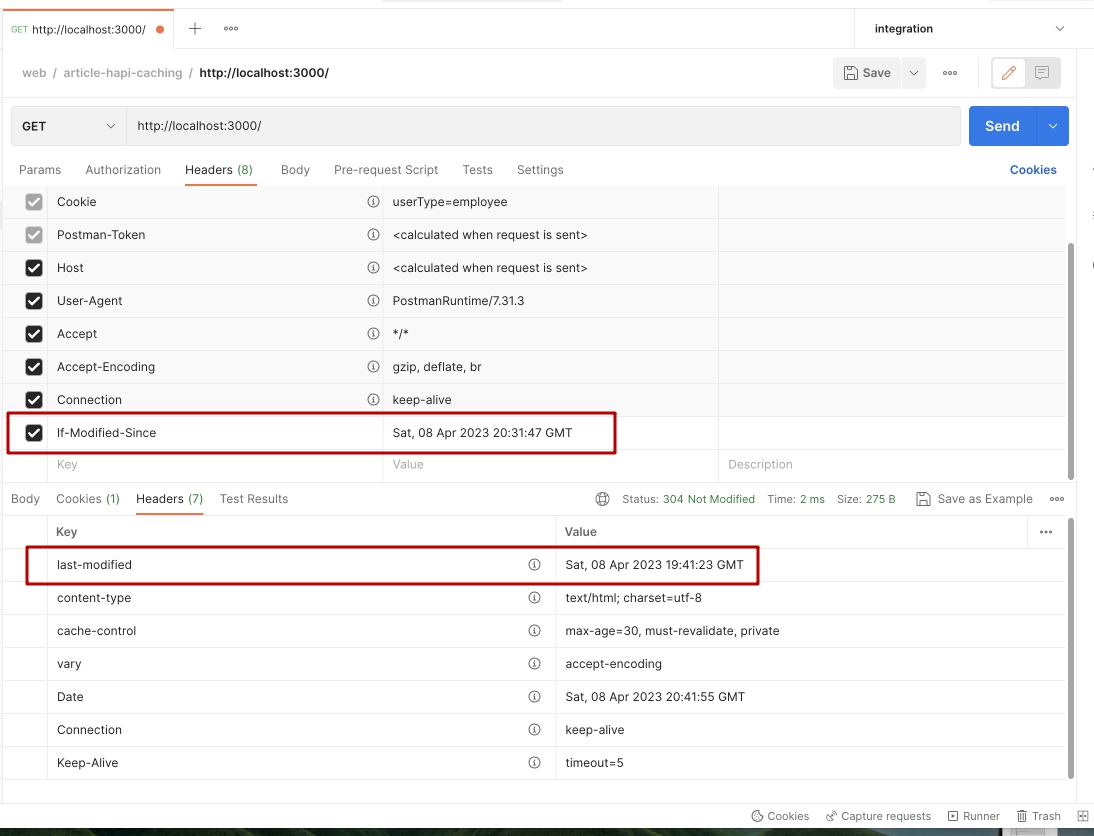
Ура! Мы видим статус 304. Что же он означает? Он означает, что запрос от клиента был отправлен на сервер, обработчик роута на сервере выполнился, но сервер принял решение вернуть статус 304, так как по заголовку If-Modified-Since знает, что на клиенте есть Кеш, и так как дата модификации ресурса не поменялась, говорит клиенту - "Используй свой Кеш, нет смысла отправлять файл обратно"
По идее, заголовок If-Modified-Since клиент должен отправлять самостоятельно, ведь теперь он хранит кеш, и должен сказать браузеру когда последний раз модифицировался этот файл. Но Postman этого не делает. Вообще все поведение которое связано с кешированием, в Postman довольно отличается от поведения браузера. Для сравнения взглянем на Chrome.
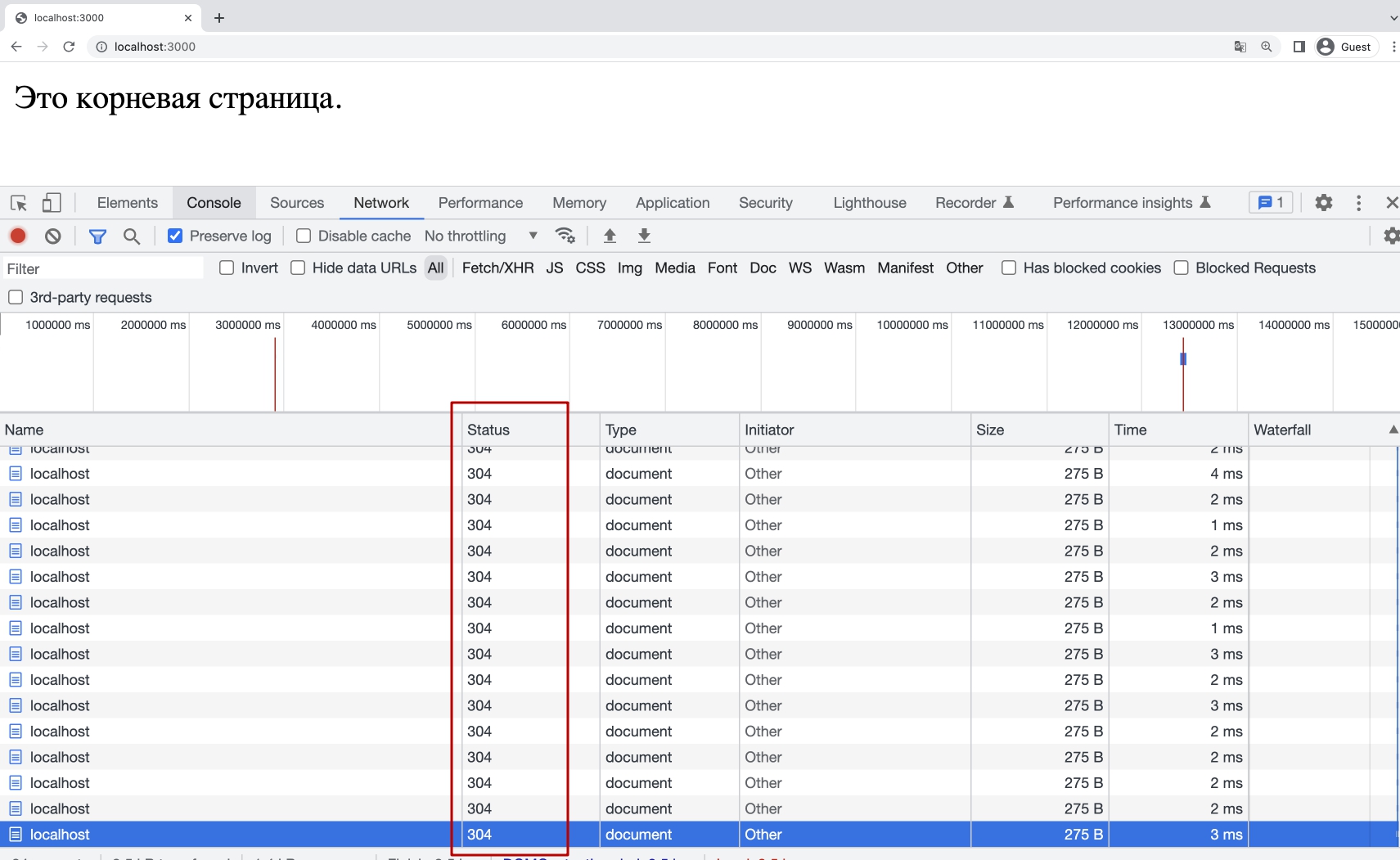
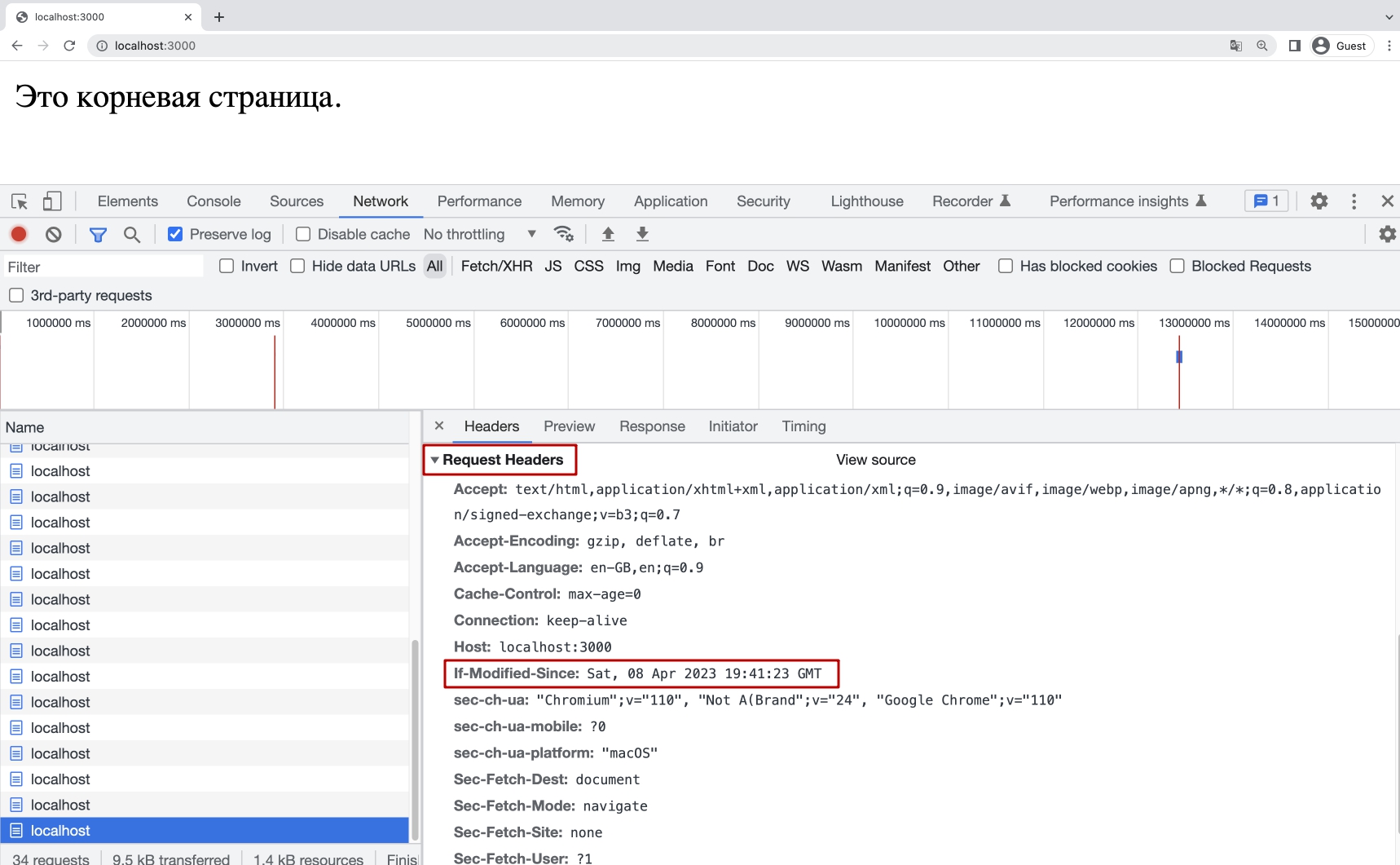
Мы видим что браузер Chrome самостоятельно при запросе отправляет заголовок If-Modified-Since.
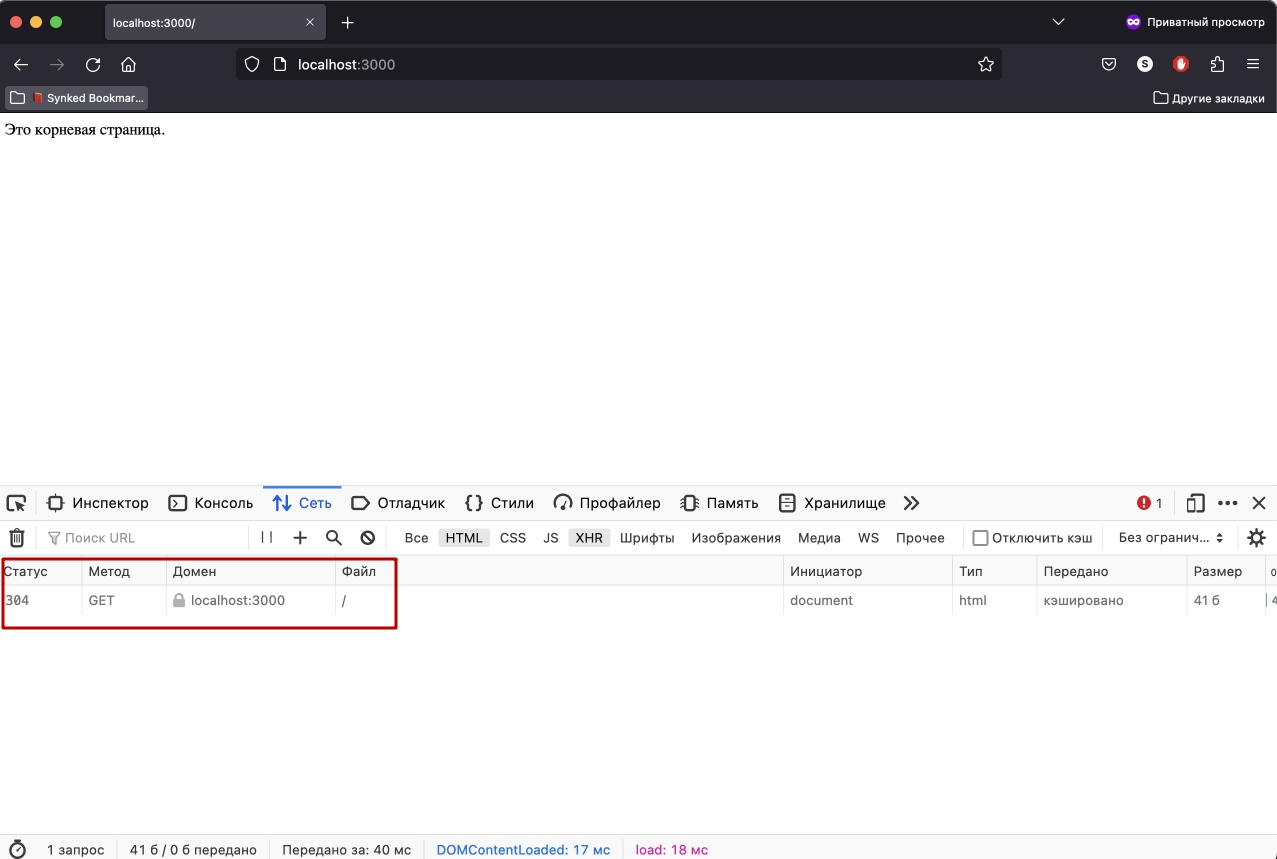
Как насчет Firefox?
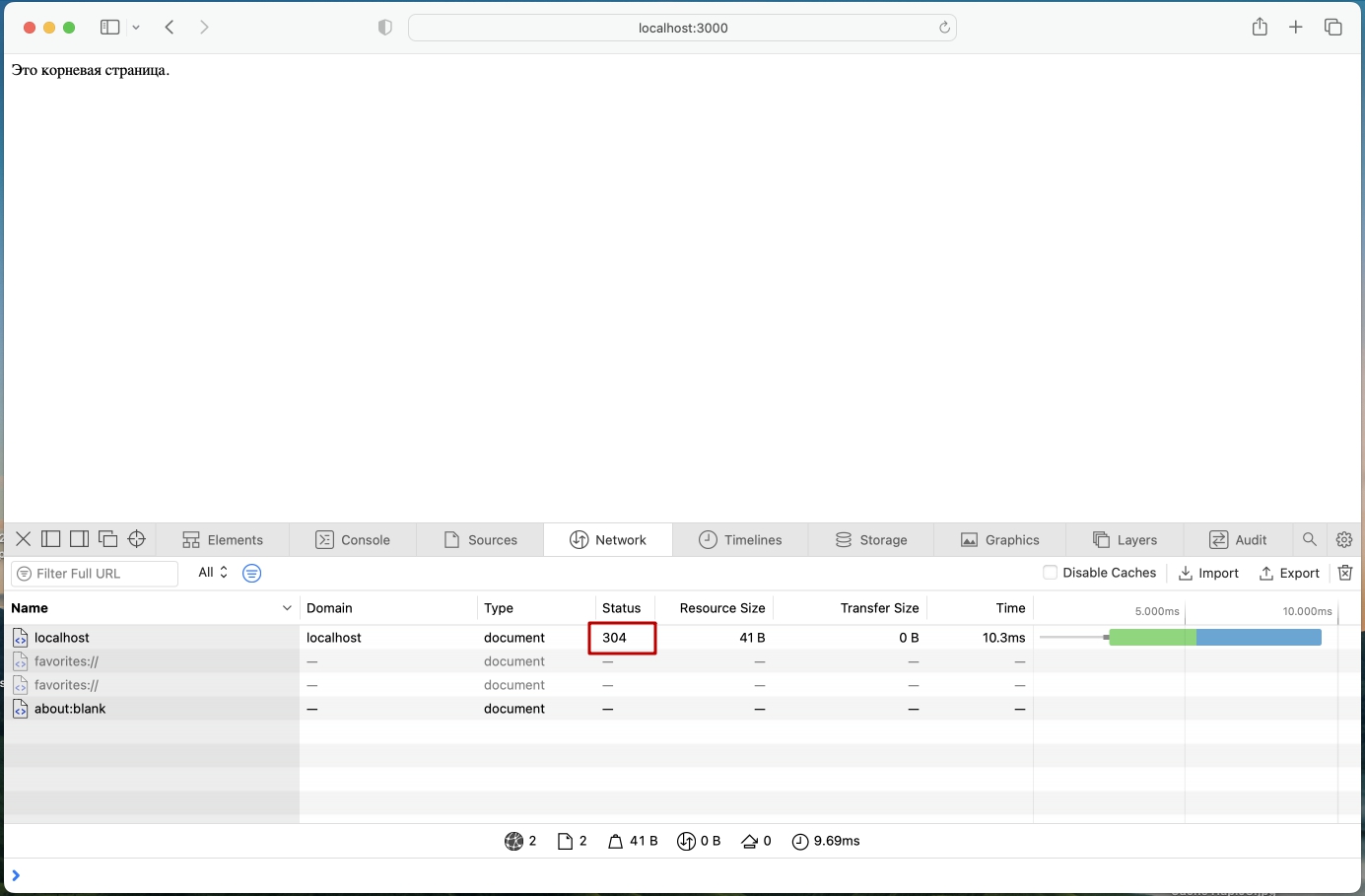
А Safari? И тоже работает?
Но подождите, если я сделаю еще несколько запросов, статусы снова становятся 200. Что же это творится?
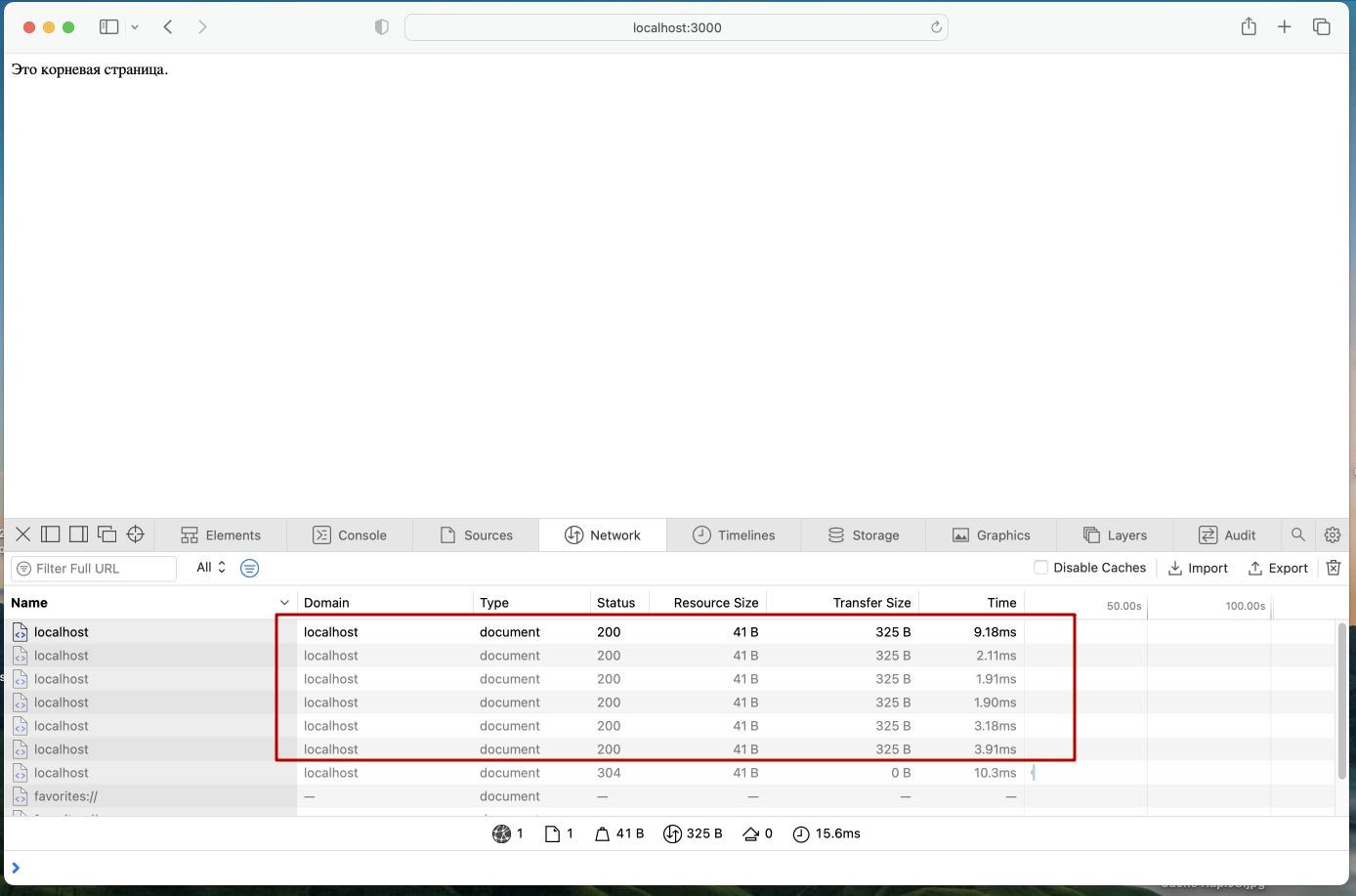
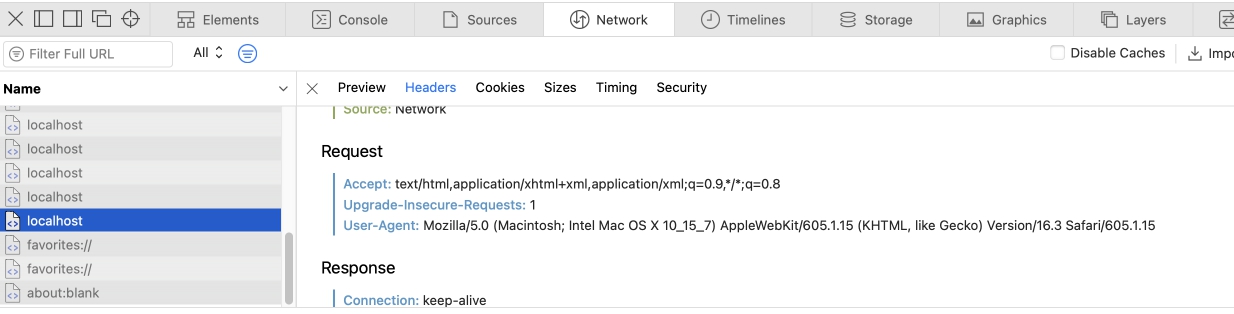
Все запросы со статусом 200, несмотря на то, что мы установили время жизни кеша и сообщили время последней модификации ресурса. Сервер каждый раз отдает новый контент. Проверить это очень легко.
Вот на что я наткнулся в поисках ответа на вопрос:
Nothing in the spec says that user agents MUST or SHOULD send If-Modified-Since, they just MAY.
У браузера Safari, как всегда, свое мнение на этот счет.
Ок. Это поведение не критично, но вот что действительно странно: Почему статус 304. Ведь мы сохранили данные в Кеш браузера, а это означает, что пока не истекло время жизни Кеша, браузер вовсе не должен делать запросы на сервер, браузер должен просто вернуть данные из кеша (это будет видно в devtools) и поставить статус 200. Запрос на сервер вообще не должен происходить.
В нашем же случае мы устанавливаем, время жизни Кеша в 30 секунд. Но несмотря на это браузера все равно делает запрос на сервер, как будто время жизни кеша вышло. Сервер сравнивает дату модификации ресурса, понимает что кеш валидный и отправляет сообщение клиенту 304 NOT MODIFIED - подсказывает браузеру что он может использовать сохраненный кеш, при этом тело ответа пустое. Т.е. браузер использует Кеш, но все равно постоянно создает соединение между клиентом и сервером, что отнимает драгоценные ресурсы.
Я потратил очень много времени, чтобы понять в чем дело. Все оказалось очень просто, но я кажется потратил треть своих нервных клеток. А дело вот в чем:
Если вы перезагружаете веб страницу при помощи кнопки "Reload Page" (обычно это круговая стрелка рядом с адресной строкой), то такая перезагрузка воспринимается браузером как принудительная, поэтому браузер игнорирует Кеш и создает подключение к серверу, для отправки http сообщения. Это работает во всех браузерах примерно одинаково с небольшими отличиями.
Для того чтобы удостовериться, что это действительно так, давайте немного исправим наш код. Добавим пару роутов и ссылки между ними.
1// При запуске сервера создаем ложную дату последней модификации файла
2const lastModified = new Date();
3
4// Создаем несколько простых роутов для теста
5server.route({
6 method: 'GET',
7 // Тут заложим роут / и /n где n не обязательный, любой, параметр
8 path: '/{n?}',
9 handler: function (request, h) {
10 // Генерируем случайное число, по нему мы визуально поймем, поменялся ли контент на веб странице.
11 const randomNum = Math.random();
12 // Выводим число в консоль сервера, просто чтобы понять, происходил ли вызов handler
13 console.log('randomNum: ', randomNum);
14
15 // Создаем HTML контент с двумя перекрестными ссылками.
16 const content = `
17 <p>${ Math.random(randomNum) }</p>
18 <a href="/"> Главная страница </a>
19 <br/>
20 <a href="/2"> Страница 2 </a>
21 `
22
23 // Создаем объект ответа.
24 const response = h.response(content);
25
26 // Добавляем заголовок последней модификации ресурса.
27 response.header('Last-Modified', lastModified.toUTCString());
28
29 return response;
30 },
31 options: {
32 cache: {
33 // Отправляем от сервера клиенту заголовок
34 // cache-control: max-age=30, must-revalidate, private
35 // Время указываем в миллисекундах, в самом заголовке время в секундах
36 expiresIn: 30 * 1000,
37 privacy: 'private'
38 }
39 }
40});Теперь в ответе от сервера приходят сгенерированные страницы на которых есть перекрестные ссылки. Попробуйте переходить на ту же страницу при помощи одной ссылки, или переходить между страницами.
На анимации ниже, я показываю, как принудительная перезагрузка в Хром игнорирует Кеш и отравляет запросы на сервер, при этом сервер отвечает 304. При этом в мы видим Request Headers в блоке информации о запросе.
Но если мы начинаем переходить по ссылке, на одну и ту же страницу, то тут же видим статус 200 и в колонке size надпись disk cached (кешировано на диске). При этом, если открыть информацию о запросе, мы не видим блока Request Headers. Ведь не было никакого запроса на сервер, мы видим блок Response Headers, благодаря этому можно сделать вывод, что кешируется не только сам контент, но и заголовки от сервера в кешируемом ресурсе, то есть контент берется из кеша и подставляются все заголовки из предыдущего запроса. Как будто запрос на сервер был, но на самом деле нет.
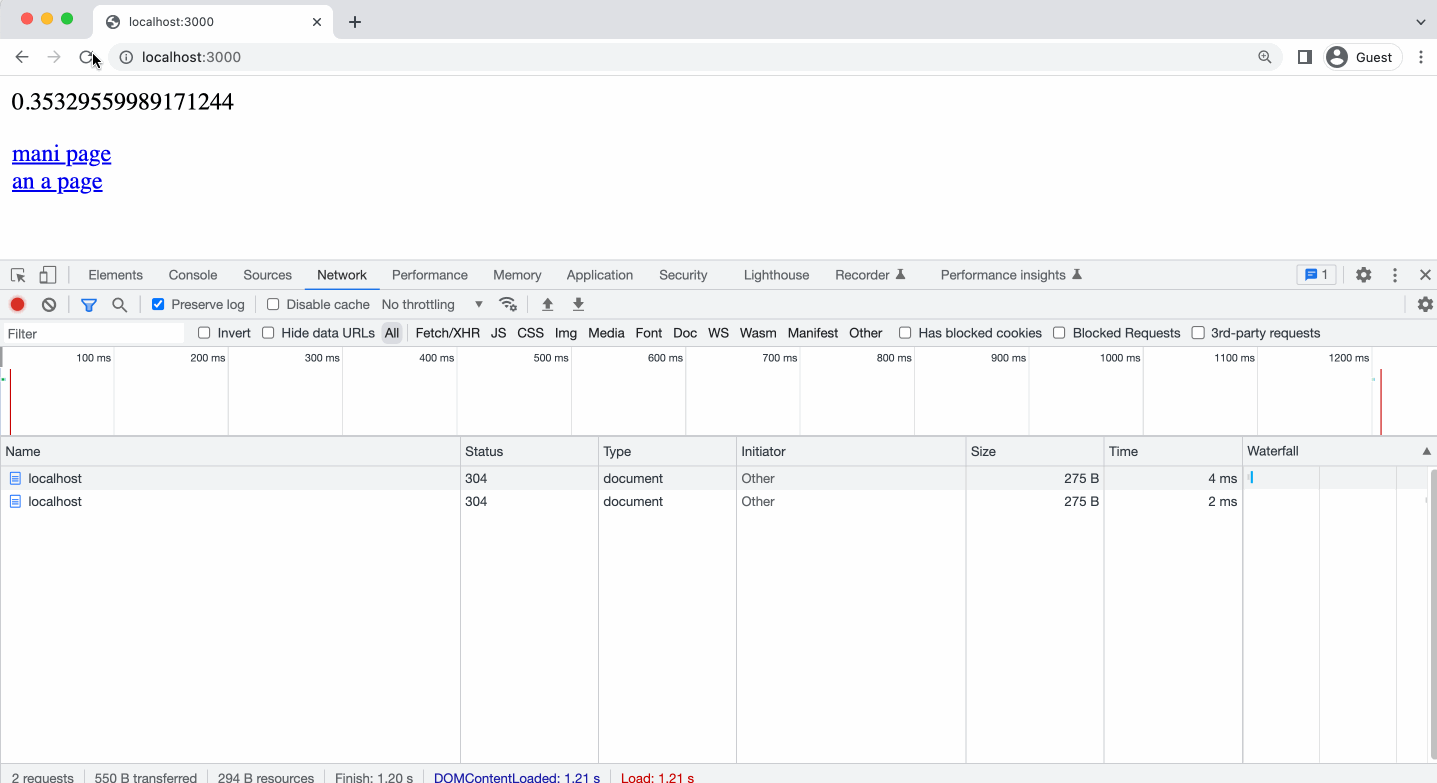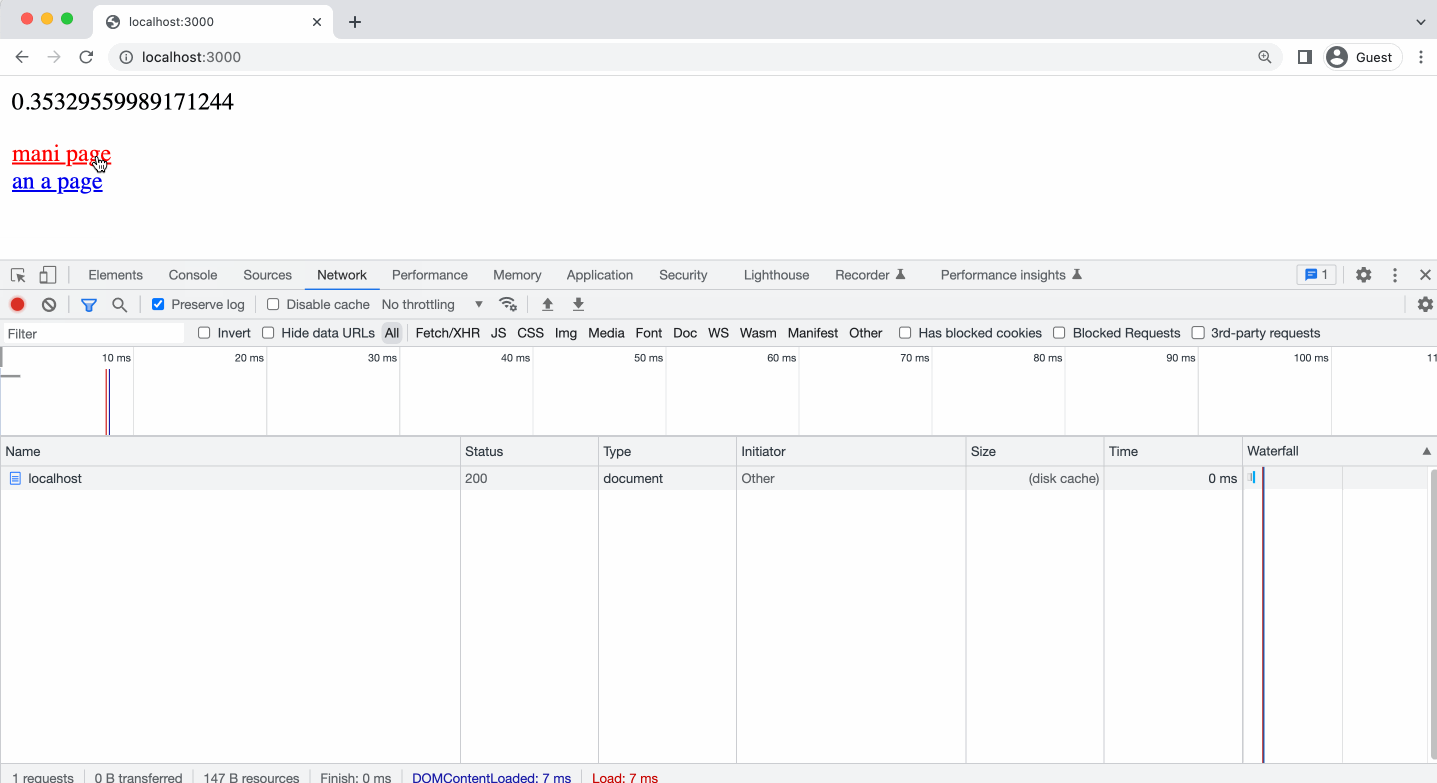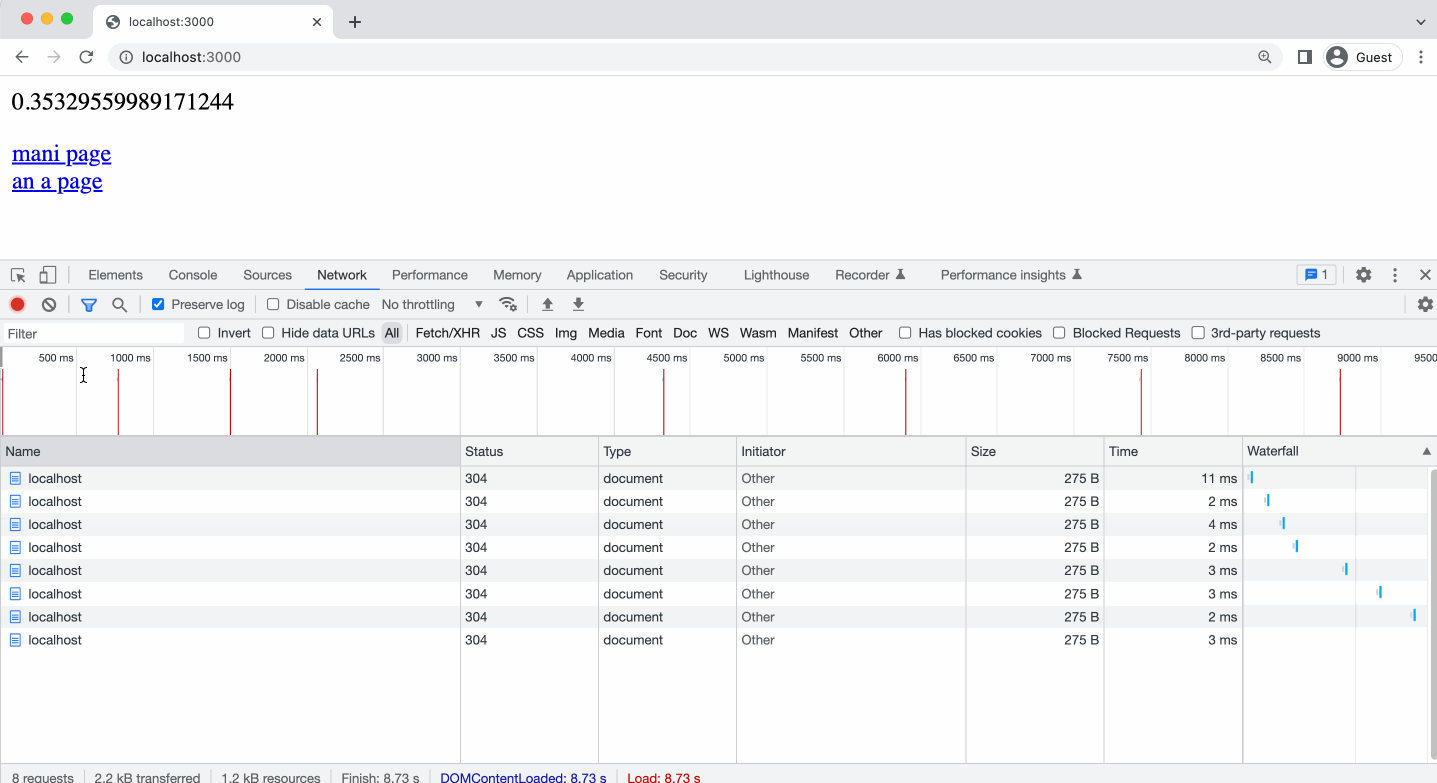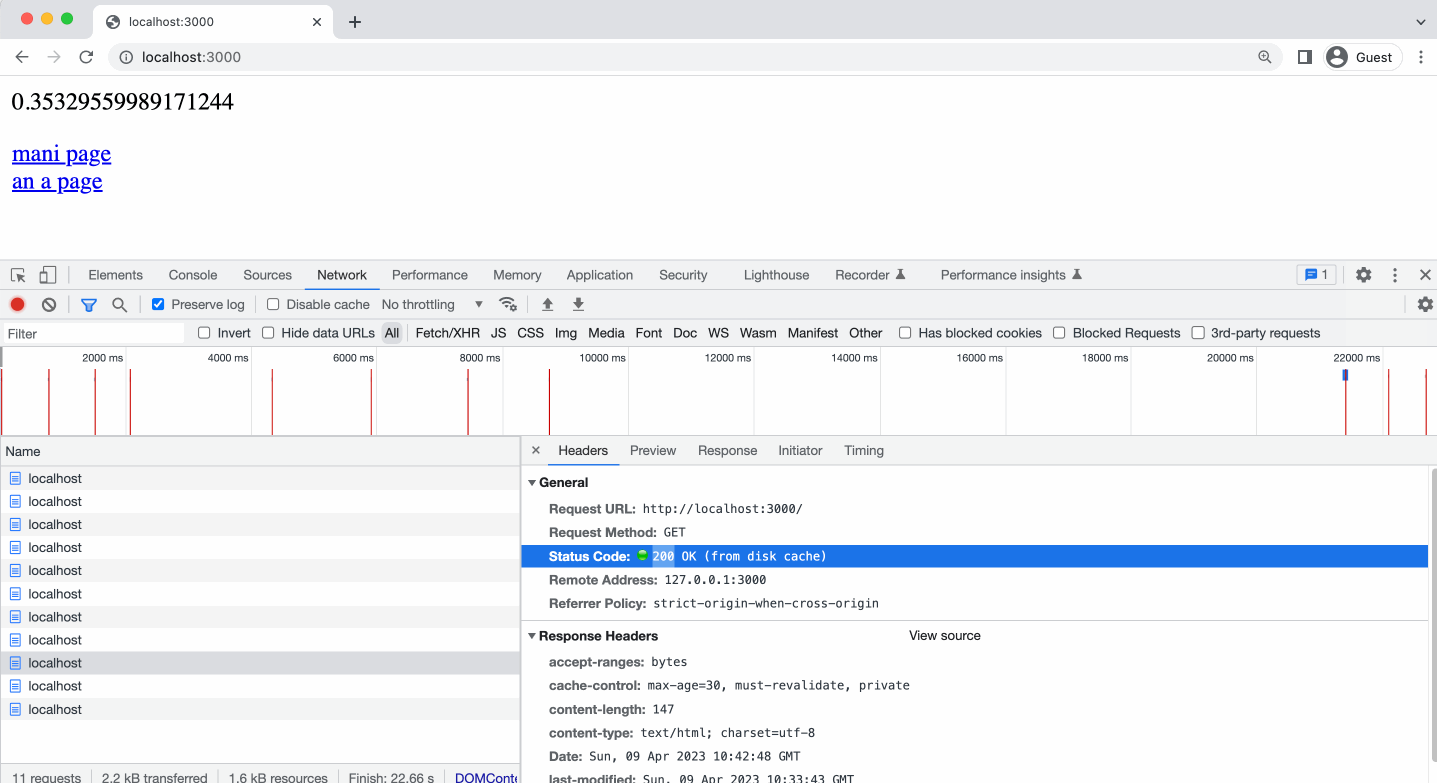
Обратите внимание, на то что, когда я выполняю клик в адресной строке и нажимаю клавишу Enter, браузером Chrome это воспринимается как принудительная перезагрузка страницы - мы видим в ответе 304-й статус.
А вот в Firefox поведение немного отличается. Перезагрузка на кнопку Reload this Page так же приводит к статусу 304, если переходим по ссылкам видим ответ 200 - то есть берем данные из Кеша, вот только в отличие от Chrome в блоке информации о кешированном запросе мы видим секцию Request Headers хотя запроса не было. С одной стороны это хорошо, так как мы можем посмотреть заголовки запроса, а с другой стороны может вводить в заблуждение.
Еще одним отличием является то, что при клике в адресной строке и перезагрузки страницы при помощи клавиши Enter не воспринимается браузером Firefox как принудительный запрос, и мы видим статус 200 - данные взяты из кеша.
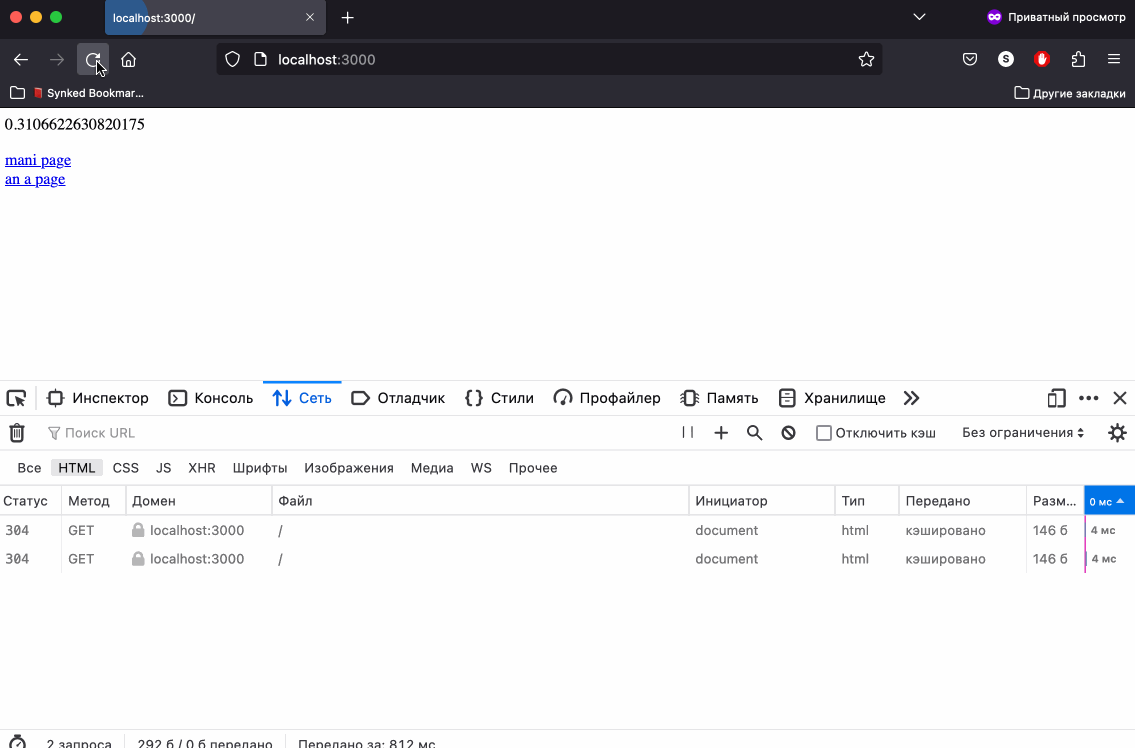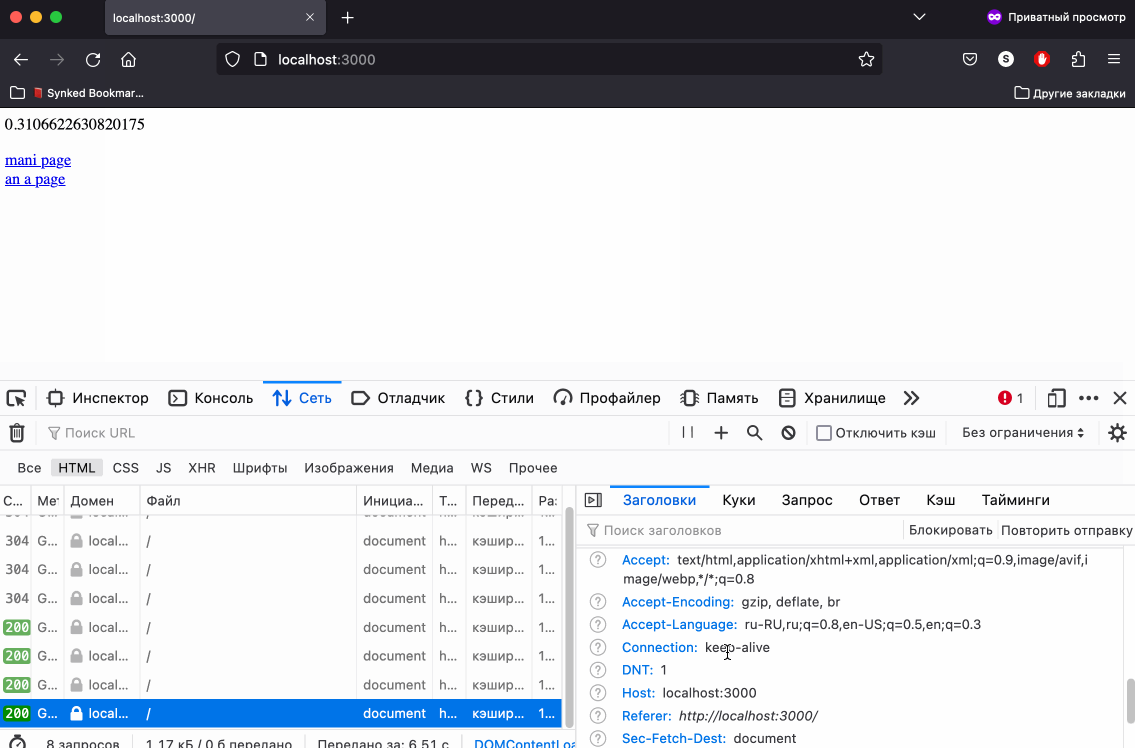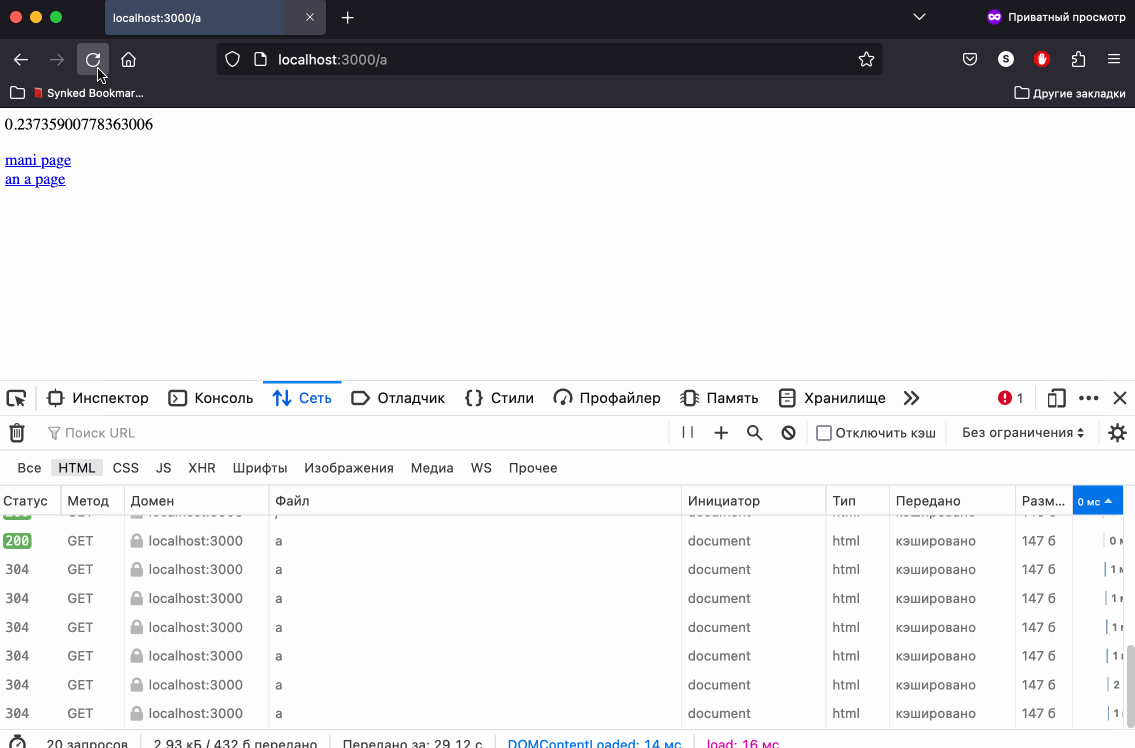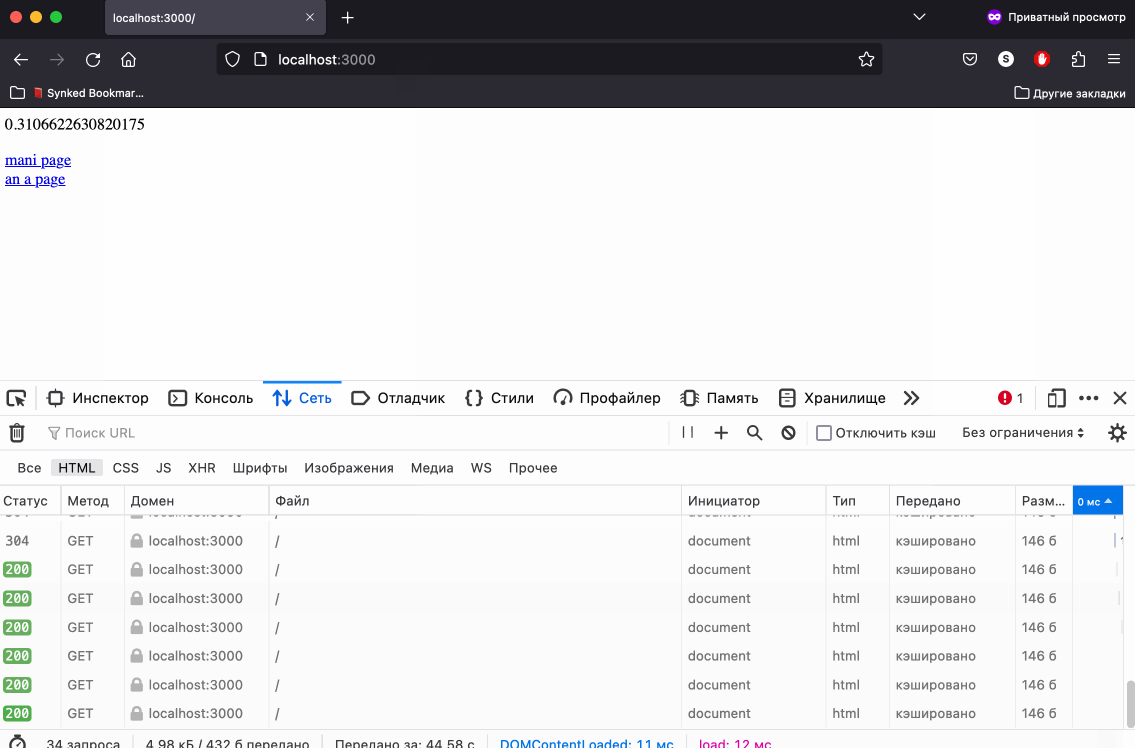
Поведение в Safari так же отличается. Как я сказал ранее, при принудительной перезагрузке, то есть при нажатии кнопки Reload this Page, Safari не отправляет на сервер заголовок If-Modified-Since, что не позволяет сравнить даты модификации ресурса и заставляет сервер генерировать новый контент постоянно. Перезагрузка кликом в адресной строке так же воспринимается как принудительная перезагрузка страницы. Мы видим статусы 200 в ответах, а на веб странице постоянно новые случайные числа.
Если же мы начинаем переходить по заготовленным ссылкам, кеш начинает работать. Мы видим надпись Кешировано в колонке Передано и статус 200. При этом в секции Request, в информации о запросе, видим надпись - No request, served from the memory cache.
Что касается Postman, то его запросы так же не кешируются. Да, в нем могут быть получены заголовки и пересланы на сервер, как если бы кеш был, но по факту, каждый запрос является принудительным.
Вывод по заголовкам. Все эти заголовки от сервера, управляющие Кешем на стороне клиента, хоть и задают нужное поведение браузера, но являются рекомендательными, и никто не гарантирует как именно закешируются данные на клиенте. Производители браузеров сами решают, как именно обрабатывать такие заголовки, ведь в спецификации указано, что означают заголовки, но не указывается как именно они должны работать. К тому же производители браузеров неоднократно нарушали рекомендации, и поведение может измениться в будущем. Остается самостоятельно изучать и "Держать руку на пульсе".
Заключение
Давайте резюмируем.
Мы хотим указать клиенту (браузеру) закешировать ресурс.
Для этого, в ответе от сервера необходимо прислать заголовок Cache-Control: max-age=30, где 30 это время в секундах, когда кеш будет работать.
Если вы будете запрашивать ресурс без принудительного запроса (не нажимать кнопку Reload This Page или перезагружать страницу через адресную строку), то тогда данные ресурса будут браться из кеша.
Ответ будет 200, и в devtools мы явно увидим, что ресурс взят из кеша.
После того как 30 секунд выйдут и вы снова произведете запрос за ресурсом, браузер выполнит запрос на сервер, получит ответ 200, получит новый ресурс в теле ответа и заголовок Cache-Control: max-age=30 установит новый Кеш.
Тут тоже можно сэкономить. Если при установке кеша, вместе с заголовком Cache-Control: max-age=30 установить заголовок Last-Modified: Sun, 09 Apr 2023 11:52:22 GMT (дата последней модификации ресурса) то клиент сохранит эту дату вместе с кешем.
Когда кеш протухнет, браузер сделает запрос на сервер за свежим ресурсом, при этом отправит дополнительный заголовок If-Modified-Since: Sun, 09 Apr 2023 11:52:22 GMT с тем же значением даты. Таким образом сервер может сравнить, дату модификации своего файла, и дату модификации в кеше. Если они одинаковы, то нет смысла пересылать тело запроса еще раз, ведь в Кеше браузера все еще есть подходящие данные (после истечения срока жизни кеша данные не удаляются из браузера - политики хранения кеша в браузерах - отдельная тема для изучения).
В таком случае сервер меняет статус ответа на 304. При этом отправляет остальные заголовки нетронутыми, в том числе заголовок Last-Modified, что позволяет снова продлить время жизни Кеша.
Из особенностей браузеров стоит отметить, что кнопка Reload This Page игнорирует свежий Кеш и делает принудительный запрос на сервер каждый раз. В Postman запросы всегда принудительные. Так же в браузерах отличается запрос при обновлении адреса в адресной строке.
На этом пока все. Продолжим наши страдания в следующей част
Ссылки на материалы:
Репозиторий с примерами: (https://github.com/Hydrock/article-hapi-caching/blob/main/examples/client-side/index.js)
Прекрасное видео о кешировании на сервере и клиенте (https://www.youtube.com/watch?v=HiBDZgTNpXY)
Кеширование в Hapi (https://hapi.dev/tutorials/caching/?lang=en_US)
Cache-Control MDN (https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cache-Control)
На этом видео показан Remix фреймворк, но тема видео связана с Кешем. (https://www.youtube.com/watch?v=3XkU_DXcgl0)
С чего начать изучение Python? Как развиваться?
Python является одним из самых популярных языков программирования в мире. Он широко используется в различных областях, таких как наука о данных, машинное обучение, разработка веб-приложений и многое другое. Если вы только начинаете изучать Python, вам нужно следовать некоторому Roadmap, который поможет вам улучшить ваши навыки в программировании.

Начните с основ
Первым шагом для изучения Python является ознакомление с его основами. Начните с изучения синтаксиса языка, переменных, операторов и типов данных. Ознакомьтесь с функциями в Python, которые используются для группировки блоков кода и повторного использования. Изучите структуры данных, такие как списки, кортежи, словари и множества.
Изучайте модули и пакеты
Python имеет обширную библиотеку модулей и пакетов, которые могут быть использованы для различных целей. Изучайте различные модули, которые входят в стандартную библиотеку Python, такие как os, sys, re и другие. Вы также можете изучить библиотеки, которые специализируются на конкретных областях, таких как NumPy, Pandas, Matplotlib для работы с данными и многое другое.
Создавайте свои проекты
Один из лучших способов научиться Python - это создание своих проектов. Начните с простых задач, таких как создание программы для расчета факториала или простого калькулятора. Вы можете также создавать более сложные приложения, такие как веб-приложения, игры и многое другое.
Изучайте концепции асинхронного программирования
Python имеет множество возможностей для асинхронного программирования, что делает его идеальным для работы с сетевыми приложениями и веб-серверами. Изучайте концепции, такие как асинхронность и параллельность.
Заключение
Python - это мощный язык программирования с обширной библиотекой модулей и пакетов, который может быть использован в различных областях. Если вы только начинаете изучать Python, следуйте Roadmap, который поможет вам улучшить ваши навыки программирования. Начните с основ, изучайте модули и пакеты, создавайте свои проекты, изучайте машинное обучение и науку о данных, а также концепции асинхронного программирования. Python предоставляет огромные возможности для программирования и вам понравится работать с этим языком.
Как написать телеграм бота на питоне?
Без лишних слов. Сразу приступим к делу.

Для написания телеграм бота на Python, вам необходимо выполнить следующие шаги:
1. Создайте нового бота в Telegram, написав в Telegram боте @BotFather команду /newbot и следуя инструкциям. При создании бота вам нужно будет придумать ему имя - для примера я создам бота с именем python-telegram-bot. У вас имя будет другое. В конце создания бота - вы получите токен - сохраните его на вашем устройстве.
2. Установите библиотеку python-telegram-bot, используя команду pip install python-telegram-bot в консоли вашего компьютера.
Чтобы открыть командную строку на Windows, в поиске найдите прогрумму CMD и запустите ее.
3. Запустите редактор Visual Studio Code (либо любой другой) и создайте файл main.py
4. Импортируйте необходимые библиотеки в файл main.py:
1from telegram import Update
2from telegram.ext import ApplicationBuilder, CommandHandler, ContextTypes5. Создайте переменную token и поместите в нее строку токена полученного от @BotFather
1token = "ваш токен"6. Создайте функцию для обработки команды hello - данная функция будет отвечать пользователю строкой Hello с именем пользователя
1async def hello(update: Update, context: ContextTypes.DEFAULT_TYPE) -> None:
2 await update.message.reply_text(f'Hello {update.effective_user.first_name}')7. Следующей командой создаем инстанс бота с использованием токена
1app = ApplicationBuilder().token(token).build()8. Добавляем обработчик команды /hello в вашем боте - для этого мы и готовили функцию hello выше.
1app.add_handler(CommandHandler("hello", hello))9. Наконец запускаем бота
1app.run_polling()Пока программа запущена - найдите вашего бота в telegram - и отправьте вашему боту команду /hello
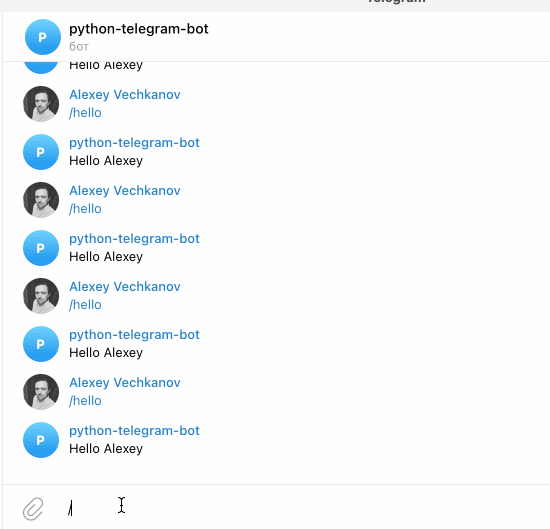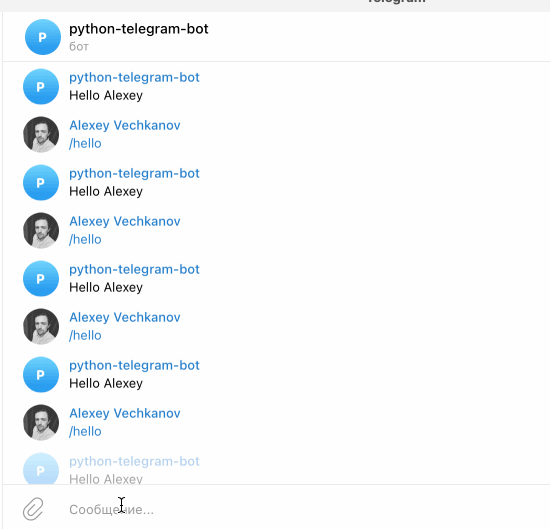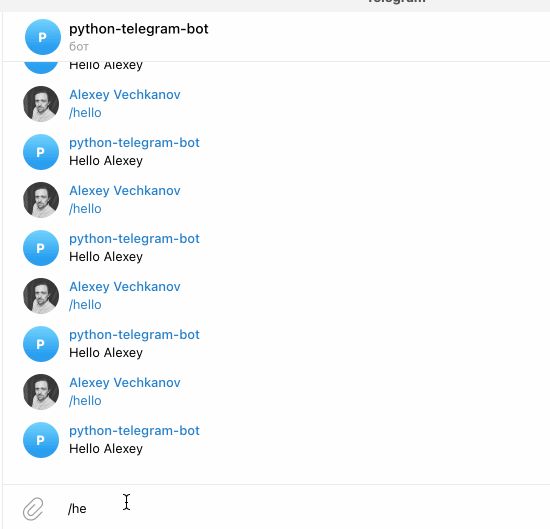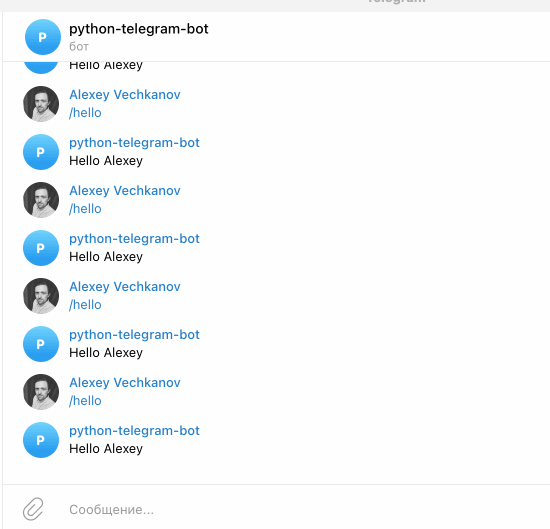
Поздравляю! Вы написали своего первого бота. Попробуйте написать другие фунциии и зарегистрировать новые команды.
Итоговый код - должен выглядеть примерно так:
1from telegram import Update
2from telegram.ext import ApplicationBuilder, CommandHandler, ContextTypes
3
4token = "ваш токен"
5
6# Функция отвечает пользователю Hello с указанием имени пользователя
7async def hello(update: Update, context: ContextTypes.DEFAULT_TYPE) -> None:
8 await update.message.reply_text(f'Hello {update.effective_user.first_name}')
9
10
11app = ApplicationBuilder().token(token).build()
12
13app.add_handler(CommandHandler("hello", hello))
14
15app.run_polling()
16Нагрузочное тестирование API NodeJS с помощью Autocannon
Как разработчики, мы всегда заботимся о времени отклика API, чтобы оно не могло стать узким местом для потребителей. Поэтому нам необходимо гарантировать, что время отклика не повлияет на производительность приложения, даже если несколько пользователей используют его одновременно.

Тесты всегда являются неотъемлемой частью приложения, обеспечивающей его бесперебойную работу. Как мы можем протестировать наши API, которые будут поддерживать одновременные запросы пользователей? — Autocannon, пакет нагрузочного тестирования, может имитировать высокий трафик в нашем приложении.
Autocannon
Autocannon — это инструмент для сравнительного анализа HTTP/1.1, написанный на NodeJS и широко используемый для измерения производительности приложения. С помощью autocannon мы можем моделировать несколько запросов в секунду для нагрузочного тестирования нашего приложения.
Кстати, cannon переводится как пушка, орудие (не путать с компанией Canon, а вот звучат слова одинаково), ну а autocannon - автопушка соответственно.
Установка
Установите autocannon глобально.
1npm install -g autocannonКоманда тестирования
1autocannon [opts] URL
2Доступные опции
Больше опций вы можете найти здесь.
1-c | --connections: Устанавливает количество одновременных соединений к серверу. Это основной параметр для моделирования нагрузки, поскольку он определяет, сколько клиентов будет одновременно подключено к серверу во время теста.
2
3-p | --pipeline: Определяет количество HTTP-запросов, которые будут отправлены в одном соединении без ожидания ответа на предыдущий запрос, имитируя HTTP/1.1 pipelining. Этот параметр позволяет увеличить интенсивность нагрузки и эффективность тестирования за счет уменьшения задержек, связанных с латентностью сети.
4
5-d | --duration: Задает продолжительность теста в секундах. Этот параметр определяет, насколько долго будет выполняться нагрузочный тест.
6
7-w | --workers: Устанавливает количество работников (worker threads), используемых для выполнения теста. Работники выполняются в отдельных потоках и могут помочь улучшить производительность тестирования на многоядерных системах.
8
9-m | --method: Позволяет указать HTTP-метод, который будет использоваться при отправке запросов. По умолчанию используется метод GET, но с помощью этого параметра можно выбрать любой другой метод, например POST, PUT, DELETE и так далее.
10
11-t | --timeout: Устанавливает таймаут в миллисекундах для HTTP-запросов. Если сервер не отвечает в течение указанного времени, запрос будет считаться неудачным. Этот параметр помогает определить, как долго клиент готов ждать ответа от сервера перед тем, как отметить запрос как неудачный.
12
13-j | --json: Выводит результаты теста в формате JSON. Это полезно для анализа результатов программно или для их интеграции с другими инструментами.
14
15-f | --forever: Заставляет autocannon выполнять тесты бесконечно или до тех пор, пока тест не будет прерван вручную. Этот режим полезен для долгосрочного тестирования стабильности и выявления утечек памяти или других проблем, которые могут проявиться только при длительной нагрузке.Практика - Командная строка
Выполните следующую команду в терминале:
1autocannon -с 100 -d 5 -p 10 https://google.comЕсли при запуске команды вы встретите ошибку запрета на запуск отключенных в системе сценариев (только Windows), установите политику выполнения следующим образом:
1Set-ExecutionPolicy -Scope CurrentUser -ExecutionPolicy Unrestricted
2Данная команда используется в PowerShell для изменения политики выполнения скриптов для текущего пользователя. Параметр -ExecutionPolicy Unrestricted указывает, что можно запускать любые скрипты, включая скрипты, скачанные из Интернета, что может представлять потенциальную угрозу безопасности, если скрипты не являются доверенными. Параметр -Scope CurrentUser означает, что изменения политики выполнения будут применяться только к текущему пользователю, не влияя на других пользователей системы или на глобальную политику выполнения скриптов в системе.
Вы должны увидеть примерно сдедущий отчет:
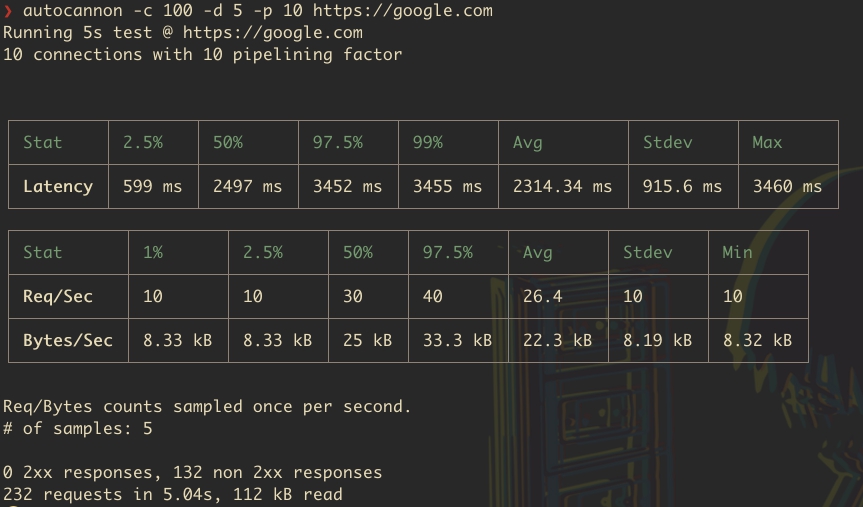
- autocannon: Это команда для запуска `autocannon`, начинающая тест производительности.
- -c 100: Этот параметр указывает количество одновременных подключений к серверу. В данном случае `-c 100` означает, что `autocannon` будет поддерживать 100 одновременных подключений к целевому серверу во время теста.
- -d 5: Задает длительность теста в секундах. -d 5 означает, что нагрузочный тест будет продолжаться 5 секунд.
- -p 10: Устанавливает период ожидания в миллисекундах между запросами для каждого подключения. В данном случае `-p 10` означает, что будет 10 миллисекунд паузы между запросами, сделанными одним подключением. Это помогает немного разгрузить сервер, делая тест более реалистичным по сравнению с беспрерывной отправкой запросов.
- https://google.com: Целевой URL, к которому `autocannon` будет направлять запросы. В данном случае тестируется производительность веб-сервера Google.
В совокупности, эта команда запускает нагрузочный тест, который в течение 5 секунд будет поддерживать 100 одновременных подключений к `https://google.com`, делая паузу в 10 мс между запросами каждого подключения. Это позволяет оценить, как сервер справляется с высокой нагрузкой, и измерить его производительность и способность обрабатывать множество одновременных запросов.
Autocannon, по завершению теста выводит две таблицы данных:
1. Request Latency (Задержка запроса)
2. Request Volume (Объем запроса)
Давайте рассмотрим их подробнее.
Request Latency (Задержка запросов)
Эта таблица показывает время отклика вашего API. Здесь приводятся различные метрики, которые описывают, как быстро сервер отвечает на запросы. Обычно здесь указываются:
Min: Минимальное время отклика за время теста.
Max: Максимальное время отклика за время теста.
Median: Медианное время отклика. Это означает, что половина запросов была обработана быстрее данного времени, а другая половина - медленнее.
Average: Среднее время отклика.
Percentiles: Процентили показывают время отклика в определенном проценте запросов. Например, 95-й процентиль означает, что 95% запросов были обработаны за это время или быстрее.
Давайте разберем на конкретном примере:
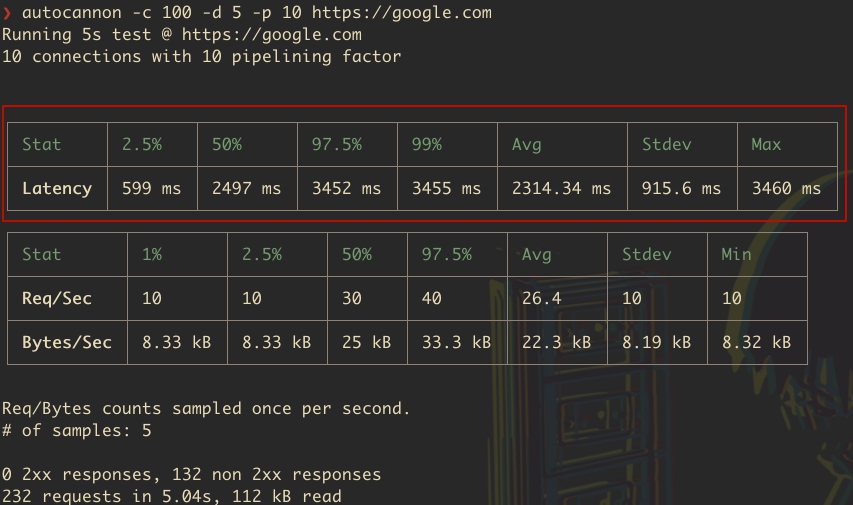
- Stat: Это заголовок колонки, указывающий на то, что в строках ниже будут представлены статистические данные по задержкам.
- 2.5%: Значение задержки в 66 мс означает, что 2.5% запросов имели задержку 66 мс или меньше. Это показывает минимальную задержку, с которой сталкивалось очень маленькое число запросов.
- 50% (Медиана): Значение в 77 мс указывает, что половина всех запросов была выполнена с задержкой 77 мс или меньше. Это наиболее типичное значение задержки для вашего API.
- 97.5%: 169 мс означает, что 97.5% запросов имели задержку 169 мс или меньше. Это дает представление о верхнем пределе задержек для большинства запросов.
- 99%: 1396 мс показывает, что 99% запросов обрабатывались с задержкой 1396 мс или меньше. Это значение говорит о том, что лишь 1% запросов испытывал задержки, превышающие данное значение, что может указывать на наличие некоторых очень медленных запросов.
- Avg (Average / Среднее): Средняя задержка составила 110.63 мс. Это значение рассчитывается путем деления суммы всех задержек на количество запросов и дает общее представление о том, с какой задержкой обрабатываются запросы в среднем.
- Stdev (Standard deviation / Стандартное отклонение): Стандартное отклонение задержки равно 194.86 мс. Это показывает, насколько разнообразными были задержки запросов. Большое стандартное отклонение указывает на то, что время отклика API сильно варьировалось.
- Max (Максимум): Максимальная зафиксированная задержка составила 1450 мс. Это значение показывает максимальное время отклика, которое было зафиксировано во время теста.
Итак, эти данные демонстрируют, что большинство запросов обрабатывалось довольно быстро (до 169 мс для 97.5% запросов), но существовали исключения, когда время отклика значительно возрастало (до 1396 мс для 1% запросов и максимум 1450 мс). Это может указывать на потенциальные проблемы с производительностью или стабильностью для определенных типов запросов или в определенных условиях.
Request Volume (Объем запросов)
Таблица Request Volume показывает статистику по количеству запросов в секунду (Req/Sec) и объему переданных данных в секунду (Bytes/Sec) в ходе тестирования API. Давайте подробно разберем значения:
Давайте так же рассмотрим на примере:
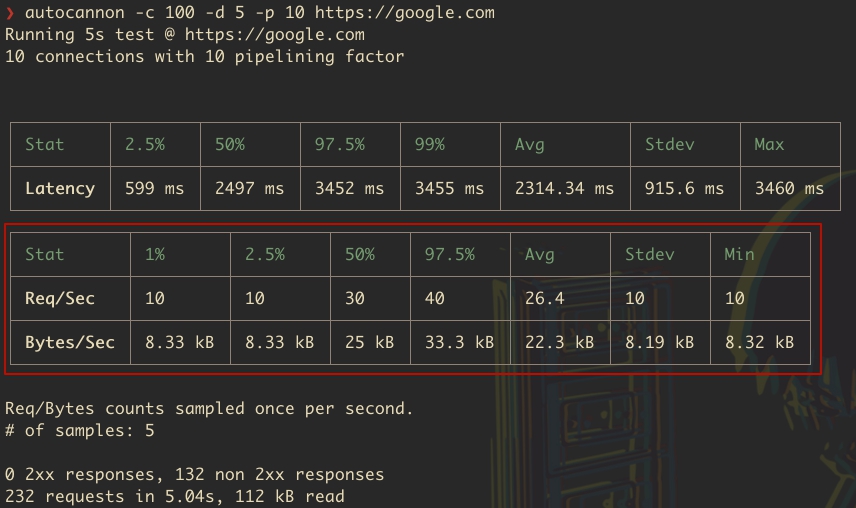
Req/Sec (Запросы в секунду)
1%: Минимальное количество запросов в секунду, которое система смогла обработать, составляет 10. Это означает, что даже в худших условиях производительности, 1% результатов был не ниже 10 запросов в секунду.
2.5%: Также 10 запросов в секунду, указывая на то, что хотя бы 2.5% времени система обрабатывала не менее 10 запросов в секунду.
50% (Медиана): В половине случаев система обрабатывала 30 запросов в секунду, что является наиболее типичным показателем производительности системы во время теста.
97.5%: В 97.5% случаев система обрабатывала не более 40 запросов в секунду, что указывает на верхний предел производительности системы под нагрузкой.
Avg (Среднее): В среднем, система обрабатывала 26.4 запроса в секунду.
Stdev (Стандартное отклонение): Стандартное отклонение равно 10, что говорит о вариативности количества обрабатываемых запросов в секунду во время теста.
Min (Минимум): Минимальное количество запросов в секунду в ходе всего теста составило 10.
Bytes/Sec (Байты в секунду)
1%: Минимальный объем данных, переданных в секунду, составляет 8.33 кБ. Это означает, что в худших 1% случаев объем переданных данных не опускался ниже этого значения.
2.5%: Такой же объем данных, как и для 1%, указывает на минимальный уровень производительности системы в плане передачи данных.
50% (Медиана): В половине случаев система передавала 25 кБ данных в секунду.
97.5%: В 97.5% случаев объем переданных данных не превышал 33.3 кБ в секунду.
Avg (Среднее): В среднем, система передавала 22.3 кБ данных в секунду.
Stdev (Стандартное отклонение): Стандартное отклонение равно 8.19 кБ, что указывает на вариативность объема переданных данных в секунду.
Min (Минимум): Минимальный объем данных, переданный в секунду во время всего теста, составил 8.32 кБ.
Данные из этой таблицы дают понимание о производительности и пропускной способности вашего API, показывая, как система справляется с нагрузкой как в плане количества обрабатываемых запросов, так и в плане объема передаваемых данных.
Заключение по таблицам
Обе таблицы важны для оценки производительности и надежности вашего API. Задержка запросов показывает, насколько быстро API отвечает на запросы, что критически важно для пользовательского опыта. Объем запросов дает представление о том, как ваш API справляется с нагрузкой, насколько он устойчив и способен обрабатывать большое количество запросов без сбоев.
Завершающая часть отчета
Завершающая часть отчета `autocannon`, которую мы видим на изображении, содержит важную информацию о результатах тестирования.
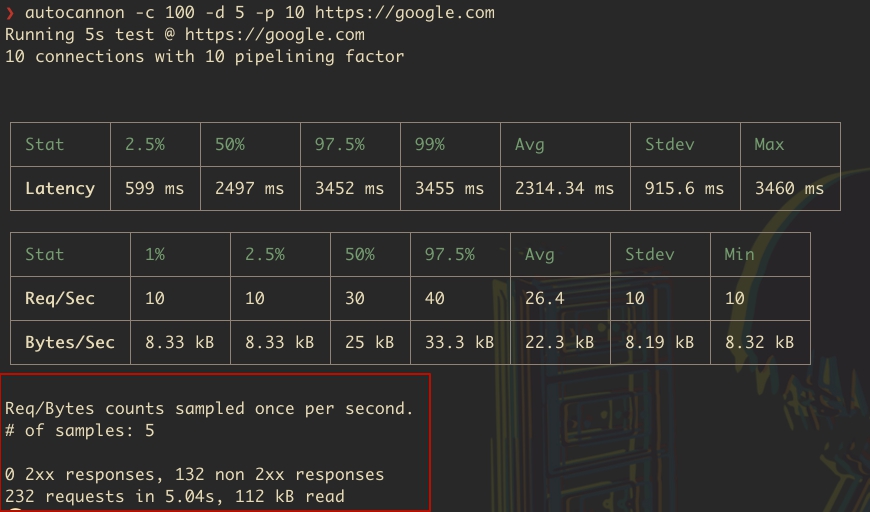
Давайте разберем отчет подробно:
- Req/Bytes counts sampled once per second: Это означает, что количество запросов и объем переданных данных измерялись один раз в секунду в течение всего теста.
- # of samples: 5: Указывает на количество измерений (или выборок), сделанных во время теста. Поскольку тест длился 5 секунд, было сделано 5 измерений. Это соответствует периодичности измерений в одну секунду.
- 0 2xx responses: Показывает количество успешных HTTP-ответов, полученных во время теста. Коды состояния 2xx означают успешную обработку запроса сервером. В данном случае успешных ответов не было.
- 132 non 2xx responses: Указывает на количество ответов, которые не относятся к категории успешных (то есть все, кроме 2xx). Это могут быть ответы с кодами 3xx (перенаправления), 4xx (ошибки клиента) и 5xx (ошибки сервера). В вашем тесте было получено 132 таких ответа.
- 232 requests in 5.04s: Общее количество выполненных запросов за время теста, которое составило 5.04 секунды, было 232. Это дает представление о нагрузке, которую тестирование создавало на сервер.
- 112 kB read: Объем данных, прочитанных в ходе теста, составил 112 килобайт. Это включает в себя данные всех полученных ответов, включая тела ответов и заголовки.
Эта часть отчета дает общее представление о производительности и поведении сервера во время теста. Отсутствие успешных ответов (2xx) может указывать на проблемы с доступностью или конфигурацией сервера во время тестирования. Полученные неуспешные ответы (non 2xx responses) требуют дополнительного анализа для выяснения причин: это могут быть временные или постоянные ошибки сервера, проблемы с маршрутизацией запросов или другие технические неполадки.
Практика - Программно
Autocannon можно использовать не только как инструмент командной строки, но и программно в вашем коде на Node.js. Это позволяет интегрировать нагрузочное тестирование напрямую в ваши приложения или тестовые сценарии, обеспечивая большую гибкость и возможность автоматизации.
Программный запуск autocannon дает возможность динамически конфигурировать параметры тестирования, обрабатывать результаты испытаний на лету и интегрировать нагрузочное тестирование в более широкие процессы CI/CD (Continuous Integration/Continuous Deployment).
Вот базовый пример использования autocannon программно:
1const autocannon = require('autocannon');
2const { promisify } = require('util');
3
4// Превращаем autocannon в Promise для использования с async/await
5const autocannonPromise = promisify(autocannon);
6
7async function runBenchmark() {
8 try {
9 const result = await autocannonPromise({
10 url: 'https://google.com',
11 connections: 10, // количество одновременных соединений
12 duration: 5, // продолжительность теста в секундах
13 // другие параметры по желанию
14 });
15
16 console.log('Результат тестирования:', result);
17 // Обработка результатов тестирования
18 } catch (err) {
19 console.error('Ошибка при выполнении нагрузочного тестирования:', err);
20 }
21}
22
23runBenchmark();
24В этом примере мы используем `autocannon` для программного запуска нагрузочного теста, указывая URL для тестирования, количество одновременных соединений и продолжительность теста. После завершения теста результаты выводятся в консоль. Вот мой результат этого теста:
1Результат тестирования: {
2 title: undefined,
3 url: 'https://google.com',
4 socketPath: undefined,
5 connections: 10,
6 sampleInt: 1000,
7 pipelining: 1,
8 workers: undefined,
9 duration: 5.04,
10 samples: 5,
11 start: 2024-02-13T20:04:56.464Z,
12 finish: 2024-02-13T20:05:01.500Z,
13 errors: 0,
14 timeouts: 0,
15 mismatches: 0,
16 non2xx: 110,
17 resets: 0,
18 '1xx': 0,
19 '2xx': 0,
20 '3xx': 110,
21 '4xx': 0,
22 '5xx': 0,
23 statusCodeStats: { '301': { count: 110 } },
24 latency: {
25 average: 426.13,
26 mean: 426.13,
27 stddev: 63.82,
28 min: 376,
29 max: 604,
30 p0_001: 376,
31 p0_01: 376,
32 p0_1: 376,
33 p1: 377,
34 p2_5: 377,
35 p10: 380,
36 p25: 381,
37 p50: 402,
38 p75: 453,
39 p90: 484,
40 p97_5: 603,
41 p99: 603,
42 p99_9: 604,
43 p99_99: 604,
44 p99_999: 604,
45 totalCount: 110
46 },
47 requests: {
48 average: 22,
49 mean: 22,
50 stddev: 4,
51 min: 20,
52 max: 30,
53 total: 110,
54 p0_001: 20,
55 p0_01: 20,
56 p0_1: 20,
57 p1: 20,
58 p2_5: 20,
59 p10: 20,
60 p25: 20,
61 p50: 20,
62 p75: 20,
63 p90: 30,
64 p97_5: 30,
65 p99: 30,
66 p99_9: 30,
67 p99_99: 30,
68 p99_999: 30,
69 sent: 120
70 },
71 throughput: {
72 average: 18312,
73 mean: 18312,
74 stddev: 3328,
75 min: 16640,
76 max: 24960,
77 total: 91520,
78 p0_001: 16655,
79 p0_01: 16655,
80 p0_1: 16655,
81 p1: 16655,
82 p2_5: 16655,
83 p10: 16655,
84 p25: 16655,
85 p50: 16655,
86 p75: 16655,
87 p90: 24975,
88 p97_5: 24975,
89 p99: 24975,
90 p99_9: 24975,
91 p99_99: 24975,
92 p99_999: 24975
93 }
94}Давайте разберем этот отчет.
Разбор программного отчета
1. Общие параметры теста:
- Было использовано 10 одновременных соединений.
- Продолжительность теста составила около 5.04 секунды.
- Всего было сделано 5 измерений (раз в секунду).
- Тест начался в 20:04:56 и завершился в 20:05:01 по UTC 13 февраля 2024 года.
2. Результаты по HTTP-ответам:
- Все 110 полученных ответов были с кодом 3xx (перенаправления), что указывает на то, что все запросы были перенаправлены. Конкретно, все ответы были с кодом 301 (Permanent Redirect).
- Не было зафиксировано ни одного успешного ответа с кодом 2xx, что связано с тем, что google.com, вероятно, выполняет перенаправление на версию сайта с HTTPS или на локализованную версию.
- Ошибок, таймаутов, несоответствий и сбросов соединений не было.
3. Статистика задержек:
- Средняя задержка составила 426.13 мс с минимальной задержкой в 376 мс и максимальной в 604 мс. Это показывает временные рамки отклика сервера на запросы.
- Стандартное отклонение задержек составило 63.82 мс, что указывает на относительную стабильность времени отклика во время теста.
4. Статистика запросов:
- В среднем обрабатывалось 22 запроса в секунду с минимумом в 20 и максимумом в 30 запросов. Всего было выполнено 110 запросов.
- Стандартное отклонение по количеству запросов в секунду составило 4, что также подтверждает относительную стабильность производительности во время тестирования.
5. Статистика пропускной способности:
- Средняя пропускная способность составила 18312 байт в секунду (приблизительно 17.9 кБ/с) с минимумом в 16640 байт и максимумом в 24960 байт. Общий объем переданных данных составил 91520 байт (приблизительно 89.4 кБ).
- Стандартное отклонение пропускной способности было 3328 байт, что говорит о некотором разнообразии в объемах передаваемых данных между различными интервалами измерения.
Эти результаты показывают, как сервер обрабатывал запросы во время нагрузочного теста, включая информацию о задержках, количестве и типах ответов, а также пропускной способности. Отсутствие ответов 2xx и наличие только ответов 301 указывает на то, что для тестирования потребуется учитывать перенаправления, особенно при работе с веб-сайтами, которые используют HTTPS или имеют специфические правила для перенаправления запросов.
Заключение по программному запуску нагрузки
Этот метод позволяет интегрировать нагрузочное тестирование в автоматизированные тестовые сценарии и процессы разработки, предоставляя возможность детально анализировать производительность приложений и сервисов.
Workers
Параметр workers используется для указания количества воркеров (рабочих потоков), которые будут созданы для выполнения нагрузочного тестирования. Этот параметр позволяет эффективнее использовать многоядерные процессоры, распределяя нагрузку по различным ядрам и тем самым увеличивая общую производительность тестирования.
Пример запуска теста в 4-х потоках:
1const autocannon = require('autocannon')
2
3autocannon({
4 url: 'https://google.com',
5 connections: 10, //default
6 pipelining: 1, // default
7 duration: 10, // default
8 workers: 4
9}, console.log)Как работают воркеры в autocannon:
Многопоточность: Node.js основан на однопоточной модели событийного цикла, но с помощью воркеров можно использовать дополнительные потоки для выполнения кода параллельно. Это особенно полезно для операций, требующих интенсивных вычислений или блокирующих выполнение, таких как нагрузочное тестирование.
Распределение нагрузки: Использование воркеров позволяет autocannon распределять нагрузку между несколькими потоками, что увеличивает общее количество запросов, которое может быть отправлено и обработано за единицу времени.
Изоляция: Каждый воркер выполняется в своем собственном контексте выполнения, изолированно от основного потока и других воркеров. Это значит, что задачи, выполняемые воркерами, не будут влиять на производительность основного потока приложения.
Когда использовать параметр workers:
Тестирование производительности высоконагруженных систем: Если вы хотите максимально реалистично симулировать нагрузку на сервер, использование нескольких воркеров позволит более эффективно использовать ресурсы тестовой машины.
Использование многоядерных процессоров: На машинах с многоядерными процессорами использование нескольких воркеров может значительно улучшить производительность нагрузочного тестирования, поскольку каждый воркер может быть выполнен на отдельном ядре.
Тестирование приложений с высокой параллельной обработкой: В сценариях, где тестируемое приложение оптимизировано для работы с множеством параллельных запросов, использование воркеров может помочь более точно оценить его производительность.
Заключение по Workers
Использование параметра workers в autocannon является продвинутой функцией, которая может помочь в создании более мощных и настроенных под конкретные нужды сценариев нагрузочного тестирования. Однако стоит помнить, что увеличение количества воркеров также увеличивает потребление системных ресурсов, таких как CPU и память, что может повлиять на результаты тестирования.
Тестирование нескольких URL
С помощью autocannon, вы можете выполнить тестирование нескольких URL за один запуск, создав массив запросов. Это особенно полезно, когда вам нужно тестировать различные эндпоинты API или страницы веб-сайта в рамках одного сеанса нагрузочного тестирования.
Чтобы выполнить тестирование нескольких URL, вы должны использовать программный подход, так как CLI (интерфейс командной строки) autocannon по умолчанию поддерживает тестирование только одного URL за раз. В программной версии вы можете определить массив запросов, где каждый запрос будет содержать разные параметры, включая URL.
Вот пример кода на Node.js, который демонстрирует, как это можно сделать:
1const autocannon = require('autocannon');
2const { promisify } = require('util');
3const autocannonPromise = promisify(autocannon);
4
5async function runBenchmark() {
6 try {
7 const result = await autocannonPromise({
8 url: 'http://example.com', // базовый URL, может быть переопределен в setupRequest
9 connections: 10, // количество одновременных соединений
10 duration: 10, // продолжительность теста в секундах
11 // Определение массива запросов
12 requests: [
13 {
14 method: 'GET', // метод HTTP запроса
15 path: '/', // путь относительно базового URL
16 // Здесь можно добавить тело запроса, заголовки и т.д.
17 },
18 {
19 method: 'GET',
20 path: '/about',
21 },
22 {
23 method: 'POST',
24 path: '/api/data',
25 body: JSON.stringify({ data: 'example' }), // тело запроса
26 headers: { 'Content-Type': 'application/json' }, // заголовки запроса
27 }
28 ],
29 // setupRequest и onResponse могут быть использованы для динамической настройки запросов и обработки ответов
30 });
31
32 console.log('Результат тестирования:', result);
33 } catch (err) {
34 console.error('Ошибка при выполнении нагрузочного тестирования:', err);
35 }
36}
37
38runBenchmark();
39В этом примере autocannon настроен на отправку запросов к трем разным путям (/, /about, /api/data) на http://example.com. Каждый запрос может быть настроен индивидуально, включая метод HTTP, путь, тело запроса и заголовки. Это позволяет тестировать различные аспекты вашего веб-приложения или API, используя один и тот же экземпляр autocannon.
Тонкая настройка запросов
1. Создание объектов клиента для соединений: Когда вы запускаете `autocannon`, он создает объекты клиента (Client) в количестве, соответствующем указанному вами числу соединений. Каждый из этих клиентов будет выполнять запросы параллельно друг другу в течение всего времени тестирования. Это время может быть ограничено либо длительностью теста, либо общим числом запросов.
2. Циклическая обработка массива запросов: Каждый клиент последовательно перебирает массив запросов, который может содержать один или несколько запросов. Это означает, что если в массиве указано несколько запросов, клиент будет отправлять их по очереди до тех пор, пока тест не будет завершен.
3. Поддержка контекста: Во время перебора запросов клиент поддерживает контекст — это специальный объект, который можно использовать для хранения и извлечения данных, специфичных для текущего цикла выполнения запросов. Этот контекст может быть полезен, например, для сохранения результатов предыдущих запросов и использования их в последующих запросах или для изменения поведения запросов на основе предыдущих ответов.
4. Функции `onResponse` и `setupRequest`: Вы можете использовать эти функции для работы с контекстом. Функция `setupRequest` позволяет настраивать запросы перед их отправкой, используя данные из контекста, а `onResponse` — обрабатывать ответы сервера, возможно, модифицируя контекст для следующих запросов.
5. Сброс контекста: Когда клиент завершает цикл по массиву запросов и возвращается к первому запросу для повторной отправки, контекст сбрасывается. Это делается для обеспечения одинаковых условий для каждого нового цикла запросов. Контекст будет сброшен к начальному состоянию (`initialContext`), предоставленному вами, или к пустому объекту `{}`, если начальный контекст не был указан.
Этот механизм контекста и настройки запросов предоставляет гибкие возможности для имитации сложных пользовательских сценариев и тестирования веб-приложений с учетом состояний и последовательностей запросов.
Комбинирование соединений, общей скорости и количества
Когда вы настраиваете `autocannon` для выполнения определенного количества HTTP-запросов (`amount`), используя фиксированное количество одновременных соединений (`connections`) с ограничением на общую скорость отправки запросов (`overallRate`), `autocannon` стремится равномерно распределить эту нагрузку между всеми соединениями. Это распределение включает в себя как количество запросов, так и скорость их отправки.
Распределение общей скорости (`overallRate`)
- Если значение `overallRate` (заданное в запросах в секунду для всего теста) не делится нацело на количество соединений (`connections`), `autocannon` будет настраивать часть соединений на отправку немного большего количества запросов в секунду, а другую часть — на отправку меньшего количества. Это делается для того, чтобы в сумме достичь заданной общей скорости.
Распределение количества запросов (`amount`)
- Если общее количество запросов (`amount`) делится нацело на количество соединений, каждое соединение получит одинаковое количество запросов для выполнения.
Влияние на воспринимаемую скорость запросов
- В случае неделимости `overallRate` на количество соединений, соединения с высшей скоростью отправки запросов завершат свою работу раньше остальных. Как результат, когда эти более быстрые соединения закончат отправлять свои запросы, общее количество активных запросов в секунду упадет, поскольку оставшиеся активные соединения будут отправлять меньше запросов. Это приведет к снижению воспринимаемой общей скорости запросов к концу теста.
Пример
Допустим, у нас есть следующие параметры: `connections = 10`, `overallRate = 17`, `amount = 5000`. Это означает, что `autocannon` будет стремиться распределить общее количество запросов (5000) между 10 соединениями таким образом, чтобы общая скорость запросов не превышала 17 запросов в секунду на все соединения вместе взятые. Если деление не нацело, некоторые соединения будут работать быстрее, а некоторые — медленнее, чтобы в сумме обеспечить заданную скорость.
Лимиты
В этом блоке поднимем важный вопрос о производительности и ограничениях при использовании инструмента для нагрузочного тестирования, особенно в сравнении с другими инструментами, такими как wrk и wrk2.
Процессорные Ресурсы
- Ограниченность процессорными ресурсами: `Autocannon`, как и любой инструмент, написанный на JavaScript и работающий в среде Node.js, активно использует процессорные ресурсы (CPU-bound). Это значит, что его производительность и способность генерировать нагрузку зависят от мощности и загрузки процессора.
Сравнение с `wrk`
- Потребление CPU: По сравнению с `wrk`, который компилируется в бинарный код и обычно использует меньше процессорного времени, `autocannon` может использовать значительно больше CPU для выполнения аналогичных задач нагрузочного тестирования. Пример с использованием 1000 соединений на 4-ядерном сервере с поддержкой Hyper-Threading демонстрирует, что `wrk` распределяет свою нагрузку более эффективно, используя несколько потоков, в то время как `autocannon` нагружает один поток на 80%.
Рекомендация использования `wrk2`
- Насыщение CPU: Если процесс `autocannon` достигает 100% использования CPU, это может повлиять на точность и надежность результатов тестирования. В таких случаях рекомендуется использовать `wrk2`, который может обеспечить более низкую и равномерную нагрузку на процессор.
Поддержка HTTP/1.1 Pipelining
- HTTP/1.1 Pipelining: Одним из преимуществ `autocannon` перед `wrk` является поддержка пайплайнинга HTTP/1.1, что позволяет `autocannon` создавать большую нагрузку на сервер за счет одновременной отправки нескольких HTTP-запросов в рамках одного соединения без ожидания ответа на каждый запрос. Это может быть особенно полезно при тестировании серверов и приложений, оптимизированных для работы с HTTP/1.1 pipelining.
Подводим итоги
`Autocannon` — мощный и гибкий инструмент, написанный на JavaScript для среды Node.js, который позволяет проводить комплексное тестирование производительности веб-приложений и API. Он предлагает широкий спектр настраиваемых параметров, включая поддержку HTTP/1.1 pipelining, возможность тестирования нескольких URL за один запуск и гибкое управление количеством запросов, соединений и продолжительностью теста.
Однако, как и любой инструмент, `autocannon` имеет свои ограничения, включая высокую нагрузку на CPU при интенсивном использовании, что может потребовать перехода к альтернативам, таким как `wrk2`, в определенных ситуациях. Несмотря на это, `autocannon` остается важным инструментом в арсенале разработчиков и тестировщиков благодаря его простоте использования, возможности интеграции в автоматизированные тестовые сценарии и глубокой настройке параметров тестирования.
Используя `autocannon`, команды могут лучше понять поведение и пределы своих систем под нагрузкой, выявлять узкие места и оптимизировать производительность, обеспечивая высококачественный пользовательский опыт. В конечном итоге, успешное нагрузочное тестирование — ключевой компонент в процессе разработки любого масштабируемого и надежного веб-приложения или сервиса, и `autocannon` предоставляет все необходимые инструменты для достижения этих целей.
Статью мне помогали писать:
1) Эта статья.
2) Документация autocannon.
3) ChatGPT
Как объединить коммиты в Git и зачем это нужно
Git — мощная система контроля версий, которая позволяет разработчикам отслеживать изменения в коде и сотрудничать над проектами. Однако в процессе работы история коммитов может стать запутанной из-за множества мелких или неинформативных коммитов. Объединение коммитов (squash) помогает привести историю в порядок, делая её более понятной и управляемой.

Зачем объединять коммиты
• Упорядочение истории: Объединение коммитов позволяет собрать связанные изменения в один коммит, делая историю проекта более чистой и логичной.
• Удобство для ревьюеров: Меньшее количество коммитов с ясными сообщениями облегчает код-ревью и понимание изменений.
• Избежание лишних конфликтов: При объединении веток меньшее количество коммитов снижает вероятность конфликтов.
Как объединить коммиты с помощью git rebase -i
Интерактивный rebase — мощный инструмент для изменения истории коммитов. Вот пошаговая инструкция:
1. Определите диапазон коммитов: Решите, сколько последних коммитов вы хотите объединить. Например, чтобы объединить последние 3 коммита, используйте HEAD~3.
2. Запустите интерактивный rebase:
1git rebase -i HEAD~33. Выберите коммиты для объединения: В открывшемся редакторе вы увидите список коммитов:
1pick abc123 Коммит 1
2pick def456 Коммит 2
3pick ghi789 Коммит 3Замените pick на squash или s для тех коммитов, которые хотите объединить с предыдущим:
1pick abc123 Коммит 1
2squash def456 Коммит 2
3squash ghi789 Коммит 34. Сохраните и закройте редактор: После этого Git предложит вам отредактировать сообщение итогового коммита.
5. Отредактируйте сообщение коммита: Вы можете объединить сообщения или написать новое.
6. Завершите rebase: Сохраните изменения, и Git применит объединение.
Объединение коммитов при слиянии веток
Объединение коммитов при слиянии веток
1git checkout main
2git merge --squash feature-branch
3git commit -m "Добавлена новая функциональность"Важно помнить
• Осторожность при работе с общими ветками: Изменение истории коммитов, которые уже отправлены в общий репозиторий, может привести к конфликтам с работой других разработчиков.
• Коммиты — это история проекта: Убедитесь, что объединение действительно улучшает историю, а не скрывает важные детали изменений.
Дополнительные советы
• Используйте понятные сообщения коммитов: Это облегчит понимание истории даже без объединения.
• Часто обновляйте ветки: Регулярное обновление веток и разрешение конфликтов уменьшает необходимость в крупных изменениях истории.
Заключение
Объединение коммитов — полезная практика для поддержания чистой и понятной истории проекта. Это особенно важно в командной работе, где ясность и упорядоченность облегчают совместную разработку и поддержку кода. Используя git rebase -i и другие инструменты Git, вы можете эффективно управлять историей коммитов и улучшать качество вашего проекта.
Как создать пакет NPM
Создание собственного npm-пакета может показаться сложной задачей, но на деле это увлекательный процесс, который открывает новые возможности для разработки и обмена своими наработками с сообществом. В этой статье мы подробно разберем, как создать свой первый npm-пакет, шаг за шагом пройдем процесс его подготовки, публикации и управления. Независимо от того, хотите ли вы поделиться полезной библиотекой или автоматизировать задачи в вашем проекте, это руководство поможет вам начать путь к созданию собственного инструмента.

Эта статья - перевод и адаптация статьи How To Create An NPM Package от Matt Pocock
В этой статье будут использованы следующие технологии:
1) Git для контроля версий
2) TypeScript для написания кода и обеспечения его типобезопасности.
3) Prettier для форматирования кода
4) @arethetypeswrong/cli для проверки нашего экспорта
5) tsup для компиляции нашего кода TypeScript в CJS и ESM
6) Vitest для проведения наших тестов
7) GitHub Actions для запуска CI
8) Changesets для управления версиями и публикации нашего пакета
Если вы хотите увидеть готовый результат - посмотрите этот репозиторий.
1. Git
В этом разделе мы создадим новый репозиторий git, настроим .gitignore, создадим первоначальный коммит, создадим новый репозиторий на GitHub и отправим наш код на GitHub.
1.1: Инициализация репозитория
Выполните следующую команду, чтобы инициализировать новый репозиторий git:
1git init1.2: Настройка .gitignore
Создайте файл .gitignore в корне вашего проекта и добавьте следующее:
1node_modules1.3: Создание первоначального коммита
Выполните следующую команду, чтобы создать первоначальный коммит:
1git add .
2git commit -m "Initial commit"1.4: Создание нового репозитория на GitHub.
У github есть замечательная консольная утилита gh для работы с github из консоли. Если до этого вы не пользовались cli утилитой - перейдите на сайт https://cli.github.com и установите утилиту по инструкции.
Пройдите аутентификацию вызвав команду:
1gh auth loginВыполните следующую команду, чтобы создать новый репозиторий. Для этого примера я выбрал имя tt-package-demo:
1gh repo create tt-package-demo --source=. --publicКоманда gh repo create tt-package-demo --source=. --public выполнит следующие действия:
1. Создаст новый удалённый репозиторий с именем tt-package-demo на GitHub.
2. Укажет исходную директорию (в данном случае текущую директорию, обозначенную как .) для этого репозитория.
3. Сделает репозиторий публичным (благодаря флагу --public).
4. Привяжет удалённый репозиторий к вашему локальному репозиторию, добавив GitHub-репозиторий в качестве удалённого (origin).
Таким образом, после выполнения этой команды ваш локальный репозиторий будет связан с новым удалённым репозиторием на GitHub, и вы сможете отправлять коммиты с помощью команды git push origin main или аналогичных команд для других веток.
1.5: Push в GitHub
Выполните следующую команду, чтобы отправить свой код на GitHub:
1git push --set-upstream origin main
22: package.json
В этом разделе мы создадим файл package.json, добавим поле license, создадим файл LICENSE и добавим файл README.md.
2.1. Создание файла package.json
Создайте файл package.json со следующим содержимым:
1{
2 "name": "tt-package-demo",
3 "version": "1.0.0",
4 "description": "A demo package for Total TypeScript",
5 "keywords": ["demo", "typescript"],
6 "homepage": "https://github.com/mattpocock/tt-package-demo",
7 "bugs": {
8 "url": "https://github.com/mattpocock/tt-package-demo/issues"
9 },
10 "author": "Matt Pocock <team@totaltypescript.com> (https://totaltypescript.com)",
11 "repository": {
12 "type": "git",
13 "url": "git+https://github.com/mattpocock/tt-package-demo.git"
14 },
15 "files": ["dist"],
16 "type": "module"
17}name - это имя, под которым пользователи будут устанавливать ваш пакет. Оно должно быть уникальным в npm. Для имени пакета можете создать так называемые organization scopes (например, имя пакета @total-typescript/demo где @total-typescript - пространство организации), это поможет сделать ваш продукт уникальным.
version - это версия вашего пакета. Он должен соответствовать семантическому версионированию (semantic versioning): формат 0.0.1. Каждый раз, когда вы публикуете новую версию, вы должны увеличивать это число.
description и keywords - это краткое описание вашего пакета. Они указаны в поиске в реестре npm.
homepage - это URL-адрес домашней страницы вашего пакета. По умолчанию можно использовать репозиторий на GitHub или сайт с документами, если он у вас есть.
bugs - это URL-адрес, по которому пользователи могут сообщать о проблемах с вашим пакетом.
author - это вы! Вы можете добавить свой адрес электронной почты и веб-сайт. Если у вас несколько разработчиков, вы можете указать их как массив участников с одинаковым форматированием.
repository - это URL-адрес хранилища вашего пакета. При этом в реестре npm создается ссылка на ваш репозиторий на GitHub.
files - это массив файлов, которые должны быть включены при установке вашего пакета. В данном случае мы включаем папку dist. Файлы README.md, package.json и LICENSE включены по умолчанию.
Значение type равно module, чтобы указать, что ваш пакет использует систему модулей ECMAScript, а не модули CommonJS.
2.2: Добавление поле лицензии.
1{
2 "license": "MIT"
3}2.3: Добавление файла ЛИЦЕНЗИИ
Создайте файл с именем LICENSE (без расширения), содержащий текст вашей лицензии. Для MIT это:
1MIT License
2
3Copyright (c) [year] [fullname]
4
5Permission is hereby granted, free of charge, to any person obtaining a copy
6of this software and associated documentation files (the "Software"), to deal
7in the Software without restriction, including without limitation the rights
8to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9copies of the Software, and to permit persons to whom the Software is
10furnished to do so, subject to the following conditions:
11
12The above copyright notice and this permission notice shall be included in all
13copies or substantial portions of the Software.
14
15THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21SOFTWARE.Измените заполнители [год] и [полное имя] на текущий год и свое имя.
2.4: Добавление README.md
Создайте файл README.md с описанием вашего пакета. Вот пример:
1**tt-package-demo**
2
3A demo package for Total TypeScript.Это будет показано в реестре npm, когда люди будут просматривать ваш пакет.
3: TypeScript
В этом разделе мы установим TypeScript, настроим tsconfig.json, создадим исходный файл, создадим index файл, настроим сценарий сборки (build), запустим нашу сборку, добавим dist в .gitignore, настроим сценарий ci и настроим наш tsconfig.json для DOM.
3.1: Установка TypeScript
Запустите следующую команду, чтобы установить TypeScript:
1npm install --save-dev typescriptМы добавляем к команде флаг --save-dev для установки TypeScript в качестве зависимости разработки. Это означает, что он не будет включен при установке вашего пакета у пользователя.
3.2. Настройка tsconfig.json.
Создайте файл tsconfig.json со следующим содержимым:
1{
2 "compilerOptions": {
3 /* Base Options: */
4 "esModuleInterop": true,
5 "skipLibCheck": true,
6 "target": "es2022",
7 "allowJs": true,
8 "resolveJsonModule": true,
9 "moduleDetection": "force",
10 "isolatedModules": true,
11 "verbatimModuleSyntax": true,
12
13 /* Strictness */
14 "strict": true,
15 "noUncheckedIndexedAccess": true,
16 "noImplicitOverride": true,
17
18 /* If transpiling with TypeScript: */
19 "module": "NodeNext",
20 "outDir": "dist",
21 "rootDir": "src",
22 "sourceMap": true,
23
24 /* AND if you're building for a library: */
25 "declaration": true,
26
27 /* AND if you're building for a library in a monorepo: */
28 "declarationMap": true
29 }
30}Эти параметры подробно описаны в шпаргалке по TSConfig.
3.3. Настройка tsconfig.json для DOM
Если ваш код выполняется в DOM (т. е. требует доступа к document, window, localStorage и т. д.), пропустите этот шаг.
Если вашему коду не требуется доступ к DOM API, добавьте в tsconfig.json следующее:
1{
2 "compilerOptions": {
3 // ...other options
4 "lib": ["es2022"]
5 }
6}Опция `"lib": ["es2022"]` в настройках TypeScript указывает, какие встроенные библиотеки JavaScript должны быть доступны во время компиляции. В данном случае, указывая `["es2022"]`, вы говорите компилятору, что хотите использовать возможности и объекты, доступные в спецификации ECMAScript 2022.
Это позволяет вам использовать такие возможности, как методы и API, которые появились в ES2022, например, `Array.prototype.at`, улучшенные функции для работы с `WeakRefs` и другие.
Если ваш код должен поддерживать более старые версии JavaScript, можно выбрать соответствующие библиотеки, например, `"es5"` или `"es6"`.
При использовании настройки "lib": ["es2022"] поддержка типов для DOM (например, таких объектов, как document, window, HTMLElement и т. д.) не будет включена автоматически, потому что в данном случае подключается только стандартная библиотека ECMAScript 2022.
Чтобы добавить поддержку типов для DOM, нужно явно указать библиотеку DOM, добавив её в список `"lib": ["es2022", "dom"]`
Это обеспечит поддержку типов для работы с веб-API и объектами браузера, такими как элементы страницы и события.
Но в нашем случае это не требуется.
3.4: Создание исходный файл (Source File)
Создайте файл src/utils.ts со следующим содержимым:
1export const add = (a: number, b: number) => a + b;3.5: Создание индексного файла (Index File)
Создайте файл src/index.ts со следующим содержимым:
1export { add } from "./utils.js";Понимаю, расширение .js выглядит странно. Эта статья объясняет больше.
Если совсем кратко, то в статье объясняется, что при использовании настроек moduleResolution: node16 или nodenext в TypeScript требуется явное указание расширений файлов при импорте (например, ./module.js). Это сделано для соответствия спецификации Node.js, что упрощает процесс разрешения модулей. Если добавить расширение .ts, возникает ошибка, так как эта опция работает только при включенной настройке allowImportingTsExtensions. Чтобы избежать этого, рекомендуется использовать .js в импортах или изменить модульную конфигурацию.
3.6: Настройка сценария сборки
Добавьте секцию scripts в ваш package.json со следующим содержимым:
1{
2 "scripts": {
3 "build": "tsc"
4 }
5}Этот скрипт скомпилирует ваш код TypeScript в JavaScript.
3.7: Запуск сборки
Запустите следующую команду, чтобы скомпилировать код TypeScript:
1npm run buildПосле выполнения команды будет создана директория dist с вашим скомпилированным кодом JavaScript.
3.8: Добавьте dist в .gitignore
Добавьте папку dist в ваш файл .gitignore файл:
1distЭто предотвратит включение скомпилированного кода в ваш репозиторий git.
3.9: Настройка ci-скрипта
Добавьте в package.json скрипт ci со следующим содержимым:
1{
2 "scripts": {
3 "ci": "npm run build"
4 }
5}Это даст нам быстрый доступ для выполнения всех необходимых операций в CI.
4: Prettier
В этом разделе мы установим Prettier, настроим .prettierrc, настроим скрипт форматирования (format), запустим скрипт форматирования (format), настроим скрипт проверки формата (check-format), добавим скрипт проверки формата (check-format) в наш скрипт CI и запустим CI сценарий.
4.1: Установка Prettier
Запустите следующую команду, чтобы установить Prettier:
1npm install --save-dev prettier4.2: Настройка .prettierrc
Создайте файл .prettierrc со следующим содержимым:
1{
2 "semi": true,
3 "singleQuote": true,
4 "trailingComma": "all",
5 "printWidth": 80,
6 "tabWidth": 2
7}Вы можете добавить в этот файл дополнительные параметры, чтобы настроить поведение Prettier. Полный список опций вы можете найти здесь.
4.3: Настройка сценария форматирования (format script)
Добавьте в package.json скрипт format со следующим содержимым:
1{
2 "scripts": {
3 "format": "prettier --write ."
4 }
5}Это приведет к форматированию всех файлов вашего проекта с помощью Prettier.
4.4: Запуск сценарий форматирования
Запустите следующую команду, чтобы отформатировать все файлы вашего проекта:
1npm run formatВы можете заметить, что некоторые файлы изменились. Зафиксируйте изменения с помощью команд:
1git add .
2git commit -m "Format code with Prettier"4.5: Настройка сценария проверки формата (check-format)
Добавьте в package.json скрипт check-format со следующим содержимым:
1{
2 "scripts": {
3 "check-format": "prettier --check ."
4 }
5}Этот скрипт проверит, правильно ли отформатированы все файлы в вашем проекте.
4.6: Добавление CI-скрипта
Добавьте скрипт check-format в скрипт ci в package.json:
1{
2 "scripts": {
3 "ci": "npm run build && npm run check-format"
4 }
5}Это запустит скрипт проверки формата как часть вашего процесса CI.
5: exports, main и @arethetypeswrong/cli
В этом разделе мы установим @arethetypeswrong/cli, настроим скрипт check-exports, запустим скрипт check-exports, настроим main поле, снова запустим скрипт check-exports, настроим и запустим скрипт ci.
@arethetypeswrong/cli — это инструмент, который проверяет правильность экспорта вашего пакета. Это важно, поскольку в них легко ошибиться, и это может вызвать проблемы у людей, использующих ваш пакет.
5.1: Установка @arethetypeswrong/cli
Запустите следующую команду, чтобы установить @arethetypeswrong/cli:
1npm install --save-dev @arethetypeswrong/cli5.2: Настройка скрипта проверки экспорта
Добавьте в package.json скрипт check-exports со следующим содержимым:
1{
2 "scripts": {
3 "check-exports": "attw --pack ."
4 }
5}Это проверит, все ли экспорты из вашего пакета верны.
5.3: Запуск скрипта check-exports
Запустите следующую команду, чтобы проверить правильность всех экспортов из вашего пакета:
1npm run check-exportsВы должны заметить различные ошибки:
1┌───────────────────┬──────────────────────┐
2│ │ "tt-package-demo" │
3├───────────────────┼──────────────────────┤
4│ node10 │ 💀 Resolution failed │
5├───────────────────┼──────────────────────┤
6│ node16 (from CJS) │ 💀 Resolution failed │
7├───────────────────┼──────────────────────┤
8│ node16 (from ESM) │ 💀 Resolution failed │
9├───────────────────┼──────────────────────┤
10│ bundler │ 💀 Resolution failed │
11└───────────────────┴──────────────────────┘Это означает, что ни одна версия Node или какой-либо сборщик не может использовать наш пакет.
Давайте это исправим
5.4: Установка main
Добавьте поле main в package.json со следующим содержимым:
1{
2 "main": "dist/index.js"
3}Это строчка подсказывает Node, где найти точку входа вашего пакета.
5.5: Пробуем еще раз проверить экспорт
Запустите следующую команду, чтобы проверить правильность всех экспортов из вашего пакета:
1npm run check-exportsТеперь, вы должны заметить только одно предупреждение:
1┌───────────────────┬──────────────────────────────┐
2│ │ "tt-package-demo" │
3├───────────────────┼──────────────────────────────┤
4│ node10 │ 🟢 │
5├───────────────────┼──────────────────────────────┤
6│ node16 (from CJS) │ ⚠️ ESM (dynamic import only) │
7├───────────────────┼──────────────────────────────┤
8│ node16 (from ESM) │ 🟢 (ESM) │
9├───────────────────┼──────────────────────────────┤
10│ bundler │ 🟢 │
11└───────────────────┴──────────────────────────────┘Это говорит нам о том, что наш пакет совместим с системами, на которых работает ESM. Людям, использующим CJS (часто в устаревших системах), потребуется импортировать его с помощью динамического импорта.
5.6 Исправление предупреждения CJS
Если вы не хотите поддерживать CJS модули (что я рекомендую), измените сценарий check-exports на:
1{
2 "scripts": {
3 "check-exports": "attw --pack . --ignore-rules=cjs-resolves-to-esm"
4 }
5}Теперь при запуске check-export все будет отображаться зеленым цветом:
1┌───────────────────┬───────────────────┐
2│ │ "tt-package-demo" │
3├───────────────────┼───────────────────┤
4│ node10 │ 🟢 │
5├───────────────────┼───────────────────┤
6│ node16 (from CJS) │ 🟢 (ESM) │
7├───────────────────┼───────────────────┤
8│ node16 (from ESM) │ 🟢 (ESM) │
9├───────────────────┼───────────────────┤
10│ bundler │ 🟢 │
11└───────────────────┴───────────────────┘Если вы предпочитаете двойную публикацию CJS и ESM, пропустите этот шаг.
5.7: Добавление в наш CI-скрипт
Добавьте скрипт check-exports в сценарий ci в package.json:
1{
2 "scripts": {
3 "ci": "npm run build && npm run check-format && npm run check-exports"
4 }
5}6. Использование tsup для двойной публикации
Если вы хотите опубликовать код CJS и ESM модулей, вы можете использовать tsup. Это инструмент, созданный на основе esbuild, который компилирует ваш код TypeScript в оба формата.
Моя личная рекомендация — пропустить этот шаг и отправлять только ES-модули. Это значительно упрощает настройку и позволяет избежать многих ошибок двойной публикации, таких как Dual Package Hazard.
6.1: Установите tsup
Запустите следующую команду, чтобы установить tsup:
1npm install --save-dev tsup6.2. Создайте файл tsup.config.ts
Создайте файл tsup.config.ts со следующим содержимым:
1import { defineConfig } from "tsup";
2
3export default defineConfig({
4 entryPoints: ["src/index.ts"],
5 format: ["cjs", "esm"],
6 dts: true,
7 outDir: "dist",
8 clean: true,
9});entryPoints - это массив точек входа для вашего пакета. В данном случае мы используем src/index.ts.
format - это массив форматов для вывода. Мы используем js (CommonJS) и esm (модули ECMAScript).
dts - параметр, которое указывает tsup генерировать файлы объявлений.
outDir - это выходной каталог для скомпилированного кода.
clean указывает tsup очистить выходной каталог перед сборкой.
6.3: Изменение сценария сборки
1{
2 "scripts": {
3 "build": "tsup"
4 }
5}Теперь мы будем запускать tsup для компиляции нашего кода вместо tsc.
6.4: Добавьте поле exports
Добавьте поле exports экспорта в package.json со следующим содержимым:
1{
2 "exports": {
3 "./package.json": "./package.json",
4 ".": {
5 "import": "./dist/index.js",
6 "default": "./dist/index.cjs"
7 }
8 }
9}Поле exports сообщает программам, использующим ваш пакет, как найти версии вашего пакета CJS и ESM. В этом случае мы указываем пользователям, использующим импорт, на dist/index.js, а пользователям, использующим require, — на dist/index.cjs.
Также рекомендуется добавить ./package.json в поле экспорта. Это связано с тем, что некоторым инструментам необходим легкий доступ к вашему файлу package.json.
6.5: Пробуем еще раз проверить экспорт
Запустите следующую команду, чтобы проверить правильность всех экспортов из вашего пакета:
1npm run check-exportsТеперь все зеленое:
1┌───────────────────┬───────────────────┐
2│ │ "tt-package-demo" │
3├───────────────────┼───────────────────┤
4│ node10 │ 🟢 │
5├───────────────────┼───────────────────┤
6│ node16 (from CJS) │ 🟢 (CJS) │
7├───────────────────┼───────────────────┤
8│ node16 (from ESM) │ 🟢 (ESM) │
9├───────────────────┼───────────────────┤
10│ bundler │ 🟢 │
11└───────────────────┴───────────────────┘6.6: Превращаем TypeScript в линтер
Мы больше не используем tsc для компиляции нашего кода. Но tsup на самом деле не проверяет наш код на наличие ошибок — он просто превращает его в JavaScript.
Это означает, что наш сценарий ci не выдаст ошибку, если в нашем коде есть ошибки TypeScript.
Давайте это исправим.
6.6.1: Добавляем noEmit в tsconfig.json.
1{
2 "compilerOptions": {
3 // ...other options
4 "noEmit": true
5 }
6}6.6.2. Удаляем неиспользуемые поля из tsconfig.json.
Удалите следующие поля из вашего tsconfig.json:
outDir
rootDir
sourceMap
declaration
declarationMap
Они больше не нужны в нашей новой настройке «линтинга».
6.6.3: Изменение module на «Preserve»
При желании теперь вы можете изменить module на Preserve в вашем tsconfig.json:
1{
2 "compilerOptions": {
3 // ...other options
4 "module": "Preserve"
5 }
6}Это означает, что вам больше не нужно будет импортировать файлы с расширениями .js. Это означает, что index.ts может выглядеть следующим образом:
1export * from "./utils";6.6.4: Добавление lint скрипта
Добавьте скрипт lint в свой package.json со следующим содержимым:
1{
2 "scripts": {
3 "lint": "tsc"
4 }
5}Это запустит TypeScript в качестве линтера.
6.6.5: Добавьте lint в ваш ci-скрипт
Добавьте сценарий lint в сценарий ci в package.json:
1{
2 "scripts": {
3 "ci": "npm run build && npm run check-format && npm run check-exports && npm run lint"
4 }
5}Теперь мы будем получать ошибки TypeScript как часть нашего процесса CI.
7. Тестирование с помощью Vitest
В этом разделе мы установим vitest, создадим тест, настроим скрипт test, запустим его, настроим скрипт dev и добавим test скрипт в наш CI-скрипт.
vitest — это современный инструмент для запуска тестов для ESM и TypeScript. Это как Jest, но лучше.
7.1: Установка vitest
Запустите следующую команду для установки vitest:
1npm install --save-dev vitest7.2: Создаем тест
Создайте файл src/utils.test.ts со следующим содержимым:
1import { add } from "./utils.js";
2import { test, expect } from "vitest";
3
4test("add", () => {
5 expect(add(1, 2)).toBe(3);
6});Это простой тест, который проверяет, возвращает ли функция hello правильное значение.
7.3: Настройка скрипта test
Добавьте скрипт test в package.json со следующим содержимым:
1{
2 "scripts": {
3 "test": "vitest run"
4 }
5}vitest run запускает все тесты в вашем проекте один раз, без просмотра.
7.4: Запускаем test скрипт
Выполните следующую команду, чтобы запустить тесты:
1npm run testВы должны увидеть следующий вывод:
1 ✓ src/utils.test.ts (1)
2 ✓ hello
3
4 Test Files 1 passed (1)
5 Tests 1 passed (1)Это означает, что ваш тест пройден успешно.
7.5: Установка скрипта dev
Обычный рабочий процесс — запуск тестов в режиме просмотра во время разработки. Добавьте в package.json скрипт dev со следующим содержимым:
1{
2 "scripts": {
3 "dev": "vitest"
4 }
5}Это запустит ваши тесты в режиме наблюдения.
7.6: Добавление в наш CI-скрипт
Добавьте test скрипт в свой ci-скрипт в package.json:
1{
2 "scripts": {
3 "ci": "npm run build && npm run check-format && npm run check-exports && npm run lint && npm run test"
4 }
5}8. Настройка CI с помощью GitHub Actions.
В этом разделе мы создадим рабочий процесс GitHub Actions, который запускает наш процесс CI при каждом запросе фиксации и извлечения.
Это решающий шаг в обеспечении того, чтобы наш пакет всегда находился в рабочем состоянии.
8.1: Создание workflow
Создайте файл .github/workflows/ci.yml со следующим содержимым:
1name: CI
2
3on:
4 pull_request:
5 push:
6 branches:
7 - main
8
9concurrency:
10 group: ${{ github.workflow }}-${{ github.ref }}
11 cancel-in-progress: true
12
13jobs:
14 ci:
15 runs-on: ubuntu-latest
16
17 steps:
18 - uses: actions/checkout@v4
19
20 - name: Use Node.js
21 uses: actions/setup-node@v4
22 with:
23 node-version: "20"
24
25 - name: Install dependencies
26 run: npm install
27
28 - name: Run CI
29 run: npm run ciЭтот файл GitHub использует в качестве инструкций для запуска вашего процесса CI.
name - это название рабочего процесса.
on указывает, когда должен выполняться рабочий процесс. В этом случае он выполняется по запросам на загрузку и передается в главную ветвь.
concurrency предотвращает одновременный запуск нескольких экземпляров рабочего процесса, используя cancel-in-progress для отмены любых существующих запусков.
jobs - это набор заданий для запуска. В данном случае у нас есть одно задание под названием ci.
actions/checkout@v4 извлекает код из хранилища.
actions/setup-node@v4 устанавливает Node.js и npm.
npm install устанавливает зависимости проекта.
npm run ci запускает сценарий CI проекта.
Если какая-либо часть нашего процесса CI завершится сбоем, рабочий процесс завершится неудачно, и GitHub сообщит нам об этом, показав красный крестик рядом с нашим коммитом.
8.2: Тестирование нашего workflow
Запуште изменения на GitHub и проверьте вкладку «Actions» в своем репозитории. Вы должны увидеть, как работает ваш workflow.
Это даст нам предупреждение о каждом сделанном коммите и каждом запросе на добавление в репозиторий.
9. Публикация с Changesets
В этом разделе мы установим @changesets/cli, инициализируем наборы изменений, опубликуем выпуски набора изменений, установим для параметра commit значение true, настроим скрипт локального выпуска, добавим набор изменений, зафиксируем изменения, запустим сценарий локального выпуска и наконец-то увидите свой пакет на npm.
9.1: Установка @changesets/cli
Запустите следующую команду для инициализации Changesets:
1npm install --save-dev @changesets/cli9.2: Инициализация Changesets
Запустите следующую команду для инициализации наборов изменений:
1npx changeset initВ вашем проекте будет создана папка .changeset, содержащая файл config.json. Здесь также будут храниться ваши Changesets.
9.3: Публикуем Changesets
В .changeset/config.json измените поле access на общедоступное:
1// .changeset/config.json
2{
3 "access": "public"
4}Без изменения этого поля Changesets не опубликуют ваш пакет в npm.
9.4: Установка commit в true
В .changeset/config.json измените поле commit на true:
1// .changeset/config.json
2{
3 "commit": true
4}Это зафиксирует Changesets в вашем репозитории после создания версий.
9.5: Настройка скрипта local-release
Добавьте в package.json скрипт local-release со следующим содержимым:
1{
2 "scripts": {
3 "local-release": "changeset version && changeset publish"
4 }
5}Этот скрипт запустит ваш процесс CI, а затем опубликует ваш пакет в npm. Это будет команда, которую вы запустите, когда захотите выпустить новую версию вашего пакета с вашего локального компьютера.
9.6 Запуск CI только в prepublishOnly
Добавьте в package.json скрипт prepublishOnly со следующим содержимым:
1{
2 "scripts": {
3 "prepublishOnly": "npm run ci"
4 }
5}Это автоматически запустит процесс CI перед публикацией пакета в npm.
Это полезно для отделения от скрипта local-release на случай, если пользователь случайно запустит npm publish без запуска локальной версии.
9.7: Добавление Changesets
Запустите следующую команду, чтобы добавить changeset:
1npx changesetОткроется интерактивное приглашение, в котором вы сможете добавить changeset. Changeset — это способ сгруппировать изменения и присвоить им номер версии.
Отметьте этот выпуск как выпуск patch и дайте ему описание, например «Initial release».
Это создаст новый файл в папке .changeset с набором изменений.
9.8: Фиксируем изменения
Зафиксируйте изменения в своем репозитории:
1git add .
2git commit -m "Prepare for initial release"9.9: Запустите скрипт local-release
Выполните следующую команду, чтобы зарелизить пакет:
1npm run local-releaseЭто запустит ваш процесс CI, версионирует ваш пакет и опубликует его в npm.
В вашем репозитории будет создан файл CHANGELOG.md с подробным описанием изменений в этом выпуске. Оно будет обновляться каждый раз при выпуске.
9.10: Смотрим свой пакет на npm
Перейдите к:
1http://npmjs.com/package/<your package name>Вы должны увидеть там свою посылку! Вы сделали это! Вы опубликовали в npm!
Выводы
Теперь у вас есть полностью настроенный пакет. Вы настроили:
- Проект TypeScript с новейшими настройками.
- Prettier, который одновременно форматирует ваш код и проверяет его правильность.
- @arethetypeswrong/cli, который проверяет правильность экспорта вашего пакета.
- tsup, который компилирует ваш код TypeScript в JavaScript.
- vitest, который запускает ваши тесты
- GitHub Actions, который запускает ваш процесс CI
- Changesets: описания изменений в пакете
Для дальнейшего чтения я бы рекомендовал настроить действие GitHub Changesets и PR-бота, чтобы автоматически рекомендовать участникам добавлять changesets в свои PR.
А если у вас возникнут еще вопросы, дайте мне знать!
Создание простой игры на Python при помощи библиотеки Pygame
В данной статье я опишу сценарий создания простой игры на Python. Поможет нам в этом библиотека Pygame. Данная статья не тянет на большой обзор, скорее короткое руководство к действию, чтобы быстро опробовать инструмент.
Справедливости ради, на Python нет больших игр, язык создан для других целей. Но создать простенькую, кроссплатформенную инди-игру - труда не составит.

Pygame - это библиотека для разработки игр и мультимедийных приложений на языке Python. Она была создана в 2000 году программистом из Ирландии, Питером Линдером, как ответ на отсутствие подобных инструментов для Python на тот момент.
Первоначально Pygame была создана для работы с графикой и звуком, но со временем она стала поддерживать все больше функций, таких как работа с мышью, клавиатурой, сетью и т.д.
За годы своего существования Pygame стала популярной среди разработчиков игр и мультимедийных приложений, благодаря своей простоте и удобству использования. Сегодня Pygame является одной из самых популярных библиотек для разработки игр на Python.
Цель
Мы будем создавать простенькую аркадную по типу Space Invaders для двух игроков. Игроки управляют космическим кораблем и выпускают друг по другу снаряды. У каждого игрока есть некоторое количество жизней. Первый игрок потративший все жизни считается проигравшим.

Ссылка на репозиторий с готовой игрой, если вам вздумается сразу скачать готовый код и посмотреть результат.
Настройка окружения
Итак, приступим.
Создадим новый проект и файл main.py
Теперь нам необходимо установить библиотеку pygame в наш проект. Воспользуемся пакетным менеджером pip (он устанавливается вместе с Python)
Откройте терминал для ввода команды установки. Если вы используете VS Code вы можете открыть терминал в текущей папке при помощи кнопок на панели инструментов.

Вводим команду: pip install pygame

Отлично. Можем начинать создание игры.
Создания окна игры
Перепишите следующий код в файл main.py
Я буду помечать код комментариями, чтобы вам было понятно что происходит на каждой строчке.
1# Подключаем игровой движок Pygame
2import pygame
3
4# Подготавливаем необходимые модули Pygame
5pygame.init()
6
7### Константы ###
8# Константы размера окна
9WIDTH = 600
10HEIGHT = 300
11
12# Задаем размеры игрового окна
13screen = pygame.display.set_mode((WIDTH, HEIGHT))
14
15# Запускаем бесконечный цикл программы
16# Это делается чтобы программа не завершалась и постоянно рисовала новые кадры игры
17while True:
18 pygame.display.update()Запустите программу. Вы должны увидеть окно черного цвета с разрешением 600 на 300 пикселей.
Обратите внимание, что кнопки свернуть, и закрыть программу неактивны.

Давайте добавим возможность свернуть и закрыть игру при помощи стандартных кнопок.
Для этого в бесконечный цикл добавьте следующий код:
1# Запускаем бесконечный цикл программы
2# Это делается чтобы программа не завершалась и постоянно рисовала новые кадры игры
3while True:
4 # Постоянно проверяем события игры и если присутствует событие Выход - останавливаем игру.
5 for event in pygame.event.get():
6 if event.type == pygame.QUIT:
7 pygame.quit()
8
9 # Обновляем кадры игры
10 pygame.display.update()В бесконечном цикле мы проверяем, не случилось ли события QUIT (выход), в процессе работы программы и если пользователь нажал на выход, значит мы зарегистрировали событие QUIT - закрываем игру при помощи команды pygame.quit()
Рисуем задний фон
Теперь давайте нарисуем задник нашей игры. Сохраните картинку и положите ее в директорию assets (предварительно создав ее) в корне директории вашей игры.

Так же нам понадобится модуль os. Модуль os позволяет работать с файловой системой компьютера, а именно, поможет нам загрузить картинку.
Загрузим картинку в память при помощи следующего кода:
1# Подключаем модуль для работы с файловой системой
2import os
3
4# Загружаем изображение в память
5SPACE_IMAGE = pygame.image.load(os.path.join('./assets', 'space.jpg'))
6
7# Создаем объект фона с разрешением окна
8SPACE_BG = pygame.transform.scale(SPACE_IMAGE, (WIDTH, HEIGHT))И теперь достаточно поместить вызов screen.blit(SPACE, (0, 0)) внутрь нашего бесконечного цикла рисующего карды и фон будет виден игроку. Метод blit позволяет наложить одно изображение на другое. В нашем случае нам нужно наложит изображение поверх окна screen.
1# Запускаем бесконечный цикл программы
2# Это делается чтобы программа не завершалась и постоянно рисовала новые кадры игры
3while True:
4 # Рисуем изображение на заднем фоне
5 screen.blit(SPACE_BG, (0, 0))Промежуточный результат #1
Работает:
- Кнопка закрыть/свернуть
- Отображается задний фон
1# Подключаем игровой движок Pygame
2import pygame
3# Подключаем модуль для работы с файловой системой
4import os
5
6# Подготавливаем необходимые модули Pygame
7pygame.init()
8
9### Константы ###
10# Константы размера окна
11WIDTH = 600
12HEIGHT = 300
13
14# Задаем размеры игрового окна
15screen = pygame.display.set_mode((WIDTH, HEIGHT))
16
17# Загружаем изображение в память
18SPACE_IMAGE = pygame.image.load(os.path.join('./assets', 'space.jpg'))
19
20# Создаем объект фона с разрешением окна
21SPACE_BG = pygame.transform.scale(SPACE_IMAGE, (WIDTH, HEIGHT))
22
23# Запускаем бесконечный цикл программы
24# Это делается чтобы программа не завершалась и постоянно рисовала новые кадры игры
25while True:
26 # Рисуем изображение на заднем фоне
27 screen.blit(SPACE_BG, (0, 0))
28
29 # Постоянно проверяем события игры и если присутствует событие Выход - останавливаем игру.
30 for event in pygame.event.get():
31 if event.type == pygame.QUIT:
32 pygame.quit()
33
34 # Обновляем кадры игры
35 pygame.display.update()Разделитель игрового экрана
Добавим на экран визуальный разделитель экрана - границу которую игроки не могут пересечь, оставаясь на своей стороне поля.
Создадим объект прямоугольник.
1# Формируем объект границы
2BORDER = pygame.Rect(WIDTH//2 - 5, 0, 10, HEIGHT)
3Обратите внимание, первые два аргумента функции это x и y расположения прямоугольника, а третий и четвертый аргументы это ширина и высота прямоугольника. Ширина прямоугольника 10, а высота такая же как высота экрана игры. По y прямоугольник начинается от верхнего края экрана, а вот по x мы берем ширину экрана, делим ее на 2 и отнимаем 5 (половину ширины прямоугольника). Благодаря этому прямоугольник располагается прямо посередине экрана игры. Осталось только отрисовать этот объект. Добавим отрисовку в бесконечный цикл, рядом с отрисовкой фона.
1# Рисуем прямоугольник
2pygame.draw.rect(screen, "white", BORDER)Метод rect объекта draw позволяет отрисовать прямоугольник. Первый аргумент screeen указывает где нужно отрисовать, второй аргумент задает цвет, третий аргумент задает сам объект рисования, наш BORDER.
Должно получиться вот так:

Промежуточный результат #2
Работает:
- Кнопка закрыть/свернуть
- Отображается задний фон
- Разделитель экрана
1# Подключаем игровой движок Pygame
2import pygame
3# Подключаем модуль для работы с файловой системой
4import os
5
6# Подготавливаем необходимые модули Pygame
7pygame.init()
8
9### Константы ###
10# Константы размера окна
11WIDTH = 600
12HEIGHT = 300
13
14# Задаем размеры игрового окна
15screen = pygame.display.set_mode((WIDTH, HEIGHT))
16
17# Загружаем изображение в память
18SPACE_IMAGE = pygame.image.load(os.path.join('./assets', 'space.jpg'))
19
20# Создаем объект фона с разрешением окна
21SPACE_BG = pygame.transform.scale(SPACE_IMAGE, (WIDTH, HEIGHT))
22
23# Формируем объект границы
24BORDER = pygame.Rect(WIDTH//2 - 2, 0, 4, HEIGHT)
25
26# Запускаем бесконечный цикл программы
27# Это делается чтобы программа не завершалась и постоянно рисовала новые кадры игры
28while True:
29 # Рисуем изображение на заднем фоне
30 screen.blit(SPACE_BG, (0, 0))
31
32 # Рисуем прямоугольник
33 pygame.draw.rect(screen, "white", BORDER)
34
35 # Постоянно проверяем события игры и если присутствует событие Выход - останавливаем игру.
36 for event in pygame.event.get():
37 if event.type == pygame.QUIT:
38 pygame.quit()
39
40 # Обновляем кадры игры
41 pygame.display.update()Создаем игрока
Давайте нарисуем игроков и зададим им движение.
Ниже представлены две картинки: Красный космический корабль и Желтый космический корабль.
Скопируйте эти изображения в директорию assets вашего проекта под именами: spaceship_red.png и spaceship_yellow.png


Создадим две переменных, ширину и высоту кораблей. Добавьте их к блоку константы.
1# Размеры корабля
2SPACESHIP_WIDTH = 55
3SPACESHIP_HEIGHT = 40В следующем участке кода, мы загружаем изображения красного и желтого кораблей и при помощи rotate разворачиваем изображения в нужную сторону.
1# Загружаем изображение красного корабля
2RED_SPACESHIP_IMAGE = pygame.image.load(
3 os.path.join('./assets', 'spaceship_red.png'))
4# Разворачиваем изображение в нужном направлении
5RED_SPACESHIP = pygame.transform.rotate(pygame.transform.scale(
6 RED_SPACESHIP_IMAGE, (SPACESHIP_WIDTH, SPACESHIP_HEIGHT)), 90)
7
8# Загружаем изображение желтого корабля
9YELLOW_SPACESHIP_IMAGE = pygame.image.load(
10 os.path.join('./assets', 'spaceship_yellow.png'))
11# Разворачиваем изображение в нужном направлении
12YELLOW_SPACESHIP = pygame.transform.rotate(pygame.transform.scale(
13 YELLOW_SPACESHIP_IMAGE, (SPACESHIP_WIDTH, SPACESHIP_HEIGHT)), 270)Картинки загрузили, теперь нужно создать два объекта прямоугольника для будущих кораблей. Так как объекты Rect хранят ширину, высоту, и координаты x и y - это идеальные кандидаты для хранения данных кораблей.
1# Создаем два объекта/прямоугольника
2red = pygame.Rect(100, 150, SPACESHIP_WIDTH, SPACESHIP_HEIGHT)
3yellow = pygame.Rect(500, 150, SPACESHIP_WIDTH, SPACESHIP_HEIGHT)Отлично, осталось только отрисовать наши корабли на экране. Добавьте следующий код в бесконечный цикл отрисовки экрана.
1# Рисуем корабли
2screen.blit(YELLOW_SPACESHIP, (yellow.x, yellow.y))
3screen.blit(RED_SPACESHIP, (red.x, red.y))Промежуточный результат #3
Работает:
- Кнопка закрыть/свернуть
- Отображается задний фон
- Разделитель экрана
- Отрисовка игроков
1# Подключаем игровой движок Pygame
2import pygame
3# Подключаем модуль для работы с файловой системой
4import os
5
6# Подготавливаем необходимые модули Pygame
7pygame.init()
8
9### Константы ###
10# Константы размера окна
11WIDTH = 600
12HEIGHT = 300
13# Размеры корабля
14SPACESHIP_WIDTH = 55
15SPACESHIP_HEIGHT = 40
16
17# Задаем размеры игрового окна
18screen = pygame.display.set_mode((WIDTH, HEIGHT))
19
20# Загружаем изображение в память
21SPACE_IMAGE = pygame.image.load(os.path.join('./assets', 'space.jpg'))
22
23# Создаем объект фона с разрешением окна
24SPACE_BG = pygame.transform.scale(SPACE_IMAGE, (WIDTH, HEIGHT))
25
26# Формируем объект границы
27BORDER = pygame.Rect(WIDTH//2 - 2, 0, 4, HEIGHT)
28
29# Загружаем изображение красного корабля
30RED_SPACESHIP_IMAGE = pygame.image.load(
31 os.path.join('./assets', 'spaceship_red.png'))
32# Разворачиваем изображение в нужном направлении
33RED_SPACESHIP = pygame.transform.rotate(pygame.transform.scale(
34 RED_SPACESHIP_IMAGE, (SPACESHIP_WIDTH, SPACESHIP_HEIGHT)), 90)
35
36# Загружаем изображение желтого корабля
37YELLOW_SPACESHIP_IMAGE = pygame.image.load(
38 os.path.join('./assets', 'spaceship_yellow.png'))
39# Разворачиваем изображение в нужном направлении
40YELLOW_SPACESHIP = pygame.transform.rotate(pygame.transform.scale(
41 YELLOW_SPACESHIP_IMAGE, (SPACESHIP_WIDTH, SPACESHIP_HEIGHT)), 270)
42
43# Создаем два объекта/прямоугольника
44red = pygame.Rect(100, 150, SPACESHIP_WIDTH, SPACESHIP_HEIGHT)
45yellow = pygame.Rect(500, 150, SPACESHIP_WIDTH, SPACESHIP_HEIGHT)
46
47# Запускаем бесконечный цикл программы
48# Это делается чтобы программа не завершалась и постоянно рисовала новые кадры игры
49while True:
50 # Рисуем изображение на заднем фоне
51 screen.blit(SPACE_BG, (0, 0))
52
53 # Рисуем прямоугольник
54 pygame.draw.rect(screen, "white", BORDER)
55
56 # Рисуем корабли
57 screen.blit(YELLOW_SPACESHIP, (yellow.x, yellow.y))
58 screen.blit(RED_SPACESHIP, (red.x, red.y))
59
60 # Постоянно проверяем события игры и если присутствует событие Выход - останавливаем игру.
61 for event in pygame.event.get():
62 if event.type == pygame.QUIT:
63 pygame.quit()
64
65 # Обновляем кадры игры
66 pygame.display.update()Движение игроков
Теперь оживим наши корабли.
К блоку констант добавьте новую переменную VELOCITY. Данная переменная, как можно предположить из названия, задает скорость кораблей.
1# Скорость корабля
2VELOCITY = 1Теперь напишем функцию движения красного корабля.
1# Функция движения красного корабля
2def red_handle_movement(keys_pressed, red):
3 # Движение ВЛЕВО
4 if keys_pressed[pygame.K_a] and red.x - VELOCITY > 0:
5 red.x -= VELOCITY
6 # Движение ВПРАВО (запрещаем двигаться вправо дальше чем граница игроков)
7 if keys_pressed[pygame.K_d] and red.x + VELOCITY + red.width < BORDER.x:
8 red.x += VELOCITY
9 # Движение ВВЕРХ (запрещаем подниматься выше 0 по координате y)
10 if keys_pressed[pygame.K_w] and red.y - VELOCITY > 0:
11 red.y -= VELOCITY
12 # Движение ВНИЗ (запрещаем опускаться ниже чем высота экрана за вычетом высоты корабля и дополнительных 15 для отступа)
13 if keys_pressed[pygame.K_s] and red.y + VELOCITY + red.height < HEIGHT - 15:
14 red.y += VELOCITYПервым аргументом функция получает специальный объект справочник нажатых клавишей. Вторым аргументом функция получает объект Rect красного корабля.
Теперь добавим функцию для желтого корабля:
1# Функция движения желтого корабля
2def yellow_handle_movement(keys_pressed, yellow):
3 # Движение ВЛЕВО (запрещаем пересекать границу игроков)
4 if keys_pressed[pygame.K_LEFT] and yellow.x - VELOCITY > BORDER.x + BORDER.width:
5 yellow.x -= VELOCITY
6 # Движение ВПРАВО
7 if keys_pressed[pygame.K_RIGHT] and yellow.x + VELOCITY + yellow.width < WIDTH:
8 yellow.x += VELOCITY
9 # Движение ВВЕРХ
10 if keys_pressed[pygame.K_UP] and yellow.y - VELOCITY > 0:
11 yellow.y -= VELOCITY
12 # Движение ВНИЗ
13 if keys_pressed[pygame.K_DOWN] and yellow.y + VELOCITY + yellow.height < HEIGHT - 15:
14 yellow.y += VELOCITYВ данных функциях мы проверяем нажатую клавишу (Для красного игрока мы проверяем английские клавиши WASD, для желтого игрока клавиши стрелки), и в зависимости от нажатой клавиши, изменяем нужную координату объекта на скорость корабля (VELOCITY).
Отлично, осталось вызвать эти функции в цикле. Добавьте в бесконечный цикл отрисовки следующие строчки:
1# Узнаем нажатие клавишей
2 keys_pressed = pygame.key.get_pressed()
3 # Выполняем установку координат кораблей
4 red_handle_movement(keys_pressed, red)
5 yellow_handle_movement(keys_pressed, yellow)В бесконечном цикле, мы получаем специальный список нажатых клавишей и вызываем функции движения для каждого корабля.
Запустите программу, должно получиться вот так:

Промежуточный результат #4
Работает:
- Кнопка закрыть/свернуть
- Отображается задний фон
- Разделитель экрана
- Отрисовка игроков
- Движение игроков
1# Подключаем игровой движок Pygame
2import pygame
3# Подключаем модуль для работы с файловой системой
4import os
5
6# Подготавливаем необходимые модули Pygame
7pygame.init()
8
9### Константы ###
10# Константы размера окна
11WIDTH = 600
12HEIGHT = 300
13# Размеры корабля
14SPACESHIP_WIDTH = 55
15SPACESHIP_HEIGHT = 40
16# Скорость корабля
17VELOCITY = 1
18
19# Задаем размеры игрового окна
20screen = pygame.display.set_mode((WIDTH, HEIGHT))
21
22# Загружаем изображение в память
23SPACE_IMAGE = pygame.image.load(os.path.join('./assets', 'space.jpg'))
24
25# Создаем объект фона с разрешением окна
26SPACE_BG = pygame.transform.scale(SPACE_IMAGE, (WIDTH, HEIGHT))
27
28# Формируем объект границы
29BORDER = pygame.Rect(WIDTH//2 - 2, 0, 4, HEIGHT)
30
31# Загружаем изображение красного корабля
32RED_SPACESHIP_IMAGE = pygame.image.load(
33 os.path.join('./assets', 'spaceship_red.png'))
34# Разворачиваем изображение в нужном направлении
35RED_SPACESHIP = pygame.transform.rotate(pygame.transform.scale(
36 RED_SPACESHIP_IMAGE, (SPACESHIP_WIDTH, SPACESHIP_HEIGHT)), 90)
37
38# Загружаем изображение желтого корабля
39YELLOW_SPACESHIP_IMAGE = pygame.image.load(
40 os.path.join('./assets', 'spaceship_yellow.png'))
41# Разворачиваем изображение в нужном направлении
42YELLOW_SPACESHIP = pygame.transform.rotate(pygame.transform.scale(
43 YELLOW_SPACESHIP_IMAGE, (SPACESHIP_WIDTH, SPACESHIP_HEIGHT)), 270)
44
45# Создаем два объекта/прямоугольника
46red = pygame.Rect(100, 150, SPACESHIP_WIDTH, SPACESHIP_HEIGHT)
47yellow = pygame.Rect(500, 150, SPACESHIP_WIDTH, SPACESHIP_HEIGHT)
48
49# Функция движения красного корабля
50def red_handle_movement(keys_pressed, red):
51 # Движение ВЛЕВО
52 if keys_pressed[pygame.K_a] and red.x - VELOCITY > 0:
53 red.x -= VELOCITY
54 # Движение ВПРАВО (запрещаем пересекать границу игроков)
55 if keys_pressed[pygame.K_d] and red.x + VELOCITY + red.width < BORDER.x:
56 red.x += VELOCITY
57 # Движение ВВЕРХ (запрещаем подниматься выше 0 по координате y)
58 if keys_pressed[pygame.K_w] and red.y - VELOCITY > 0:
59 red.y -= VELOCITY
60 # Движение ВНИЗ (запрещаем опускаться ниже чем высота экрана за вычетом высоты корабля и дополнительных 15 для отступа)
61 if keys_pressed[pygame.K_s] and red.y + VELOCITY + red.height < HEIGHT - 15:
62 red.y += VELOCITY
63
64# Функция движения желтого корабля
65def yellow_handle_movement(keys_pressed, yellow):
66 # Движение ВЛЕВО (запрещаем пересекать границу игроков)
67 if keys_pressed[pygame.K_LEFT] and yellow.x - VELOCITY > BORDER.x + BORDER.width:
68 yellow.x -= VELOCITY
69 # Движение ВПРАВО
70 if keys_pressed[pygame.K_RIGHT] and yellow.x + VELOCITY + yellow.width < WIDTH:
71 yellow.x += VELOCITY
72 # Движение ВВЕРХ
73 if keys_pressed[pygame.K_UP] and yellow.y - VELOCITY > 0:
74 yellow.y -= VELOCITY
75 # Движение ВНИЗ
76 if keys_pressed[pygame.K_DOWN] and yellow.y + VELOCITY + yellow.height < HEIGHT - 15:
77 yellow.y += VELOCITY
78
79
80# Запускаем бесконечный цикл программы
81# Это делается чтобы программа не завершалась и постоянно рисовала новые кадры игры
82while True:
83 # Рисуем изображение на заднем фоне
84 screen.blit(SPACE_BG, (0, 0))
85
86 # Рисуем прямоугольник
87 pygame.draw.rect(screen, "white", BORDER)
88
89 # Рисуем корабли
90 screen.blit(YELLOW_SPACESHIP, (yellow.x, yellow.y))
91 screen.blit(RED_SPACESHIP, (red.x, red.y))
92
93 # Постоянно проверяем события игры и если присутствует событие Выход - останавливаем игру.
94 for event in pygame.event.get():
95 if event.type == pygame.QUIT:
96 pygame.quit()
97
98 # Узнаем нажатие клавишей
99 keys_pressed = pygame.key.get_pressed()
100 # Выполняем установку координат кораблей
101 red_handle_movement(keys_pressed, red)
102 yellow_handle_movement(keys_pressed, yellow)
103
104 # Обновляем кадры игры
105 pygame.display.update()Ограничитель кадров
Сейчас корабли движутся слишком быстро. Это происходит потому, что наши корабли меняют свое положения в зависимости от скорости цикла While. Дело в том что цикл While очень быстрый и такие простые операции могут выполняться до нескольких тысяч раз в секунду. Это означает что скорость игры и отрисовки кадров будет зависеть от производительности процессора. Нам это не подходит. Давайте добавим ограничитель кадров.
Добавьте константу - количество кадров в секунду (frame per second):
1# Количество кадров в секунду
2FPS = 60Затем создайте специальный объект ограничитель кадров.
1# Ограничитель кадров
2clock = pygame.time.Clock()И теперь добавьте строчку clock.tick(FPS) сразу после вызова цикла:
1# Запускаем бесконечный цикл программы
2# Это делается чтобы программа не завершалась и постоянно рисовала новые кадры игры
3while True:
4 # Ограничиваем количество кадров игры
5 clock.tick(FPS)Благодаря этому коду, цикл будет вызываться не чаще чем 60 раз в секунду. Это то, что нам нужно. Сохраните, запустите, проверьте.
Но теперь корабли движутся очень медленно. Все верно, ведь мы так сильно сократили количество проверок нажатых клавиш. Поправить это просто - поднимите значение VELOCITY. Я подниму до 5.
Промежуточный результат #5
Работает:
- Кнопка закрыть/свернуть
- Отображается задний фон
- Разделитель экрана
- Отрисовка игроков
- Движение игроков
- Ограничитель кадров
1# Подключаем игровой движок Pygame
2import pygame
3# Подключаем модуль для работы с файловой системой
4import os
5
6# Подготавливаем необходимые модули Pygame
7pygame.init()
8
9### Константы ###
10# Константы размера окна
11WIDTH = 600
12HEIGHT = 300
13# Размеры корабля
14SPACESHIP_WIDTH = 55
15SPACESHIP_HEIGHT = 40
16# Скорость корабля
17VELOCITY = 5
18# Количество кадров в секунду
19FPS = 60
20
21# Ограничитель кадров
22clock = pygame.time.Clock()
23
24# Задаем размеры игрового окна
25screen = pygame.display.set_mode((WIDTH, HEIGHT))
26
27# Загружаем изображение в память
28SPACE_IMAGE = pygame.image.load(os.path.join('./assets', 'space.jpg'))
29
30# Создаем объект фона с разрешением окна
31SPACE_BG = pygame.transform.scale(SPACE_IMAGE, (WIDTH, HEIGHT))
32
33# Формируем объект границы
34BORDER = pygame.Rect(WIDTH//2 - 2, 0, 4, HEIGHT)
35
36# Загружаем изображение красного корабля
37RED_SPACESHIP_IMAGE = pygame.image.load(
38 os.path.join('./assets', 'spaceship_red.png'))
39# Разворачиваем изображение в нужном направлении
40RED_SPACESHIP = pygame.transform.rotate(pygame.transform.scale(
41 RED_SPACESHIP_IMAGE, (SPACESHIP_WIDTH, SPACESHIP_HEIGHT)), 90)
42
43# Загружаем изображение желтого корабля
44YELLOW_SPACESHIP_IMAGE = pygame.image.load(
45 os.path.join('./assets', 'spaceship_yellow.png'))
46# Разворачиваем изображение в нужном направлении
47YELLOW_SPACESHIP = pygame.transform.rotate(pygame.transform.scale(
48 YELLOW_SPACESHIP_IMAGE, (SPACESHIP_WIDTH, SPACESHIP_HEIGHT)), 270)
49
50# Создаем два объекта/прямоугольника
51red = pygame.Rect(100, 150, SPACESHIP_WIDTH, SPACESHIP_HEIGHT)
52yellow = pygame.Rect(500, 150, SPACESHIP_WIDTH, SPACESHIP_HEIGHT)
53
54# Функция движения красного корабля
55def red_handle_movement(keys_pressed, red):
56 # Движение ВЛЕВО
57 if keys_pressed[pygame.K_a] and red.x - VELOCITY > 0:
58 red.x -= VELOCITY
59 # Движение ВПРАВО (запрещаем пересекать границу игроков)
60 if keys_pressed[pygame.K_d] and red.x + VELOCITY + red.width < BORDER.x:
61 red.x += VELOCITY
62 # Движение ВВЕРХ (запрещаем подниматься выше 0 по координате y)
63 if keys_pressed[pygame.K_w] and red.y - VELOCITY > 0:
64 red.y -= VELOCITY
65 # Движение ВНИЗ (запрещаем опускаться ниже чем высота экрана за вычетом высоты корабля и дополнительных 15 для отступа)
66 if keys_pressed[pygame.K_s] and red.y + VELOCITY + red.height < HEIGHT - 15:
67 red.y += VELOCITY
68
69# Функция движения желтого корабля
70def yellow_handle_movement(keys_pressed, yellow):
71 # Движение ВЛЕВО (запрещаем пересекать границу игроков)
72 if keys_pressed[pygame.K_LEFT] and yellow.x - VELOCITY > BORDER.x + BORDER.width:
73 yellow.x -= VELOCITY
74 # Движение ВПРАВО
75 if keys_pressed[pygame.K_RIGHT] and yellow.x + VELOCITY + yellow.width < WIDTH:
76 yellow.x += VELOCITY
77 # Движение ВВЕРХ
78 if keys_pressed[pygame.K_UP] and yellow.y - VELOCITY > 0:
79 yellow.y -= VELOCITY
80 # Движение ВНИЗ
81 if keys_pressed[pygame.K_DOWN] and yellow.y + VELOCITY + yellow.height < HEIGHT - 15:
82 yellow.y += VELOCITY
83
84
85# Запускаем бесконечный цикл программы
86# Это делается чтобы программа не завершалась и постоянно рисовала новые кадры игры
87while True:
88 # Ограничиваем количество кадров игры
89 clock.tick(FPS)
90
91 # Рисуем изображение на заднем фоне
92 screen.blit(SPACE_BG, (0, 0))
93
94 # Рисуем прямоугольник
95 pygame.draw.rect(screen, "white", BORDER)
96
97 # Рисуем корабли
98 screen.blit(YELLOW_SPACESHIP, (yellow.x, yellow.y))
99 screen.blit(RED_SPACESHIP, (red.x, red.y))
100
101 # Постоянно проверяем события игры и если присутствует событие Выход - останавливаем игру.
102 for event in pygame.event.get():
103 if event.type == pygame.QUIT:
104 pygame.quit()
105
106 # Узнаем нажатие клавишей
107 keys_pressed = pygame.key.get_pressed()
108 # Выполняем установку координат кораблей
109 red_handle_movement(keys_pressed, red)
110 yellow_handle_movement(keys_pressed, yellow)
111
112 # Обновляем кадры игры
113 pygame.display.update()
114
115Здоровье игроков
Теперь добавим отображение здоровья игроков.
Создайте две переменные для хранения здоровья игроков:
1# Здоровье игроков
2red_health = 10
3yellow_health = 10Так же к константам добавьте переменную шрифта:
1# Шрифт здоровья
2HEALTH_FONT = pygame.font.SysFont('comicsans', 20)Отлично. Теперь в бесконечном цикле отрисовки нарисуем текст:
1# Отображаем здоровье на экране
2red_health_text = HEALTH_FONT.render(
3 "Health: " + str(red_health), 1, "white")
4yellow_health_text = HEALTH_FONT.render(
5 "Health: " + str(yellow_health), 1, "white")
6screen.blit(red_health_text, (10, 10))
7screen.blit(yellow_health_text, (WIDTH - red_health_text.get_width() - 10, 10))Обратите внимание, что рисовать текст здоровья нужно последним, иначе если сначала отрисовать текст, а затем задний фон, то последний просто перекроет текст.
Должно получиться так:

Промежуточный результат #6
Работает:
- Кнопка закрыть/свернуть
- Отображается задний фон
- Разделитель экрана
- Отрисовка игроков
- Движение игроков
- Ограничитель кадров
- Здоровье игроков
1# Подключаем игровой движок Pygame
2import pygame
3# Подключаем модуль для работы с файловой системой
4import os
5
6# Подготавливаем необходимые модули Pygame
7pygame.init()
8
9### Константы ###
10# Константы размера окна
11WIDTH = 600
12HEIGHT = 300
13# Размеры корабля
14SPACESHIP_WIDTH = 55
15SPACESHIP_HEIGHT = 40
16# Скорость корабля
17VELOCITY = 5
18# Количество кадров в секунду
19FPS = 60
20# Шрифт здоровья
21HEALTH_FONT = pygame.font.SysFont('comicsans', 20)
22
23# Ограничитель кадров
24clock = pygame.time.Clock()
25
26# Задаем размеры игрового окна
27screen = pygame.display.set_mode((WIDTH, HEIGHT))
28
29# Загружаем изображение в память
30SPACE_IMAGE = pygame.image.load(os.path.join('./assets', 'space.jpg'))
31
32# Создаем объект фона с разрешением окна
33SPACE_BG = pygame.transform.scale(SPACE_IMAGE, (WIDTH, HEIGHT))
34
35# Формируем объект границы
36BORDER = pygame.Rect(WIDTH//2 - 2, 0, 4, HEIGHT)
37
38# Загружаем изображение красного корабля
39RED_SPACESHIP_IMAGE = pygame.image.load(
40 os.path.join('./assets', 'spaceship_red.png'))
41# Разворачиваем изображение в нужном направлении
42RED_SPACESHIP = pygame.transform.rotate(pygame.transform.scale(
43 RED_SPACESHIP_IMAGE, (SPACESHIP_WIDTH, SPACESHIP_HEIGHT)), 90)
44
45# Загружаем изображение желтого корабля
46YELLOW_SPACESHIP_IMAGE = pygame.image.load(
47 os.path.join('./assets', 'spaceship_yellow.png'))
48# Разворачиваем изображение в нужном направлении
49YELLOW_SPACESHIP = pygame.transform.rotate(pygame.transform.scale(
50 YELLOW_SPACESHIP_IMAGE, (SPACESHIP_WIDTH, SPACESHIP_HEIGHT)), 270)
51
52# Создаем два объекта/прямоугольника
53red = pygame.Rect(100, 150, SPACESHIP_WIDTH, SPACESHIP_HEIGHT)
54yellow = pygame.Rect(500, 150, SPACESHIP_WIDTH, SPACESHIP_HEIGHT)
55
56# Здоровье игроков
57red_health = 10
58yellow_health = 10
59
60# Функция движения красного корабля
61def red_handle_movement(keys_pressed, red):
62 # Движение ВЛЕВО
63 if keys_pressed[pygame.K_a] and red.x - VELOCITY > 0:
64 red.x -= VELOCITY
65 # Движение ВПРАВО (запрещаем пересекать границу игроков)
66 if keys_pressed[pygame.K_d] and red.x + VELOCITY + red.width < BORDER.x:
67 red.x += VELOCITY
68 # Движение ВВЕРХ (запрещаем подниматься выше 0 по координате y)
69 if keys_pressed[pygame.K_w] and red.y - VELOCITY > 0:
70 red.y -= VELOCITY
71 # Движение ВНИЗ (запрещаем опускаться ниже чем высота экрана за вычетом высоты корабля и дополнительных 15 для отступа)
72 if keys_pressed[pygame.K_s] and red.y + VELOCITY + red.height < HEIGHT - 15:
73 red.y += VELOCITY
74
75# Функция движения желтого корабля
76def yellow_handle_movement(keys_pressed, yellow):
77 # Движение ВЛЕВО (запрещаем пересекать границу игроков)
78 if keys_pressed[pygame.K_LEFT] and yellow.x - VELOCITY > BORDER.x + BORDER.width:
79 yellow.x -= VELOCITY
80 # Движение ВПРАВО
81 if keys_pressed[pygame.K_RIGHT] and yellow.x + VELOCITY + yellow.width < WIDTH:
82 yellow.x += VELOCITY
83 # Движение ВВЕРХ
84 if keys_pressed[pygame.K_UP] and yellow.y - VELOCITY > 0:
85 yellow.y -= VELOCITY
86 # Движение ВНИЗ
87 if keys_pressed[pygame.K_DOWN] and yellow.y + VELOCITY + yellow.height < HEIGHT - 15:
88 yellow.y += VELOCITY
89
90
91# Запускаем бесконечный цикл программы
92# Это делается чтобы программа не завершалась и постоянно рисовала новые кадры игры
93while True:
94 # Ограничиваем количество кадров игры
95 clock.tick(FPS)
96
97 # Рисуем изображение на заднем фоне
98 screen.blit(SPACE_BG, (0, 0))
99
100 # Рисуем прямоугольник
101 pygame.draw.rect(screen, "white", BORDER)
102
103 # Рисуем корабли
104 screen.blit(YELLOW_SPACESHIP, (yellow.x, yellow.y))
105 screen.blit(RED_SPACESHIP, (red.x, red.y))
106
107 # Отображаем здоровье на экране
108 red_health_text = HEALTH_FONT.render(
109 "Health: " + str(red_health), 1, "white")
110 yellow_health_text = HEALTH_FONT.render(
111 "Health: " + str(yellow_health), 1, "white")
112 screen.blit(red_health_text, (10, 10))
113 screen.blit(yellow_health_text, (WIDTH - red_health_text.get_width() - 10, 10))
114
115 # Постоянно проверяем события игры и если присутствует событие Выход - останавливаем игру.
116 for event in pygame.event.get():
117 if event.type == pygame.QUIT:
118 pygame.quit()
119
120 # Узнаем нажатие клавишей
121 keys_pressed = pygame.key.get_pressed()
122 # Выполняем установку координат кораблей
123 red_handle_movement(keys_pressed, red)
124 yellow_handle_movement(keys_pressed, yellow)
125
126 # Обновляем кадры игры
127 pygame.display.update()Выстрелы
Наконец добавим выстрелы. Выстрелы будет работать следующий образом. Каждый игрок может выпустить до трех пуль за раз. Пока они не попадут в цель или не покинут экран, игрок не сможет сделать дополнительный выстрел. При попадании пули у игрока будет отниматься здоровье.
Создайте переменные для хранения выпущенных пуль, переменную для максимального количества выпущенных пуль, а так же переменную - скорость пули:
1# Хранение выпущенных пуль
2red_bullets = []
3yellow_bullets = []
4# Макс. выпущенных пуль
5MAX_BULLETS = 3
6# Скорость пули
7BULLET_VEL = 7Так же создайте два новых пользовательских события - попадание в красного и попадание в желтого:
1# Пользовательские события попаданий
2YELLOW_HIT = pygame.USEREVENT + 1
3RED_HIT = pygame.USEREVENT + 2Плюс один и плюс два просто позволяют создать новые коды событий, нам они понадобятся ниже.
В блок, где мы перебирали все события игры, и искали событие закрытия программы, чтобы отобразить кнопку закрыть, добавьте следующий код:
1# Постоянно проверяем события игры и если присутствует событие Выход - останавливаем игру.
2for event in pygame.event.get():
3 if event.type == pygame.QUIT:
4 pygame.quit()
5
6 # Если произошло событие нажатия клавиши
7 if event.type == pygame.KEYDOWN:
8 # И нажали клавишу Пробел, а так же если длина листа выпущенных пуль красного меньше минимального
9 if event.key == pygame.K_SPACE and len(red_bullets) < MAX_BULLETS:
10 # Создаем объект прямоугольника для Пули
11 bullet = pygame.Rect(
12 red.x + red.width, red.y + red.height//2 - 2, 10, 5)
13 # Добавляем выпущенную пулю красному
14 red_bullets.append(bullet)
15
16 # Если нажали клавишу Enter, создаем выпущенную пулю желтому игроку
17 if event.key == pygame.K_RETURN and len(yellow_bullets) < MAX_BULLETS:
18 # Создаем объект прямоугольника для Пули
19 bullet = pygame.Rect(
20 yellow.x, yellow.y + yellow.height//2 - 2, 10, 5)
21 # Добавляем выпущенную пулю желтому
22 yellow_bullets.append(bullet)Благодаря этому коду, мы программно выпускаем пули у игроков и сохраняем выпущенные пули в соответствующих списках.
Теперь нужно обработать попадания и вылет пуль за экран.
Напишите следующую функцию:
1# Обработка выпущенных пуль
2def handle_bullets(yellow_bullets, red_bullets, yellow, red):
3 # Перебираем все пули красного
4 for bullet in red_bullets:
5 # Двигаем пулю вправо
6 bullet.x += BULLET_VEL
7 # Если пуля задевает желтого игрока
8 if yellow.colliderect(bullet):
9 # Вызываем пользовательское событие попадание в Желтого
10 pygame.event.post(pygame.event.Event(YELLOW_HIT))
11 # Удаляем текущую пулю
12 red_bullets.remove(bullet)
13 # Удаляем пулю если она вышла за экран
14 elif bullet.x > WIDTH:
15 red_bullets.remove(bullet)
16
17 # Перебираем все пули желтого
18 for bullet in yellow_bullets:
19 # Двигаем пулю влево
20 bullet.x -= BULLET_VEL
21 # Если пуля задевает красного игрока
22 if red.colliderect(bullet):
23 # Вызываем пользовательское событие попадание в Красного
24 pygame.event.post(pygame.event.Event(RED_HIT))
25 # Удаляем текущую пулю
26 yellow_bullets.remove(bullet)
27 # Удаляем пулю если она вышла за экран
28 elif bullet.x < 0:
29 yellow_bullets.remove(bullet)Данная функция передвигает выстрелы, проверяет вылеты пули за экран, при этом удаляя пулю из листа, а так же проверяет попадание пули в корабли (метод colliderect) и если попадание случилось - вызывает соответствующее пользовательское событие.
Отлично, мы сделали выпуск пуль по нажатиям на клавиши, мы сделали обработку попаданий, но пуль все еще нет на экране. Пора отрисовать их.
Добавьте в бесконечный цикл следующий код:
1# Перебираем пули красного и рисуем каждый кадр
2for bullet in red_bullets:
3 pygame.draw.rect(screen, "red", bullet)
4# Перебираем пули желтого и рисуем каждый кадр
5for bullet in yellow_bullets:
6 pygame.draw.rect(screen, "yellow", bullet)Каждый кадр мы проверяем наличие пуль в листе и рисуем их.
Ура! Теперь наши корабли стреляют!
Промежуточный результат #7
Работает:
- Кнопка закрыть/свернуть
- Отображается задний фон
- Разделитель экрана
- Отрисовка игроков
- Движение игроков
- Ограничитель кадров
- Здоровье игроков
- Выстрелы кораблей
1# Подключаем игровой движок Pygame
2import pygame
3# Подключаем модуль для работы с файловой системой
4import os
5
6# Подготавливаем необходимые модули Pygame
7pygame.init()
8
9### Константы ###
10# Константы размера окна
11WIDTH = 600
12HEIGHT = 300
13# Размеры корабля
14SPACESHIP_WIDTH = 55
15SPACESHIP_HEIGHT = 40
16# Скорость корабля
17VELOCITY = 5
18# Количество кадров в секунду
19FPS = 60
20# Шрифт здоровья
21HEALTH_FONT = pygame.font.SysFont('comicsans', 20)
22# Пользовательские события попаданий
23YELLOW_HIT = pygame.USEREVENT + 1
24RED_HIT = pygame.USEREVENT + 2
25
26# Ограничитель кадров
27clock = pygame.time.Clock()
28
29# Задаем размеры игрового окна
30screen = pygame.display.set_mode((WIDTH, HEIGHT))
31
32# Загружаем изображение в память
33SPACE_IMAGE = pygame.image.load(os.path.join('./assets', 'space.jpg'))
34
35# Создаем объект фона с разрешением окна
36SPACE_BG = pygame.transform.scale(SPACE_IMAGE, (WIDTH, HEIGHT))
37
38# Формируем объект границы
39BORDER = pygame.Rect(WIDTH//2 - 2, 0, 4, HEIGHT)
40
41# Загружаем изображение красного корабля
42RED_SPACESHIP_IMAGE = pygame.image.load(
43 os.path.join('./assets', 'spaceship_red.png'))
44# Разворачиваем изображение в нужном направлении
45RED_SPACESHIP = pygame.transform.rotate(pygame.transform.scale(
46 RED_SPACESHIP_IMAGE, (SPACESHIP_WIDTH, SPACESHIP_HEIGHT)), 90)
47
48# Загружаем изображение желтого корабля
49YELLOW_SPACESHIP_IMAGE = pygame.image.load(
50 os.path.join('./assets', 'spaceship_yellow.png'))
51# Разворачиваем изображение в нужном направлении
52YELLOW_SPACESHIP = pygame.transform.rotate(pygame.transform.scale(
53 YELLOW_SPACESHIP_IMAGE, (SPACESHIP_WIDTH, SPACESHIP_HEIGHT)), 270)
54
55# Создаем два объекта/прямоугольника
56red = pygame.Rect(100, 150, SPACESHIP_WIDTH, SPACESHIP_HEIGHT)
57yellow = pygame.Rect(500, 150, SPACESHIP_WIDTH, SPACESHIP_HEIGHT)
58
59# Здоровье игроков
60red_health = 10
61yellow_health = 10
62
63# Хранение выпущенных пуль
64red_bullets = []
65yellow_bullets = []
66# Макс. выпущенных пуль
67MAX_BULLETS = 3
68# Скорость пули
69BULLET_VEL = 7
70
71# Функция движения красного корабля
72def red_handle_movement(keys_pressed, red):
73 # Движение ВЛЕВО
74 if keys_pressed[pygame.K_a] and red.x - VELOCITY > 0:
75 red.x -= VELOCITY
76 # Движение ВПРАВО (запрещаем пересекать границу игроков)
77 if keys_pressed[pygame.K_d] and red.x + VELOCITY + red.width < BORDER.x:
78 red.x += VELOCITY
79 # Движение ВВЕРХ (запрещаем подниматься выше 0 по координате y)
80 if keys_pressed[pygame.K_w] and red.y - VELOCITY > 0:
81 red.y -= VELOCITY
82 # Движение ВНИЗ (запрещаем опускаться ниже чем высота экрана за вычетом высоты корабля и дополнительных 15 для отступа)
83 if keys_pressed[pygame.K_s] and red.y + VELOCITY + red.height < HEIGHT - 15:
84 red.y += VELOCITY
85
86# Функция движения желтого корабля
87def yellow_handle_movement(keys_pressed, yellow):
88 # Движение ВЛЕВО (запрещаем пересекать границу игроков)
89 if keys_pressed[pygame.K_LEFT] and yellow.x - VELOCITY > BORDER.x + BORDER.width:
90 yellow.x -= VELOCITY
91 # Движение ВПРАВО
92 if keys_pressed[pygame.K_RIGHT] and yellow.x + VELOCITY + yellow.width < WIDTH:
93 yellow.x += VELOCITY
94 # Движение ВВЕРХ
95 if keys_pressed[pygame.K_UP] and yellow.y - VELOCITY > 0:
96 yellow.y -= VELOCITY
97 # Движение ВНИЗ
98 if keys_pressed[pygame.K_DOWN] and yellow.y + VELOCITY + yellow.height < HEIGHT - 15:
99 yellow.y += VELOCITY
100
101# Обработка выпущенных пуль
102def handle_bullets(yellow_bullets, red_bullets, yellow, red):
103 # Перебираем все пули красного
104 for bullet in red_bullets:
105 # Двигаем пулю вправо
106 bullet.x += BULLET_VEL
107 # Если пуля задевает желтого игрока
108 if yellow.colliderect(bullet):
109 # Вызываем пользовательское событие попадание в Желтого
110 pygame.event.post(pygame.event.Event(YELLOW_HIT))
111 # Удаляем текущую пулю
112 red_bullets.remove(bullet)
113 # Удаляем пулю если она вышла за экран
114 elif bullet.x > WIDTH:
115 red_bullets.remove(bullet)
116
117 # Перебираем все пули желтого
118 for bullet in yellow_bullets:
119 # Двигаем пулю влево
120 bullet.x -= BULLET_VEL
121 # Если пуля задевает красного игрока
122 if red.colliderect(bullet):
123 # Вызываем пользовательское событие попадание в Красного
124 pygame.event.post(pygame.event.Event(RED_HIT))
125 # Удаляем текущую пулю
126 yellow_bullets.remove(bullet)
127 # Удаляем пулю если она вышла за экран
128 elif bullet.x < 0:
129 yellow_bullets.remove(bullet)
130
131
132# Запускаем бесконечный цикл программы
133# Это делается чтобы программа не завершалась и постоянно рисовала новые кадры игры
134while True:
135 # Ограничиваем количество кадров игры
136 clock.tick(FPS)
137
138 # Рисуем изображение на заднем фоне
139 screen.blit(SPACE_BG, (0, 0))
140
141 # Рисуем прямоугольник
142 pygame.draw.rect(screen, "white", BORDER)
143
144 # Рисуем корабли
145 screen.blit(YELLOW_SPACESHIP, (yellow.x, yellow.y))
146 screen.blit(RED_SPACESHIP, (red.x, red.y))
147
148 # Отображаем здоровье на экране
149 red_health_text = HEALTH_FONT.render(
150 "Health: " + str(red_health), 1, "white")
151 yellow_health_text = HEALTH_FONT.render(
152 "Health: " + str(yellow_health), 1, "white")
153 screen.blit(red_health_text, (10, 10))
154 screen.blit(yellow_health_text, (WIDTH - red_health_text.get_width() - 10, 10))
155
156 # Постоянно проверяем события игры и если присутствует событие Выход - останавливаем игру.
157 for event in pygame.event.get():
158 if event.type == pygame.QUIT:
159 pygame.quit()
160
161 # Если произошло событие нажатия клавиши
162 if event.type == pygame.KEYDOWN:
163 # И нажали клавишу Пробел, а так же если длина листа выпущенных пуль красного меньше минимального
164 if event.key == pygame.K_SPACE and len(red_bullets) < MAX_BULLETS:
165 # Создаем объект прямоугольника для Пули
166 bullet = pygame.Rect(
167 red.x + red.width, red.y + red.height//2 - 2, 10, 5)
168 # Добавляем выпущенную пулю красному
169 red_bullets.append(bullet)
170
171 # Если нажали клавишу Enter, создаем выпущенную пулю желтому игроку
172 if event.key == pygame.K_RETURN and len(yellow_bullets) < MAX_BULLETS:
173 # Создаем объект прямоугольника для Пули
174 bullet = pygame.Rect(
175 yellow.x, yellow.y + yellow.height//2 - 2, 10, 5)
176 # Добавляем выпущенную пулю желтому
177 yellow_bullets.append(bullet)
178
179 # Узнаем нажатие клавишей
180 keys_pressed = pygame.key.get_pressed()
181 # Выполняем установку координат кораблей
182 red_handle_movement(keys_pressed, red)
183 yellow_handle_movement(keys_pressed, yellow)
184
185 # Проверяем столкновения пуль
186 handle_bullets(yellow_bullets, red_bullets, yellow, red)
187
188 # Перебираем пули красного и рисуем каждый кадр
189 for bullet in red_bullets:
190 pygame.draw.rect(screen, "red", bullet)
191 # Перебираем пули желтого и рисуем каждый кадр
192 for bullet in yellow_bullets:
193 pygame.draw.rect(screen, "yellow", bullet)
194
195 # Обновляем кадры игры
196 pygame.display.update()
197Учет попаданий - Отображение победителя
Теперь нужно при попадании уменьшать здоровье игроков. Ранее мы создали пользовательские события RED_HIT и YELLOW_HIT и при попадании в соответствующего игрока вызвали соответствующее событие. Теперь достаточно обработать эти события.
Добавьте этот код к участку кода где мы проверяли события нажатия кнопки выйти и нажатия кнопок Space (Пробел) и Enter.
1# Если случилось пользовательское событие RED_HIT отнимаем жизни у Красного
2if event.type == RED_HIT:
3 red_health -= 1
4
5# Если случилось пользовательское событие YELLOW_HIT отнимаем жизни у Желтого
6if event.type == YELLOW_HIT:
7 yellow_health -= 1Если случилось пользовательское событие RED_HIT отнимаем жизни у Красного, если событие YELLOW_HIT отнимаем жизни у Желтого. Думаю теперь стало понятно для чего мы делали пользовательские события. Проверьте. Теперь здоровье должно отниматься, и визуально тоже.
Сейчас здоровье может уходить в минус. Давайте будем проверять - если здоровье упало до нуля, покажем сообщение - Имя победителя, а затем обнулим игровые счетчики.
Напишите следующую функцию:
1# Функция рисует экран победителя
2def draw_winner(text):
3 # Создаем шрифт для победителя
4 WINNER_FONT = pygame.font.SysFont('comicsans', 60)
5 # Создаем надпись
6 draw_text = WINNER_FONT.render(text, 1, 'white')
7 # Устанавливаем надпись в центре игрового поля
8 screen.blit(draw_text, (WIDTH/2 - draw_text.get_width() /
9 2, HEIGHT/2 - draw_text.get_height()/2))
10
11 # Обновляем кадр игры
12 pygame.display.update()
13 # Задержка после победы
14 pygame.time.delay(2000)Эта функция позволит нарисовать имя победителя по центру экрана, а так же сделать паузы игры на две секунды чтобы игроки не могли управлять игрой в момент отображения победителя.
Теперь в секции бесконечного цикла добавьте этот код:
1# Если здоровье упало до нуля, рисуем имя победителя.
2winner_text = ""
3if red_health <= 0:
4 winner_text = "Yellow Wins!"
5
6if yellow_health <= 0:
7 winner_text = "Red Wins!"
8
9if winner_text != "":
10 draw_winner(winner_text)
11 # Обнуляем пули
12 red_bullets.clear()
13 yellow_bullets.clear()
14 # Восстанавливаем здоровье
15 red_health = 10
16 yellow_health = 10Каждый кадр игры мы проверяем, не опустился ли показатель здоровья одного из игроков до нуля и если это случилось, рисуем имя победителя, затем делаем паузу в две секунды, затем обнуляем все показатели игры - выстрелы и здоровье.
Поздравляю - база игры готова!

Промежуточный результат #8
Работает:
- Кнопка закрыть/свернуть
- Отображается задний фон
- Разделитель экрана
- Отрисовка игроков
- Движение игроков
- Ограничитель кадров
- Здоровье игроков
- Выстрелы кораблей
- Экран победителя и обнуление показателей
1# Подключаем игровой движок Pygame
2import pygame
3# Подключаем модуль для работы с файловой системой
4import os
5
6# Подготавливаем необходимые модули Pygame
7pygame.init()
8
9### Константы ###
10# Константы размера окна
11WIDTH = 600
12HEIGHT = 300
13# Размеры корабля
14SPACESHIP_WIDTH = 55
15SPACESHIP_HEIGHT = 40
16# Скорость корабля
17VELOCITY = 5
18# Количество кадров в секунду
19FPS = 60
20# Шрифт здоровья
21HEALTH_FONT = pygame.font.SysFont('comicsans', 20)
22# Пользовательские события попаданий
23YELLOW_HIT = pygame.USEREVENT + 1
24RED_HIT = pygame.USEREVENT + 2
25
26# Ограничитель кадров
27clock = pygame.time.Clock()
28
29# Задаем размеры игрового окна
30screen = pygame.display.set_mode((WIDTH, HEIGHT))
31
32# Загружаем изображение в память
33SPACE_IMAGE = pygame.image.load(os.path.join('./assets', 'space.jpg'))
34
35# Создаем объект фона с разрешением окна
36SPACE_BG = pygame.transform.scale(SPACE_IMAGE, (WIDTH, HEIGHT))
37
38# Формируем объект границы
39BORDER = pygame.Rect(WIDTH//2 - 2, 0, 4, HEIGHT)
40
41# Загружаем изображение красного корабля
42RED_SPACESHIP_IMAGE = pygame.image.load(
43 os.path.join('./assets', 'spaceship_red.png'))
44# Разворачиваем изображение в нужном направлении
45RED_SPACESHIP = pygame.transform.rotate(pygame.transform.scale(
46 RED_SPACESHIP_IMAGE, (SPACESHIP_WIDTH, SPACESHIP_HEIGHT)), 90)
47
48# Загружаем изображение желтого корабля
49YELLOW_SPACESHIP_IMAGE = pygame.image.load(
50 os.path.join('./assets', 'spaceship_yellow.png'))
51# Разворачиваем изображение в нужном направлении
52YELLOW_SPACESHIP = pygame.transform.rotate(pygame.transform.scale(
53 YELLOW_SPACESHIP_IMAGE, (SPACESHIP_WIDTH, SPACESHIP_HEIGHT)), 270)
54
55# Создаем два объекта/прямоугольника
56red = pygame.Rect(100, 150, SPACESHIP_WIDTH, SPACESHIP_HEIGHT)
57yellow = pygame.Rect(500, 150, SPACESHIP_WIDTH, SPACESHIP_HEIGHT)
58
59# Здоровье игроков
60red_health = 10
61yellow_health = 10
62
63# Хранение выпущенных пуль
64red_bullets = []
65yellow_bullets = []
66# Макс. выпущенных пуль
67MAX_BULLETS = 3
68# Скорость пули
69BULLET_VEL = 7
70
71# Функция движения красного корабля
72def red_handle_movement(keys_pressed, red):
73 # Движение ВЛЕВО
74 if keys_pressed[pygame.K_a] and red.x - VELOCITY > 0:
75 red.x -= VELOCITY
76 # Движение ВПРАВО (запрещаем пересекать границу игроков)
77 if keys_pressed[pygame.K_d] and red.x + VELOCITY + red.width < BORDER.x:
78 red.x += VELOCITY
79 # Движение ВВЕРХ (запрещаем подниматься выше 0 по координате y)
80 if keys_pressed[pygame.K_w] and red.y - VELOCITY > 0:
81 red.y -= VELOCITY
82 # Движение ВНИЗ (запрещаем опускаться ниже чем высота экрана за вычетом высоты корабля и дополнительных 15 для отступа)
83 if keys_pressed[pygame.K_s] and red.y + VELOCITY + red.height < HEIGHT - 15:
84 red.y += VELOCITY
85
86# Функция движения желтого корабля
87def yellow_handle_movement(keys_pressed, yellow):
88 # Движение ВЛЕВО (запрещаем пересекать границу игроков)
89 if keys_pressed[pygame.K_LEFT] and yellow.x - VELOCITY > BORDER.x + BORDER.width:
90 yellow.x -= VELOCITY
91 # Движение ВПРАВО
92 if keys_pressed[pygame.K_RIGHT] and yellow.x + VELOCITY + yellow.width < WIDTH:
93 yellow.x += VELOCITY
94 # Движение ВВЕРХ
95 if keys_pressed[pygame.K_UP] and yellow.y - VELOCITY > 0:
96 yellow.y -= VELOCITY
97 # Движение ВНИЗ
98 if keys_pressed[pygame.K_DOWN] and yellow.y + VELOCITY + yellow.height < HEIGHT - 15:
99 yellow.y += VELOCITY
100
101# Обработка выпущенных пуль
102def handle_bullets(yellow_bullets, red_bullets, yellow, red):
103 # Перебираем все пули красного
104 for bullet in red_bullets:
105 # Двигаем пулю вправо
106 bullet.x += BULLET_VEL
107 # Если пуля задевает желтого игрока
108 if yellow.colliderect(bullet):
109 # Вызываем пользовательское событие попадание в Желтого
110 pygame.event.post(pygame.event.Event(YELLOW_HIT))
111 # Удаляем текущую пулю
112 red_bullets.remove(bullet)
113 # Удаляем пулю если она вышла за экран
114 elif bullet.x > WIDTH:
115 red_bullets.remove(bullet)
116
117 # Перебираем все пули желтого
118 for bullet in yellow_bullets:
119 # Двигаем пулю влево
120 bullet.x -= BULLET_VEL
121 # Если пуля задевает красного игрока
122 if red.colliderect(bullet):
123 # Вызываем пользовательское событие попадание в Красного
124 pygame.event.post(pygame.event.Event(RED_HIT))
125 # Удаляем текущую пулю
126 yellow_bullets.remove(bullet)
127 # Удаляем пулю если она вышла за экран
128 elif bullet.x < 0:
129 yellow_bullets.remove(bullet)
130
131# Функция рисует экран победителя
132def draw_winner(text):
133 # Создаем шрифт для победителя
134 WINNER_FONT = pygame.font.SysFont('comicsans', 60)
135 # Создаем надпись
136 draw_text = WINNER_FONT.render(text, 1, 'white')
137 # Устанавливаем надпись в центре игрового поля
138 screen.blit(draw_text, (WIDTH/2 - draw_text.get_width() /
139 2, HEIGHT/2 - draw_text.get_height()/2))
140
141 # Обновляем кадр игры
142 pygame.display.update()
143 # Задержка после победы
144 pygame.time.delay(2000)
145
146# Запускаем бесконечный цикл программы
147# Это делается чтобы программа не завершалась и постоянно рисовала новые кадры игры
148while True:
149 # Ограничиваем количество кадров игры
150 clock.tick(FPS)
151
152 # Рисуем изображение на заднем фоне
153 screen.blit(SPACE_BG, (0, 0))
154
155 # Рисуем прямоугольник
156 pygame.draw.rect(screen, "white", BORDER)
157
158 # Рисуем корабли
159 screen.blit(YELLOW_SPACESHIP, (yellow.x, yellow.y))
160 screen.blit(RED_SPACESHIP, (red.x, red.y))
161
162 # Отображаем здоровье на экране
163 red_health_text = HEALTH_FONT.render(
164 "Health: " + str(red_health), 1, "white")
165 yellow_health_text = HEALTH_FONT.render(
166 "Health: " + str(yellow_health), 1, "white")
167 screen.blit(red_health_text, (10, 10))
168 screen.blit(yellow_health_text, (WIDTH - red_health_text.get_width() - 10, 10))
169
170 # Постоянно проверяем события игры и если присутствует событие Выход - останавливаем игру.
171 for event in pygame.event.get():
172 if event.type == pygame.QUIT:
173 pygame.quit()
174
175 # Если случилось пользовательское событие RED_HIT отнимаем жизни у Красного
176 if event.type == RED_HIT:
177 red_health -= 1
178
179 # Если случилось пользовательское событие YELLOW_HIT отнимаем жизни у Желтого
180 if event.type == YELLOW_HIT:
181 yellow_health -= 1
182
183 # Если произошло событие нажатия клавиши
184 if event.type == pygame.KEYDOWN:
185 # И нажали клавишу Пробел, а так же если длина листа выпущенных пуль красного меньше минимального
186 if event.key == pygame.K_SPACE and len(red_bullets) < MAX_BULLETS:
187 # Создаем объект прямоугольника для Пули
188 bullet = pygame.Rect(
189 red.x + red.width, red.y + red.height//2 - 2, 10, 5)
190 # Добавляем выпущенную пулю красному
191 red_bullets.append(bullet)
192
193 # Если нажали клавишу Enter, создаем выпущенную пулю желтому игроку
194 if event.key == pygame.K_RETURN and len(yellow_bullets) < MAX_BULLETS:
195 # Создаем объект прямоугольника для Пули
196 bullet = pygame.Rect(
197 yellow.x, yellow.y + yellow.height//2 - 2, 10, 5)
198 # Добавляем выпущенную пулю желтому
199 yellow_bullets.append(bullet)
200
201 # Узнаем нажатие клавишей
202 keys_pressed = pygame.key.get_pressed()
203 # Выполняем установку координат кораблей
204 red_handle_movement(keys_pressed, red)
205 yellow_handle_movement(keys_pressed, yellow)
206
207 # Проверяем столкновения пуль
208 handle_bullets(yellow_bullets, red_bullets, yellow, red)
209
210 # Перебираем пули красного и рисуем каждый кадр
211 for bullet in red_bullets:
212 pygame.draw.rect(screen, "red", bullet)
213 # Перебираем пули желтого и рисуем каждый кадр
214 for bullet in yellow_bullets:
215 pygame.draw.rect(screen, "yellow", bullet)
216
217 # Если здоровье упало до нуля, рисуем имя победителя.
218 winner_text = ""
219 if red_health <= 0:
220 winner_text = "Yellow Wins!"
221
222 if yellow_health <= 0:
223 winner_text = "Red Wins!"
224
225 if winner_text != "":
226 draw_winner(winner_text)
227 # Обнуляем пули
228 red_bullets.clear()
229 yellow_bullets.clear()
230 # Восстанавливаем здоровье
231 red_health = 10
232 yellow_health = 10
233
234 # Обновляем кадры игры
235 pygame.display.update()Звуки
Стрелять в тишине кажется странным, поэтому последнее, что мы сделаем это добавим звуки в игру.
Скачайте два звука grenade.mp3 и silencer.mp3 по этой ссылке и положите их в папку assets.
В самом верху нашего кода, там где импортировали модули, добавьте строчку (секция Подготавливаем необходимые модули Pygame):
1pygame.mixer.init()Данная строчка инициализирует модуль работы со звуками.
Теперь подключим два наших звука к игре.
1# Подключаем звуки к игре
2# Звук попадания
3BULLET_HIT_SOUND = pygame.mixer.Sound('./assets/grenade.mp3')
4# Звук выстрела
5BULLET_FIRE_SOUND = pygame.mixer.Sound('./assets/silencer.mp3')Теперь необходимо расставить нужные звуки в нужных местах. Добавьте строчку BULLET_HIT_SOUND.play() в местах где мы отнимаем здоровье (обрабатываем попадание)
1# Если случилось пользовательское событие RED_HIT отнимаем жизни у Красного
2if event.type == RED_HIT:
3 red_health -= 1
4 # Звук попадания
5 BULLET_HIT_SOUND.play()
6
7# Если случилось пользовательское событие YELLOW_HIT отнимаем жизни у Желтого
8if event.type == YELLOW_HIT:
9 yellow_health -= 1
10 # Звук попадания
11 BULLET_HIT_SOUND.play()Так же добавьте строчку BULLET_FIRE_SOUND.play() в местах где мы создаем пули при нажатии кнопок:
1# Если произошло событие нажатия клавиши
2if event.type == pygame.KEYDOWN:
3 # И нажали клавишу Пробел, а так же если длина листа выпущенных пуль красного меньше минимального
4 if event.key == pygame.K_SPACE and len(red_bullets) < MAX_BULLETS:
5 # Создаем объект прямоугольника для Пули
6 bullet = pygame.Rect(
7 red.x + red.width, red.y + red.height//2 - 2, 10, 5)
8 # Добавляем выпущенную пулю красному
9 red_bullets.append(bullet)
10 # Звук выстрела
11 BULLET_FIRE_SOUND.play()
12
13 # Если нажали клавишу Enter, создаем выпущенную пулю желтому игроку
14 if event.key == pygame.K_RETURN and len(yellow_bullets) < MAX_BULLETS:
15 # Создаем объект прямоугольника для Пули
16 bullet = pygame.Rect(
17 yellow.x, yellow.y + yellow.height//2 - 2, 10, 5)
18 # Добавляем выпущенную пулю желтому
19 yellow_bullets.append(bullet)
20 # Звук выстрела
21 BULLET_FIRE_SOUND.play()Так намного лучше! Игра заиграла новыми красками!
Итоговый результат
Работает:
- Кнопка закрыть/свернуть
- Отображается задний фон
- Разделитель экрана
- Отрисовка игроков
- Движение игроков
- Ограничитель кадров
- Здоровье игроков
- Выстрелы кораблей
- Звуки выстрелов и попаданий
1# Подключаем игровой движок Pygame
2import pygame
3# Подключаем модуль для работы с файловой системой
4import os
5
6# Подготавливаем необходимые модули Pygame
7pygame.init()
8pygame.mixer.init()
9
10# Подключаем звуки к игре
11# Звук попадания
12BULLET_HIT_SOUND = pygame.mixer.Sound('./assets/grenade.mp3')
13# Звук выстрела
14BULLET_FIRE_SOUND = pygame.mixer.Sound('./assets/silencer.mp3')
15
16### Константы ###
17# Константы размера окна
18WIDTH = 600
19HEIGHT = 300
20# Размеры корабля
21SPACESHIP_WIDTH = 55
22SPACESHIP_HEIGHT = 40
23# Скорость корабля
24VELOCITY = 5
25# Количество кадров в секунду
26FPS = 60
27# Шрифт здоровья
28HEALTH_FONT = pygame.font.SysFont('comicsans', 20)
29# Пользовательские события попаданий
30YELLOW_HIT = pygame.USEREVENT + 1
31RED_HIT = pygame.USEREVENT + 2
32
33# Ограничитель кадров
34clock = pygame.time.Clock()
35
36# Задаем размеры игрового окна
37screen = pygame.display.set_mode((WIDTH, HEIGHT))
38
39# Загружаем изображение в память
40SPACE_IMAGE = pygame.image.load(os.path.join('./assets', 'space.jpg'))
41
42# Создаем объект фона с разрешением окна
43SPACE_BG = pygame.transform.scale(SPACE_IMAGE, (WIDTH, HEIGHT))
44
45# Формируем объект границы
46BORDER = pygame.Rect(WIDTH//2 - 2, 0, 4, HEIGHT)
47
48# Загружаем изображение красного корабля
49RED_SPACESHIP_IMAGE = pygame.image.load(
50 os.path.join('./assets', 'spaceship_red.png'))
51# Разворачиваем изображение в нужном направлении
52RED_SPACESHIP = pygame.transform.rotate(pygame.transform.scale(
53 RED_SPACESHIP_IMAGE, (SPACESHIP_WIDTH, SPACESHIP_HEIGHT)), 90)
54
55# Загружаем изображение желтого корабля
56YELLOW_SPACESHIP_IMAGE = pygame.image.load(
57 os.path.join('./assets', 'spaceship_yellow.png'))
58# Разворачиваем изображение в нужном направлении
59YELLOW_SPACESHIP = pygame.transform.rotate(pygame.transform.scale(
60 YELLOW_SPACESHIP_IMAGE, (SPACESHIP_WIDTH, SPACESHIP_HEIGHT)), 270)
61
62# Создаем два объекта/прямоугольника
63red = pygame.Rect(100, 150, SPACESHIP_WIDTH, SPACESHIP_HEIGHT)
64yellow = pygame.Rect(500, 150, SPACESHIP_WIDTH, SPACESHIP_HEIGHT)
65
66# Здоровье игроков
67red_health = 10
68yellow_health = 10
69
70# Хранение выпущенных пуль
71red_bullets = []
72yellow_bullets = []
73# Макс. выпущенных пуль
74MAX_BULLETS = 3
75# Скорость пули
76BULLET_VEL = 7
77
78# Функция движения красного корабля
79def red_handle_movement(keys_pressed, red):
80 # Движение ВЛЕВО
81 if keys_pressed[pygame.K_a] and red.x - VELOCITY > 0:
82 red.x -= VELOCITY
83 # Движение ВПРАВО (запрещаем пересекать границу игроков)
84 if keys_pressed[pygame.K_d] and red.x + VELOCITY + red.width < BORDER.x:
85 red.x += VELOCITY
86 # Движение ВВЕРХ (запрещаем подниматься выше 0 по координате y)
87 if keys_pressed[pygame.K_w] and red.y - VELOCITY > 0:
88 red.y -= VELOCITY
89 # Движение ВНИЗ (запрещаем опускаться ниже чем высота экрана за вычетом высоты корабля и дополнительных 15 для отступа)
90 if keys_pressed[pygame.K_s] and red.y + VELOCITY + red.height < HEIGHT - 15:
91 red.y += VELOCITY
92
93# Функция движения желтого корабля
94def yellow_handle_movement(keys_pressed, yellow):
95 # Движение ВЛЕВО (запрещаем пересекать границу игроков)
96 if keys_pressed[pygame.K_LEFT] and yellow.x - VELOCITY > BORDER.x + BORDER.width:
97 yellow.x -= VELOCITY
98 # Движение ВПРАВО
99 if keys_pressed[pygame.K_RIGHT] and yellow.x + VELOCITY + yellow.width < WIDTH:
100 yellow.x += VELOCITY
101 # Движение ВВЕРХ
102 if keys_pressed[pygame.K_UP] and yellow.y - VELOCITY > 0:
103 yellow.y -= VELOCITY
104 # Движение ВНИЗ
105 if keys_pressed[pygame.K_DOWN] and yellow.y + VELOCITY + yellow.height < HEIGHT - 15:
106 yellow.y += VELOCITY
107
108# Обработка выпущенных пуль
109def handle_bullets(yellow_bullets, red_bullets, yellow, red):
110 # Перебираем все пули красного
111 for bullet in red_bullets:
112 # Двигаем пулю вправо
113 bullet.x += BULLET_VEL
114 # Если пуля задевает желтого игрока
115 if yellow.colliderect(bullet):
116 # Вызываем пользовательское событие попадание в Желтого
117 pygame.event.post(pygame.event.Event(YELLOW_HIT))
118 # Удаляем текущую пулю
119 red_bullets.remove(bullet)
120 # Удаляем пулю если она вышла за экран
121 elif bullet.x > WIDTH:
122 red_bullets.remove(bullet)
123
124 # Перебираем все пули желтого
125 for bullet in yellow_bullets:
126 # Двигаем пулю влево
127 bullet.x -= BULLET_VEL
128 # Если пуля задевает красного игрока
129 if red.colliderect(bullet):
130 # Вызываем пользовательское событие попадание в Красного
131 pygame.event.post(pygame.event.Event(RED_HIT))
132 # Удаляем текущую пулю
133 yellow_bullets.remove(bullet)
134 # Удаляем пулю если она вышла за экран
135 elif bullet.x < 0:
136 yellow_bullets.remove(bullet)
137
138# Функция рисует экран победителя
139def draw_winner(text):
140 # Создаем шрифт для победителя
141 WINNER_FONT = pygame.font.SysFont('comicsans', 60)
142 # Создаем надпись
143 draw_text = WINNER_FONT.render(text, 1, 'white')
144 # Устанавливаем надпись в центре игрового поля
145 screen.blit(draw_text, (WIDTH/2 - draw_text.get_width() /
146 2, HEIGHT/2 - draw_text.get_height()/2))
147
148 # Обновляем кадр игры
149 pygame.display.update()
150 # Задержка после победы
151 pygame.time.delay(2000)
152
153# Запускаем бесконечный цикл программы
154# Это делается чтобы программа не завершалась и постоянно рисовала новые кадры игры
155while True:
156 # Ограничиваем количество кадров игры
157 clock.tick(FPS)
158
159 # Рисуем изображение на заднем фоне
160 screen.blit(SPACE_BG, (0, 0))
161
162 # Рисуем прямоугольник
163 pygame.draw.rect(screen, "white", BORDER)
164
165 # Рисуем корабли
166 screen.blit(YELLOW_SPACESHIP, (yellow.x, yellow.y))
167 screen.blit(RED_SPACESHIP, (red.x, red.y))
168
169 # Отображаем здоровье на экране
170 red_health_text = HEALTH_FONT.render(
171 "Health: " + str(red_health), 1, "white")
172 yellow_health_text = HEALTH_FONT.render(
173 "Health: " + str(yellow_health), 1, "white")
174 screen.blit(red_health_text, (10, 10))
175 screen.blit(yellow_health_text, (WIDTH - red_health_text.get_width() - 10, 10))
176
177 # Постоянно проверяем события игры и если присутствует событие Выход - останавливаем игру.
178 for event in pygame.event.get():
179 if event.type == pygame.QUIT:
180 pygame.quit()
181
182 # Если случилось пользовательское событие RED_HIT отнимаем жизни у Красного
183 if event.type == RED_HIT:
184 red_health -= 1
185 # Звук попадания
186 BULLET_HIT_SOUND.play()
187
188 # Если случилось пользовательское событие YELLOW_HIT отнимаем жизни у Желтого
189 if event.type == YELLOW_HIT:
190 yellow_health -= 1
191 # Звук попадания
192 BULLET_HIT_SOUND.play()
193
194 # Если произошло событие нажатия клавиши
195 if event.type == pygame.KEYDOWN:
196 # И нажали клавишу Пробел, а так же если длина листа выпущенных пуль красного меньше минимального
197 if event.key == pygame.K_SPACE and len(red_bullets) < MAX_BULLETS:
198 # Создаем объект прямоугольника для Пули
199 bullet = pygame.Rect(
200 red.x + red.width, red.y + red.height//2 - 2, 10, 5)
201 # Добавляем выпущенную пулю красному
202 red_bullets.append(bullet)
203 # Звук выстрела
204 BULLET_FIRE_SOUND.play()
205
206 # Если нажали клавишу Enter, создаем выпущенную пулю желтому игроку
207 if event.key == pygame.K_RETURN and len(yellow_bullets) < MAX_BULLETS:
208 # Создаем объект прямоугольника для Пули
209 bullet = pygame.Rect(
210 yellow.x, yellow.y + yellow.height//2 - 2, 10, 5)
211 # Добавляем выпущенную пулю желтому
212 yellow_bullets.append(bullet)
213 # Звук выстрела
214 BULLET_FIRE_SOUND.play()
215
216 # Узнаем нажатие клавишей
217 keys_pressed = pygame.key.get_pressed()
218 # Выполняем установку координат кораблей
219 red_handle_movement(keys_pressed, red)
220 yellow_handle_movement(keys_pressed, yellow)
221
222 # Проверяем столкновения пуль
223 handle_bullets(yellow_bullets, red_bullets, yellow, red)
224
225 # Перебираем пули красного и рисуем каждый кадр
226 for bullet in red_bullets:
227 pygame.draw.rect(screen, "red", bullet)
228 # Перебираем пули желтого и рисуем каждый кадр
229 for bullet in yellow_bullets:
230 pygame.draw.rect(screen, "yellow", bullet)
231
232 # Если здоровье упало до нуля, рисуем имя победителя.
233 winner_text = ""
234 if red_health <= 0:
235 winner_text = "Yellow Wins!"
236
237 if yellow_health <= 0:
238 winner_text = "Red Wins!"
239
240 if winner_text != "":
241 draw_winner(winner_text)
242 # Обнуляем пули
243 red_bullets.clear()
244 yellow_bullets.clear()
245 # Восстанавливаем здоровье
246 red_health = 10
247 yellow_health = 10
248
249 # Обновляем кадры игры
250 pygame.display.update()Поздравляю! Наша игра готова! Теперь можно подумать как ее улучшить. Например, добавить новые звуки, создать возможность собирать powerup-ы и т.д.
Заключение
Библиотека PyGame не предоставит вам инструмента для создания AAA-игры, но для обучения вполне подходящий инструмент. С помощью PyGame легко рисовать фигуры, добавлять на них текстуры, работать с нажатиями клавиш и звуком. Все что нужно для Indie игры. Вот, кстати несколько примеров таких игр.
Если же хочется большего, думаю, стоит присмотреться к игровому движку Godot. Язык программирования Godot Script очень похож на Python, так что разобраться будет не сложно, а проекты там на порядок выше. Вот пример.
Надеюсь данная статься была вам интересна и вы нашли в ней что-то полезное! Удачи!
Создаем динамические модули используя Webpack Module Federation

Изучая технологию Webpack Module Federation я задался следующим вопросом: Как подключить удаленный модуль (remote module), не во время сборки, а во время работы нашего JS приложения?
Я воспринимаю remote модуль как коробку, которую можно перенести в любое место и распаковать ее содержимое, и в нашем случае это компоненты React. Моей же задачей стало понять, как запаковать компонент в коробку, а затем положить эту коробку в более крупную и перенести все вместе за один раз?
Автоматическое переключение версий NodeJS (nvm use)
У меня на рабочем PC множество проектов, как рабочих, так и личных. Во многих из них используется разная версия NodeJS. И как же бесит эта надпись: The engine "node" is incompatible with this module. Если в директории проекта есть файл .nvmrc то можно переключить версию NodeJS при помощи NVM (Node Version Manager) командой nvm use. Но делать это каждый раз вручную - дело неблагодарное. Посему, предлагаю автоматизировать.

MacOS и Linux
Собственное решение
Если вы работаете за MacOS, добавьте скрипт ниже в самый конец файла .zshrc в домашней директории (~/.zshrc). Если вы используете Linux, или вы используете подсистему Linux в Windows (WSL) то данный скрипт нужно добавить в файл .bashrc по тому же пути.
1########################
2# Автоматическое nvm use
3########################
4
5# Определяет переменную окружения NVM_DIR, которая указывает на директорию, где установлен nvm.
6export NVM_DIR="$HOME/.nvm"
7# Проверяет, существует ли скрипт nvm.sh в указанной директории и не является ли он пустым (-s проверяет, что файл существует и не пустой
8# Если файл существует, он выполняется (\. "$NVM_DIR/nvm.sh"), что загружает nvm в вашу оболочку, позволяя использовать команды nvm в текущей сессии.
9[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh"
10
11# Автоматическое переключение при открытии терминала в нужной директории
12if [ -f .nvmrc ]; then
13 nvm use
14fi
15
16# При переходе в директорию (использовании команды cd) проверяется наличие .nvmrc и вызов nvm use
17cd() {
18 builtin cd "$@" || return
19 if [ -f .nvmrc ]; then
20 nvm use
21 fi
22}
23
24########################
25########################
26########################Все! Теперь при открытии нового терминала или при использовании комнды cd для перехода в другую директорию, скрипт проверит наличие файла .nvmrc и при его наличии запустит команду nvm use.
Решение от NVM
Сам NVM предлагает и свое решение.
1# place this after nvm initialization!
2autoload -U add-zsh-hook
3
4load-nvmrc() {
5 local nvmrc_path
6 nvmrc_path="$(nvm_find_nvmrc)"
7
8 if [ -n "$nvmrc_path" ]; then
9 local nvmrc_node_version
10 nvmrc_node_version=$(nvm version "$(cat "${nvmrc_path}")")
11
12 if [ "$nvmrc_node_version" = "N/A" ]; then
13 nvm install
14 elif [ "$nvmrc_node_version" != "$(nvm version)" ]; then
15 nvm use
16 fi
17 elif [ -n "$(PWD=$OLDPWD nvm_find_nvmrc)" ] && [ "$(nvm version)" != "$(nvm version default)" ]; then
18 echo "Reverting to nvm default version"
19 nvm use default
20 fi
21}
22
23add-zsh-hook chpwd load-nvmrc
24load-nvmrcДавайте разберем их скрипт. Cкрипт предназначен для автоматического переключения версии Node.js с помощью `nvm` (Node Version Manager) при изменении директории в терминале, если в этой директории присутствует файл `.nvmrc`, который указывает нужную версию Node.js.
Давайте разберём каждую часть скрипта:
1. autoload -U add-zsh-hook
Эта команда загружает функцию add-zsh-hook, если она ещё не загружена. add-zsh-hook используется для добавления хуков (hooks) в zsh.
2. Функция load-nvmrc
- local nvmrc_path: Объявляет локальную переменную nvmrc_path, которая будет хранить путь к файлу .nvmrc.
- nvmrc_path="$(nvm_find_nvmrc)": Функция nvm_find_nvmrc ищет файл .nvmrc в текущей директории или в родительских директориях. Если файл найден, его путь сохраняется в nvmrc_path.
- Проверка if [ -n "$nvmrc_path" ]; then: Если путь к файлу .nvmrc найден (т.е. `nvmrc_path` не пустой), то выполняется следующий блок кода:
- local nvmrc_node_version: Объявляет локальную переменную для хранения версии Node.js, указанной в файле .nvmrc.
- nvmrc_node_version=$(nvm version "$(cat "${nvmrc_path}")"): Получает версию Node.js из файла .nvmrc и сохраняет её в nvmrc_node_version.
- if [ "$nvmrc_node_version" = "N/A" ]; then: Если версия Node.js не найдена (nvm возвращает "N/A"), то устанавливается версия Node.js из файла .nvmrc с помощью nvm install.
- elif [ "$nvmrc_node_version" != "$(nvm version)" ]; then: Если текущая версия Node.js отличается от версии в .nvmrc, то выполняется nvm use для переключения на нужную версию.
- elif [ -n "$(PWD=$OLDPWD nvm_find_nvmrc)" ] && [ "$(nvm version)" != "$(nvm version default)" ]; then: Если файл .nvmrc отсутствует, но в предыдущей директории он был, и текущая версия Node.js не совпадает с версией по умолчанию, то:
- Выводится сообщение "Reverting to nvm default version" и выполняется nvm use default, чтобы переключиться на версию Node.js по умолчанию.
3. add-zsh-hook chpwd load-nvmrc:
- Добавляет хук на событие chpwd (изменение директории) и связывает его с функцией load-nvmrc. Это означает, что при каждом изменении директории будет вызываться функция load-nvmrc.
4. load-nvmrc:
- Выполняет функцию load-nvmrc сразу же после инициализации, чтобы применить нужную версию Node.js при первом запуске терминала.
Этот скрипт помогает автоматически управлять версиями Node.js при переходе между проектами с разными версиями, указанными в .nvmrc. Скрипт более продуманный, но и как видно, более сложный.
Windows
На Windows для управления версиями Node.js и работы с файлами .nvmrc есть несколько подходов, поскольку nvm (Node Version Manager) изначально не поддерживает Windows. Однако существует несколько альтернатив и способов адаптировать рабочий процесс
1) Использование nvm-windows (Node Version Manager for Windows):
nvm-windows — это альтернатива nvm специально для Windows. Она поддерживает переключение версий Node.js и чтение файла .nvmrc. Вот как это настроить:
• Установка nvm-windows:
1. Загрузите nvm-windows с официального репозитория GitHub.
2. Установите его, следуя инструкциям установщика.
• Использование файла .nvmrc:
1. Убедитесь, что в директории вашего проекта есть файл .nvmrc, содержащий нужную версию Node.js.
2. Откройте командную строку или PowerShell и перейдите в директорию вашего проекта.
3. Введите команду:
1nvm useЭто автоматически прочитает версию Node.js из файла .nvmrc и переключится на неё.
Автоматизация процесса:
Чтобы nvm use выполнялся автоматически при запуске терминала в нужной директории, можно создать сценарий в PowerShell профиле или командной строке, который будет вызываться при открытии сессии. Например, в PowerShell:
1if (Test-Path .nvmrc) {
2 $version = Get-Content .nvmrc
3 nvm use $version
4}Добавьте этот скрипт в ваш профиль PowerShell ($PROFILE), чтобы он выполнялся при каждом запуске PowerShell.
2) Использование Windows Subsystem for Linux (WSL):
Я все же настоятельно рекомендую использовать Linux-окружение на Windows и для этого вы можете использовать WSL (Windows Subsystem for Linux). В этом случае вы можете установить стандартный nvm в своем Linux-дистрибутиве и работать с ним так же, как и на любой другой Unix-подобной системе.
• Установка WSL:
1. Установите WSL, следуя официальным инструкциям от Microsoft.
2. Установите свой любимый Linux-дистрибутив (например, Ubuntu).
• Установка nvm:
1. Откройте терминал WSL.
2. Следуйте стандартным инструкциям по установке nvm:
1curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.1/install.sh | bash3. Используйте nvm и .nvmrc, как это описано ранее.
Заключение
Всего за пару минут мы автоматизировали переключение версий NodeJS. Надеюсь статья была полезной - если да - обязательно поделись ею! Удачи!
Переопределение контента, HTTP заголовков и API в Chrome DevTools
С удивлением обнаружил, что не многие разработчики и тестировщики знают о возможности DevTools переопределять содержимое ответов на запросы, которые делает браузер. Эта возможность может быть полезна как на этапе разработки, так и на этапе тестирования. Данный функционал называется local overrides или локальные переопределения. Давайте же посмотрим на этот функционал.

Обзор
С помощью локальных переопределений вы можете переопределить заголовки ответов HTTP, файлы js, стили css, изображения и любой другой веб контент, включая запросы XHR и fetch, для имитации удаленных ресурсов, даже если у вас нет к ним доступа. Это позволяет разрабатывать приложение, не дожидаясь, пока серверная часть реализует необходимый функционал. Локальные переопределения также позволяют сохранять изменения, внесенные в DevTools, при загрузке страниц.
Суть локального переопределения заключается в создании специальной папки на вашем локальном компьютере в которой будут храниться весь переопределенный контент.
Функционал подмены статических файлов и заголовков HTTP появился в chrome в апреле 2023 года, а сентябре появилась возможность редактировать содержимое запросов XHR и fetch.
Настоятельно рекомендую пройти практику вместе со мной, иначе информацию забудется. Так уж устроен наш мозг.
Подготовка
Создайте в любом, удобном месте на вашем локальном компьютере папку в которой браузер будет сохранять все переопределения в виде отдельных файлов.
Я назвал папку chrome-overrides и разместил ее на рабочем столе моего локального компьютера.
Теперь перейдите в ваш браузер Google Chrome и откройте DevTools. Затем перейдите на вкладку Sources, а затем на левой панели, чуть ниже, на вложенных вкладках откройте Overrides.
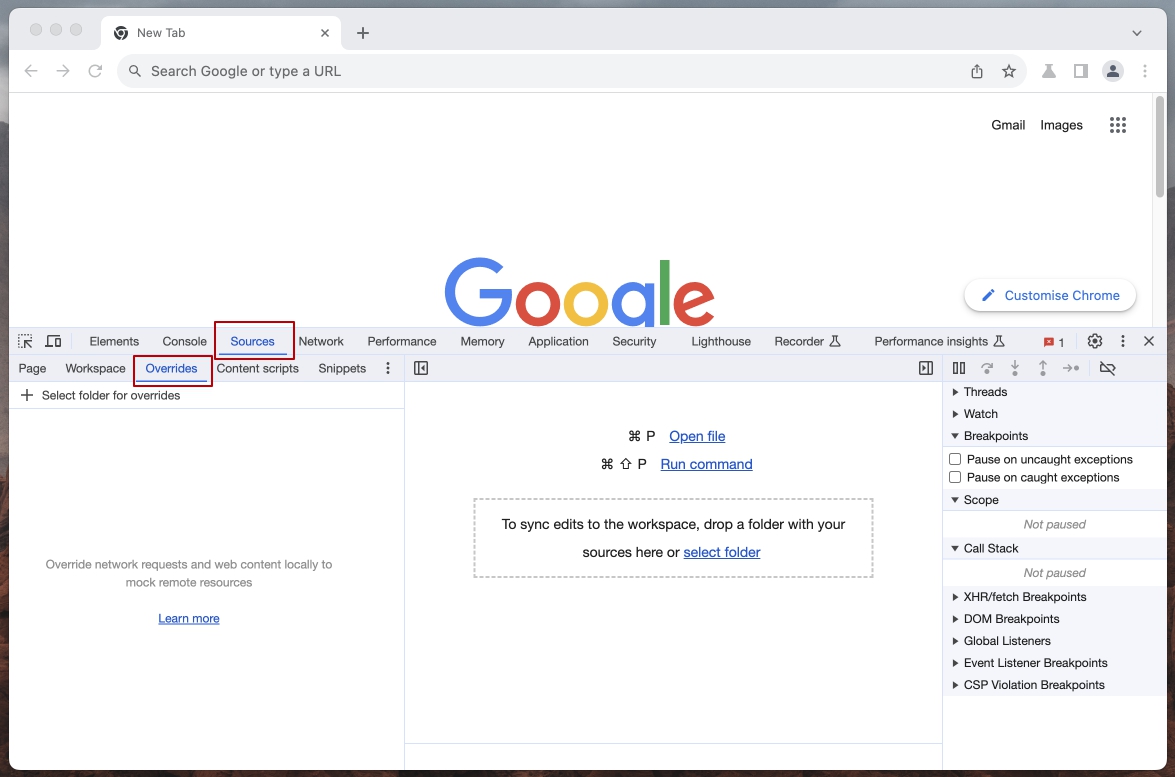
Чуть ниже вы увидите кнопку + с надписью Select folder for overrides. Кликните по ней. Появится всплывающее окно в котором нужно выбрать вашу локальную директорию. После подтверждения выбора во всплывающем окне, возможно, браузер попросит дать разрешение на запись данных в эту директорию. Разрешите.

После этого на панели Overrides вы должны увидеть подключенную директорию.
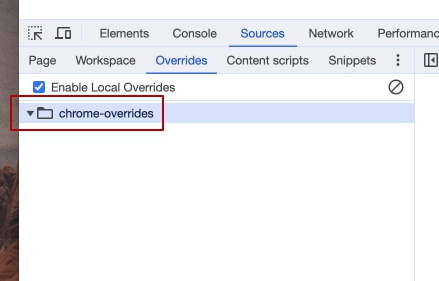
Переопределение веб-содержимого
В качестве испытуемого возьмём веб сайт https://www.wikipedia.org
В DevTools перейдите на вкладку Network, а затем загрузите Википедию. На вкладке Network вы увидите все запросы которые выполнил браузер.
Давайте переопределим входящий HTML. Кликните правой кнопкой мыши на первом запросе и выберете пункт Override Content.
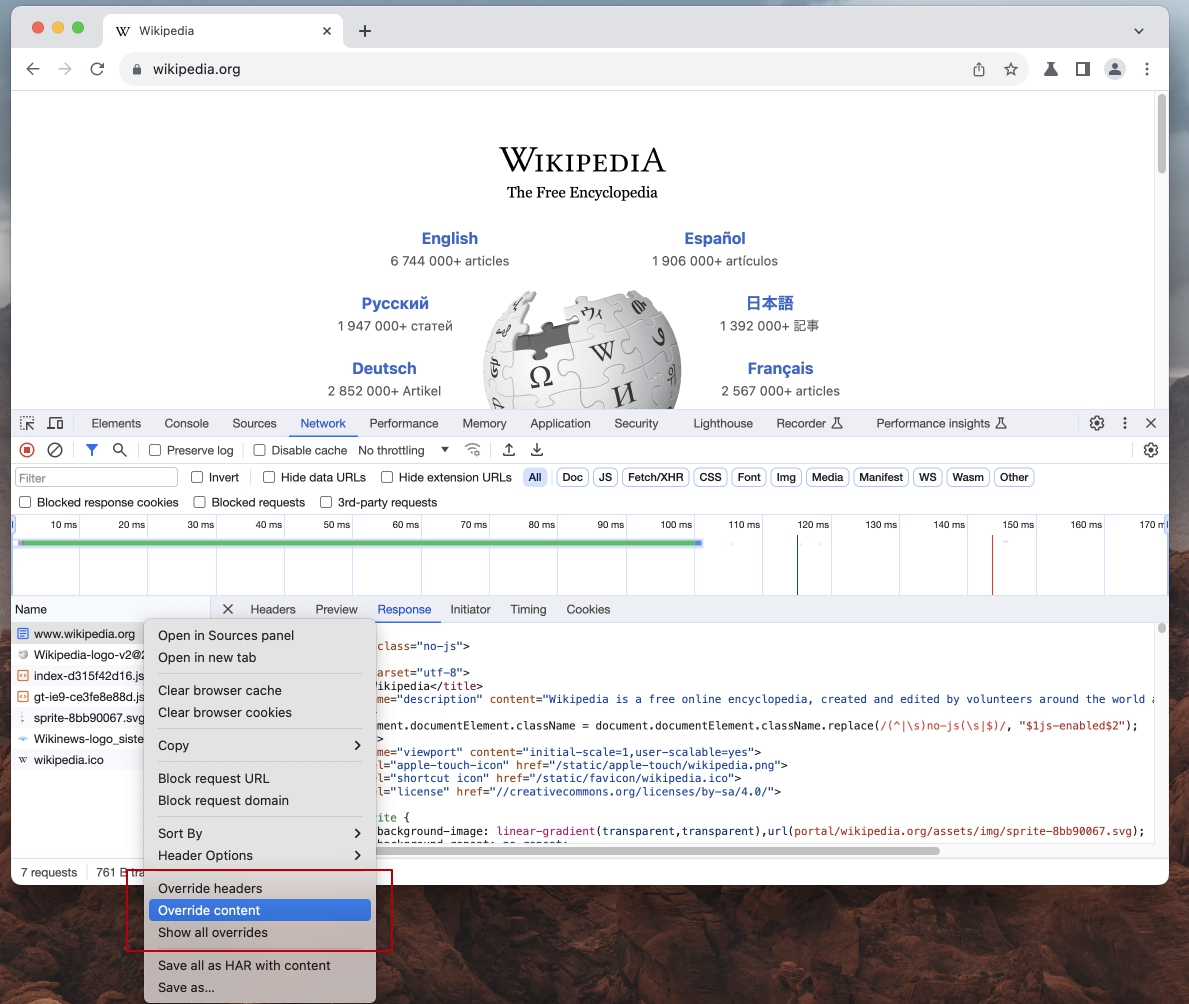
После этого вы снова попадете на вкладки Sources - Overrides, но на этот раз в вашей локальной директории будет создан файл html, который будет получать браузер если запрос совпадет с www.wikipedia.org. Правее, в панели редактирования, вы можете изменить файлы как вам угодно.
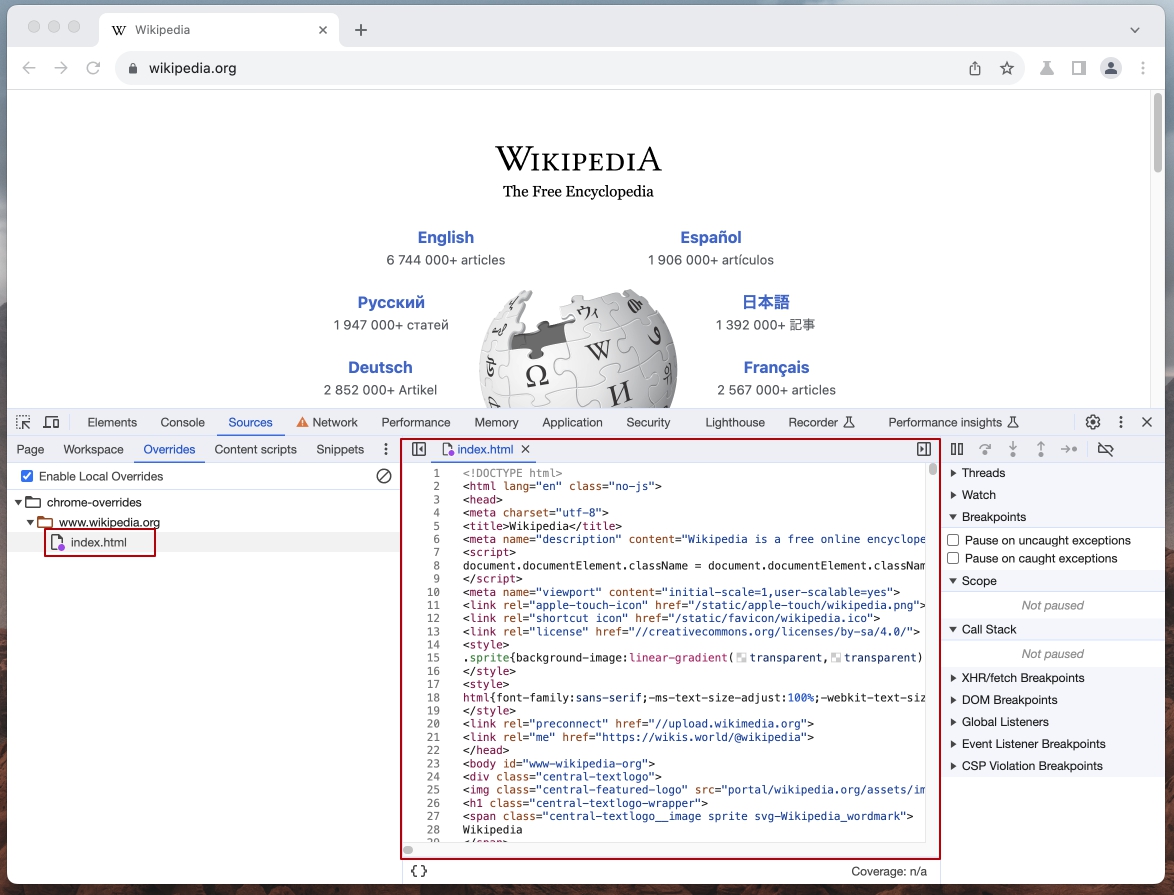
Найдите текст "The Free Encyclopedia" и замените его на "Local Overrided". Теперь сохраните изменения нажатием горячих клавиш Ctrl + S (или Сmd + S на Mac). После этого перейдите в DevTools на вкладку Network и перезагрузите страницу. Вы должны увидеть как браузер при совпадении запроса подменит контент HTML. Обратите внимание на детали. На владке Network появился символ Warning который уведомляет пользователя о том, что DevTools может переопределять запросы и нужно быть внимательным. В списке запросов, а так же на дополнительных вкладках появилась фиолетовая точка, которая говорит о том, что этот контент подменен. Таким образом можно легко обнаружить подмененный контент среди других запросов.
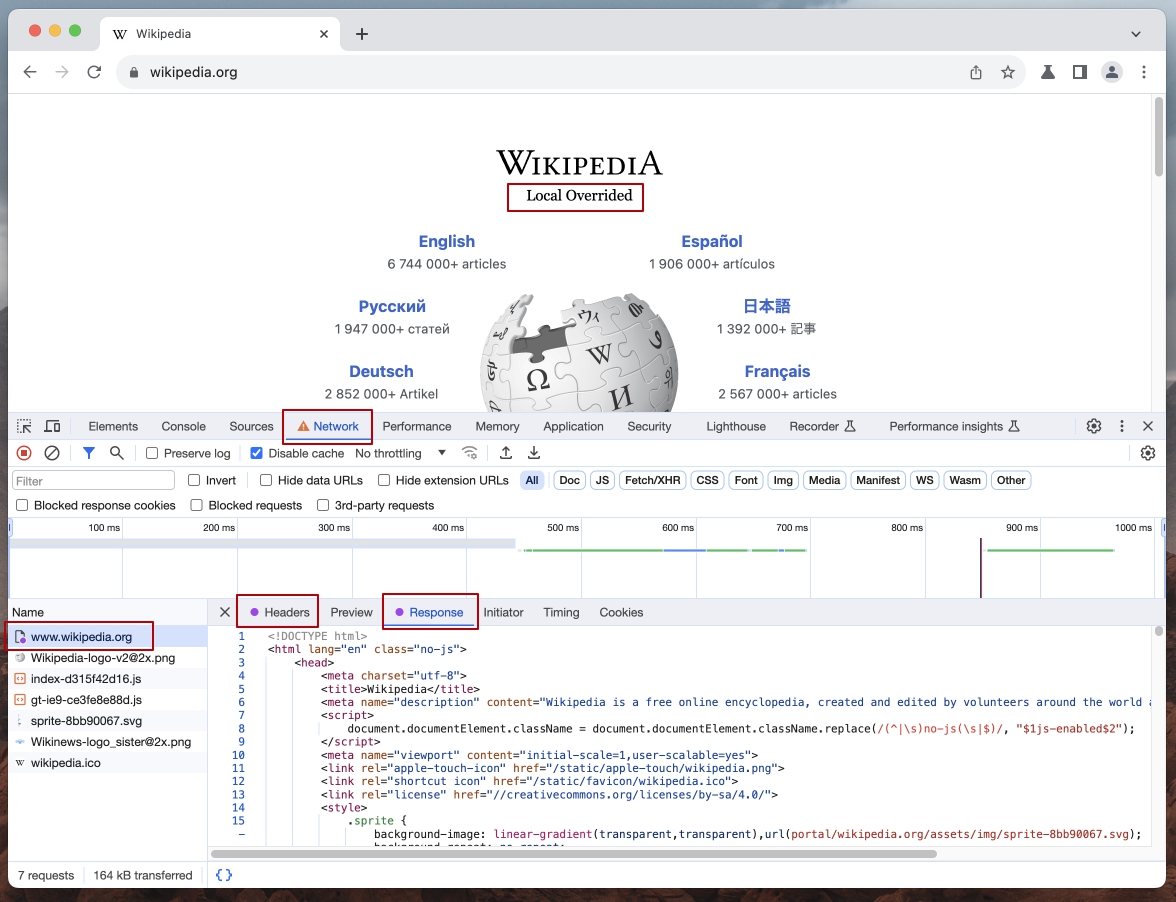
Вы так же можете добавить дополнительную колонку Has overrides в таблицу запросов.
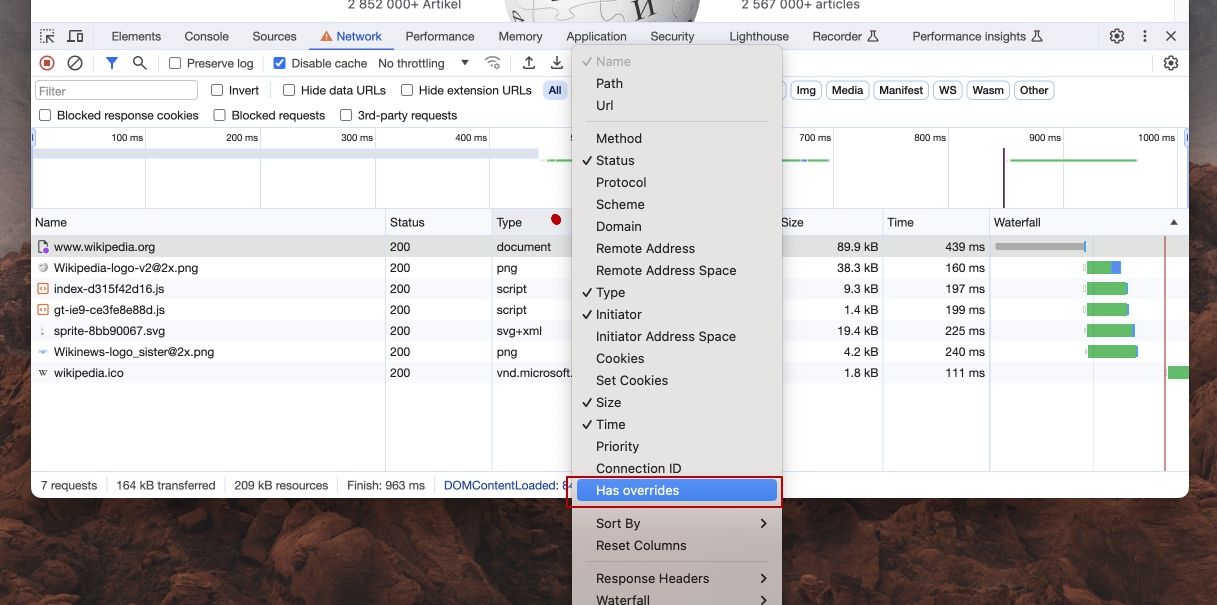
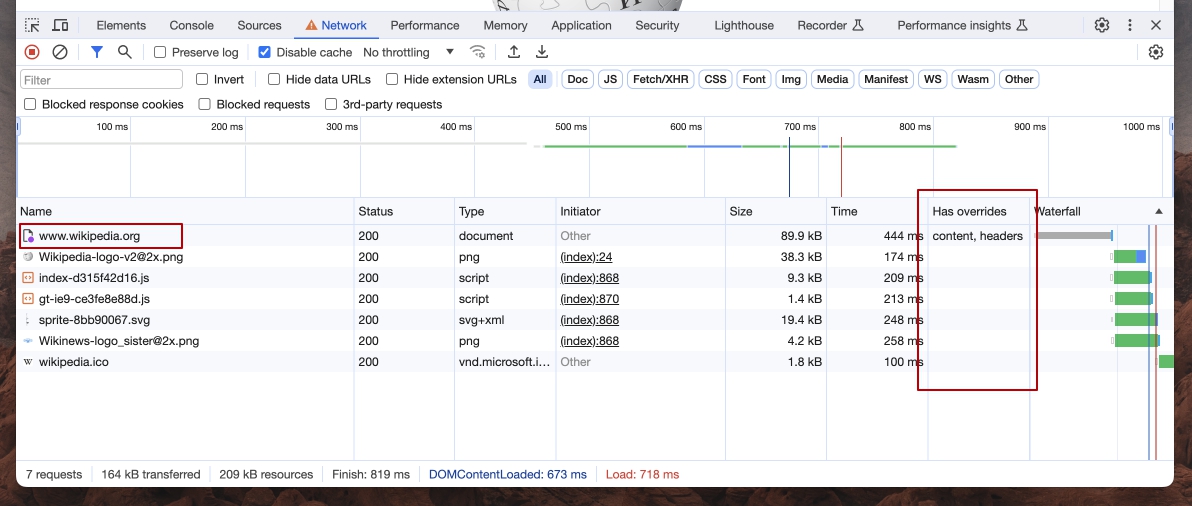
А так же вы можете настроить фильтр на показ только подмененных запросов.
Есть несколько фильтров:
has-overrides:content - показать запросы с подменённым контентом
has-overrides:headers - показать запросы с подменёнными заголовками
has-overrides:yes - все запросы с любым подменённым контентом
has-overrides:no - все запросы с неизмененным контентом
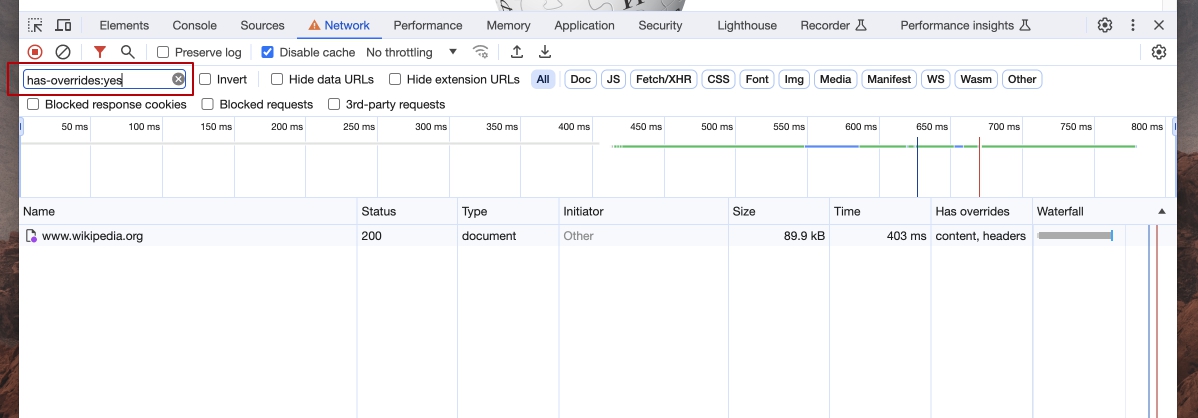
Для примера подменим так же изображение. В списке запросов выберете изображение логи википедии, и через выпадающее меню выберете Override content.
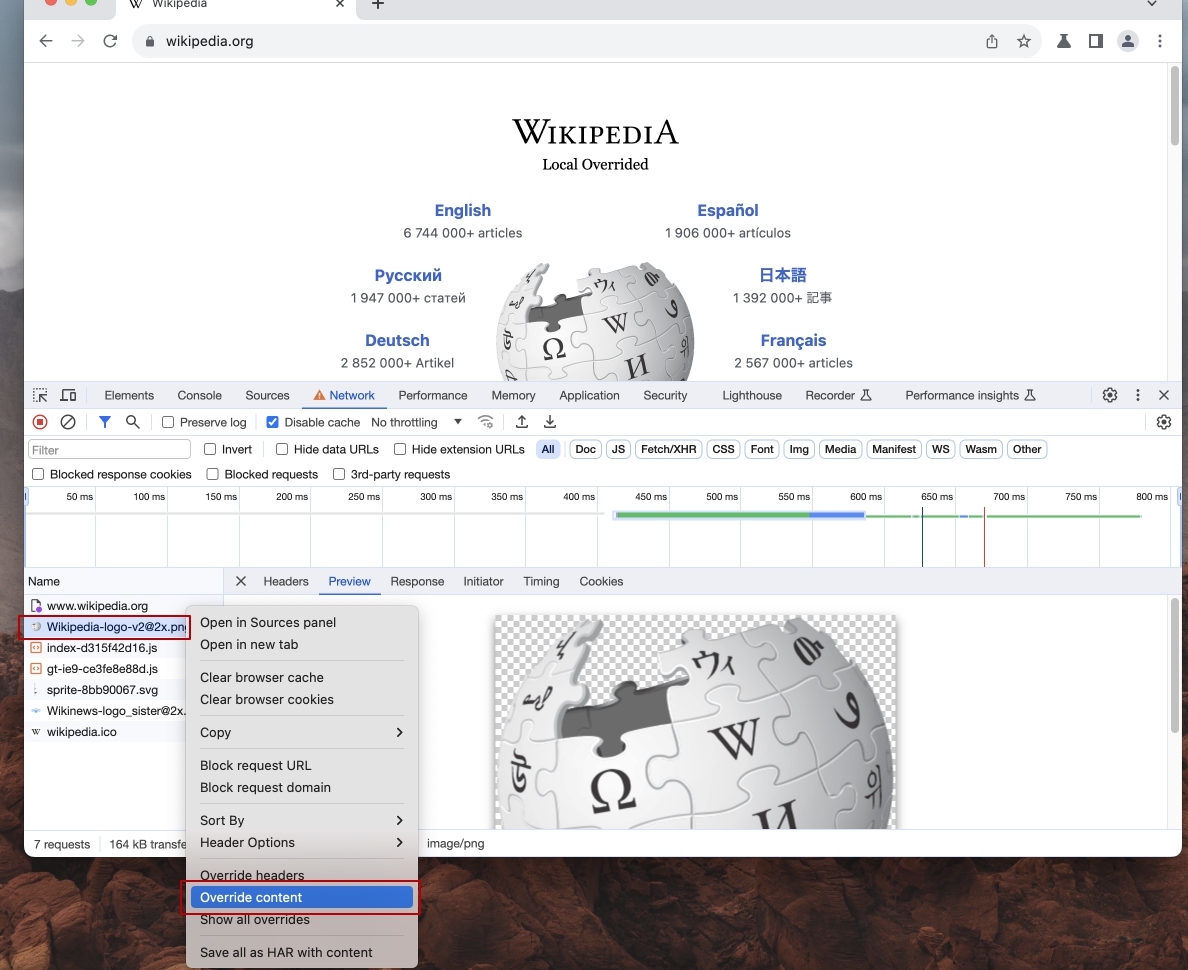
Обратите внимание на то, что в панели Overrides появилось изображение которое мы хотим подменить - изображение сохранилось на вашем компьютере.
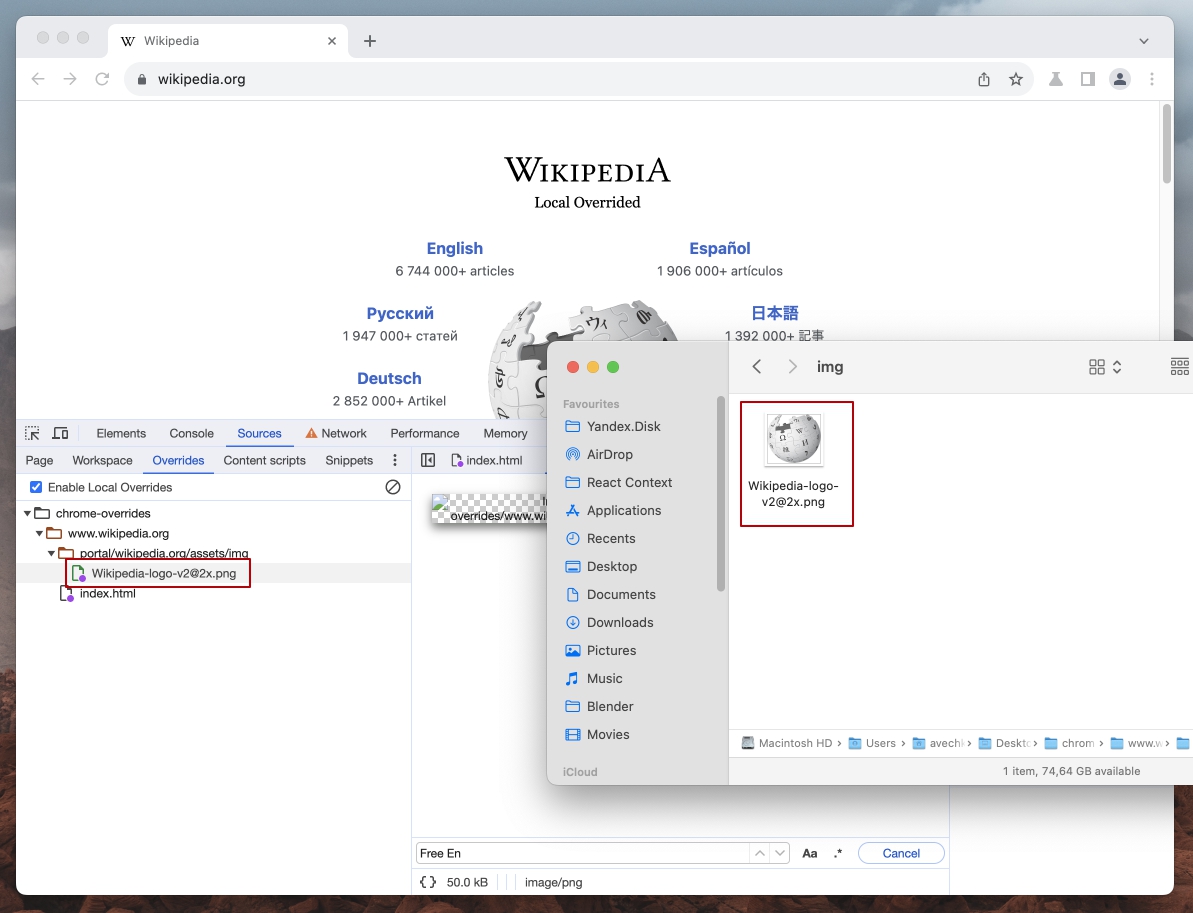
Подыщите подходящее изображение на замену, дайте имя подменяемого изображения и замените картинку в рабочей директории. Обратите внимание чтобы расширения совпадали. Теперь в DevTools откройте вкладку Network и перезагрузите страницу. Вы должны увидеть подмененное изображение.
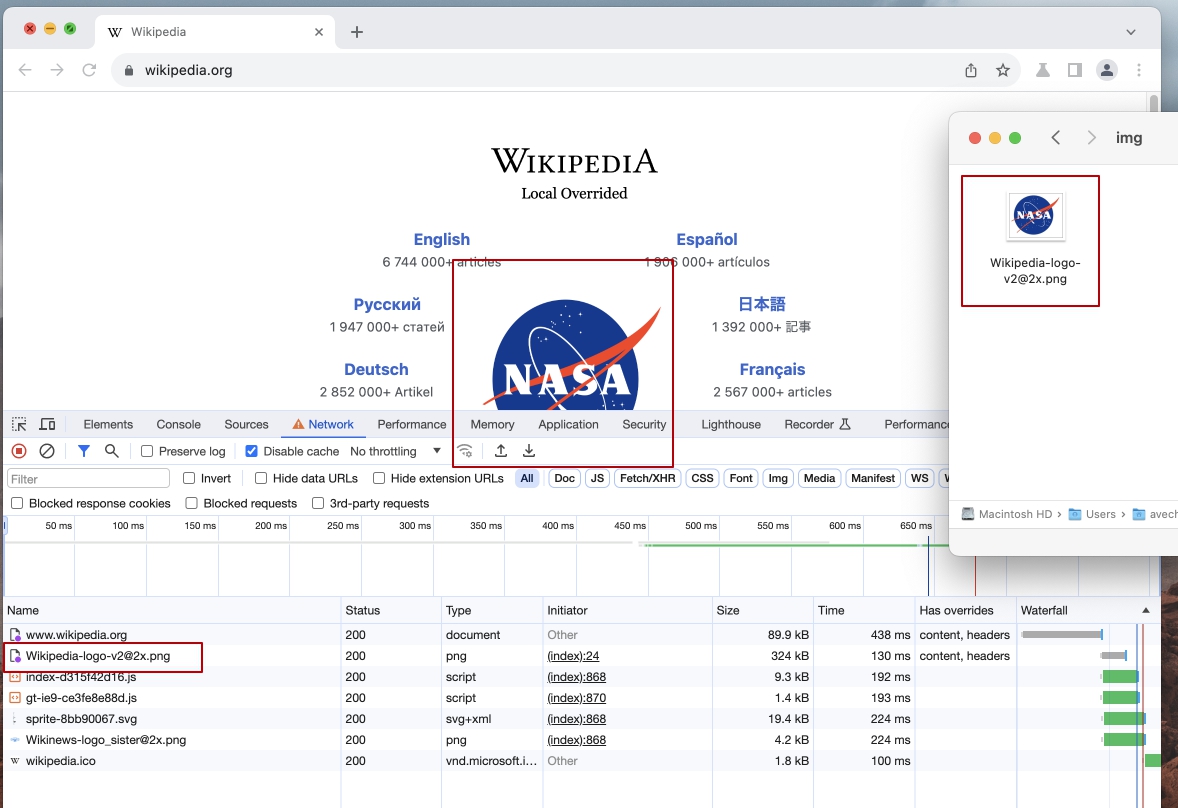
Таким же образом вы можете подменять почти любые статические файлы, например файлы стилей CSS, файлы скриптов JavaScript и так далее.
Переопределение заголовков HTTP
Local overriding так же позволяет подменить HTTP заголовки ответов.
Предположим, я как разработчик хочу подставить заголовок ответа, который в будущем будет возвращать backend, но на данный момент этот заголовок не реализован. Это не причина останавливать разработку.
Для того чтобы подменить HTTP заголовок, нам понадобится опция Override headers. Кликните правой кнопкой мыши по первому запросу веб страницы и выбирете нужную опцию.
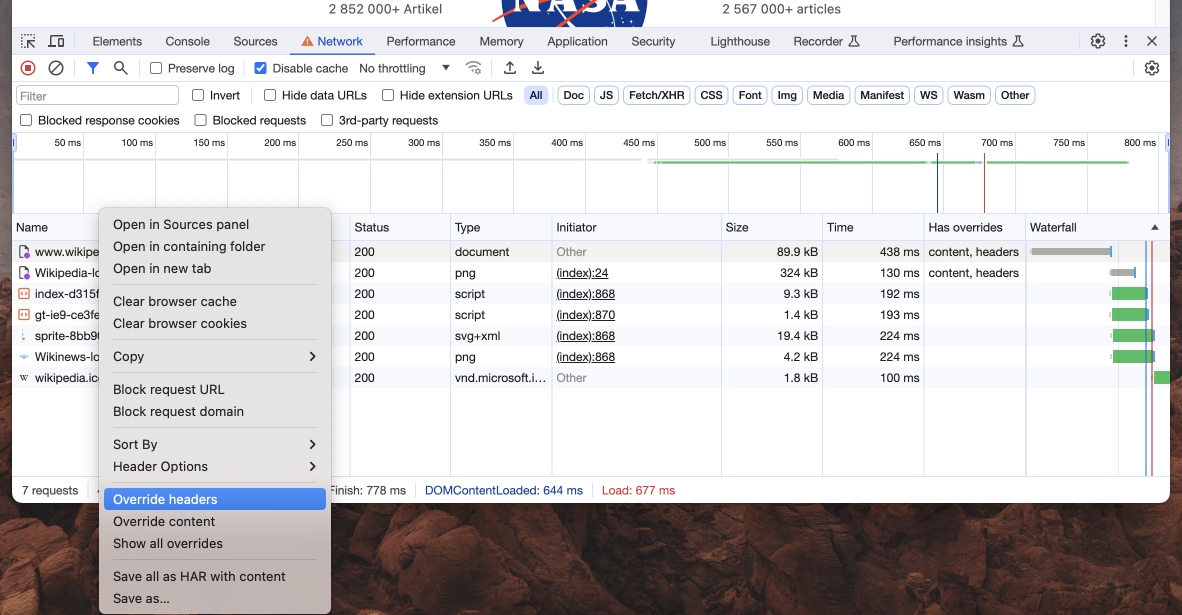
В данном случае вас перебросит на вкладку Network - Headers. Так как мы уже переопределяли целый файл html - заголовки так же были переопределены заранее (ведь нельзя же вернуть контент html без заголовков).
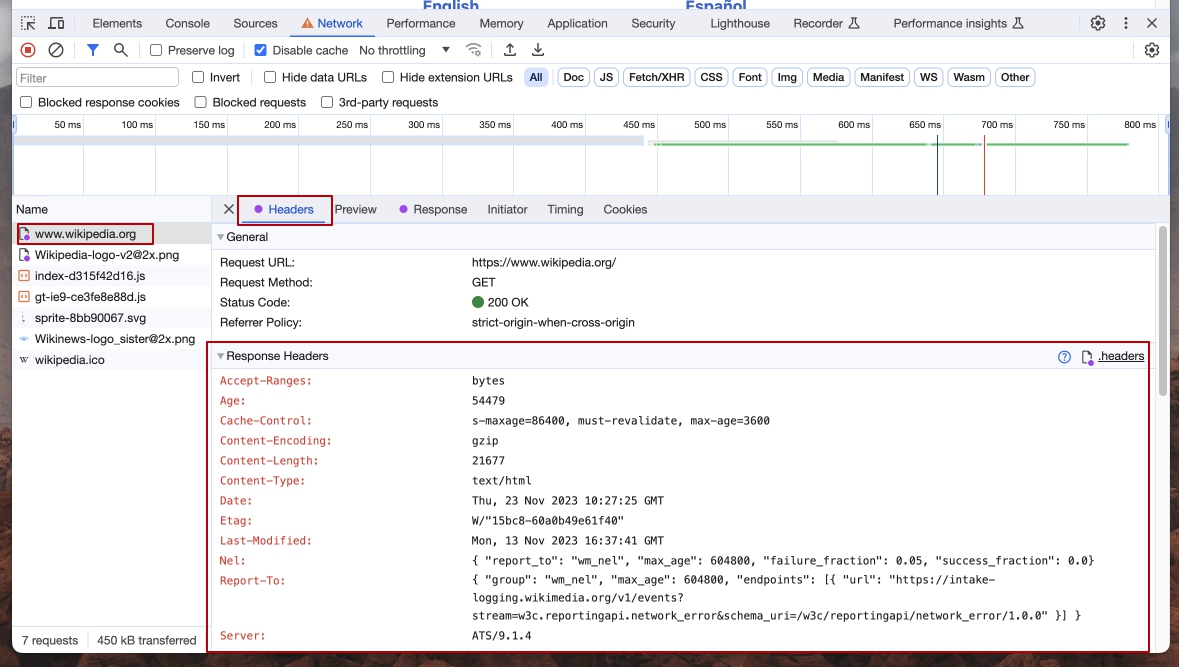
Но вы можете легко добавить собственный заголовок. Сделать это можно при помощи кнопки Add header, которая находится ниже списка переопределенных заголовков.
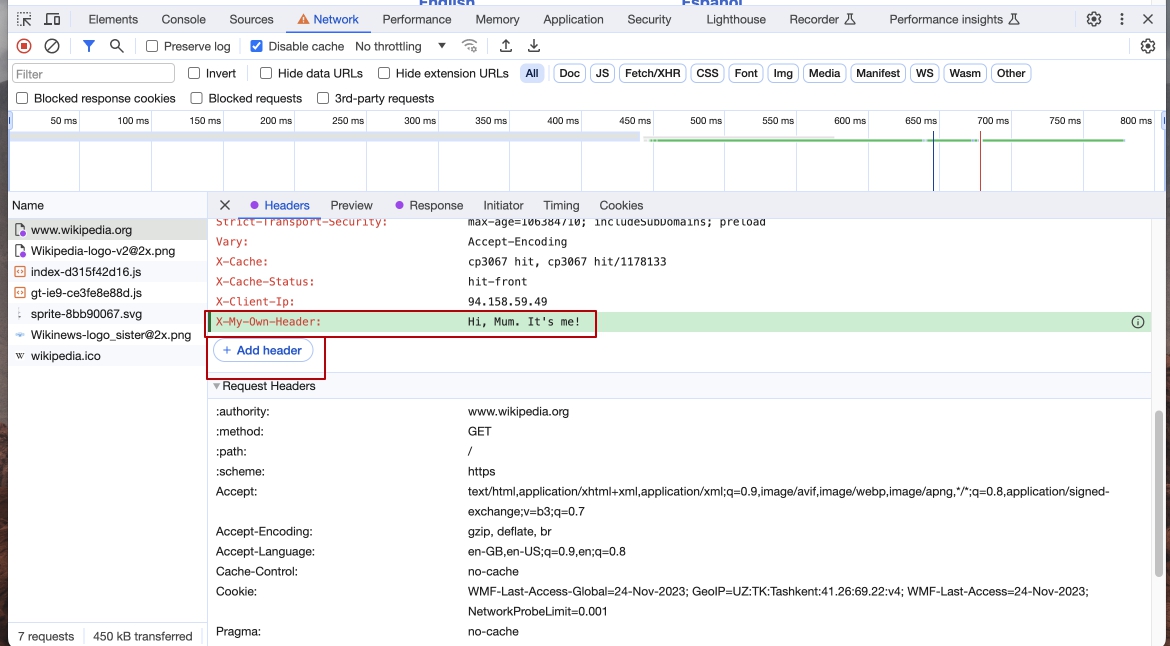
Теперь перезагрузите страницу и проверьте, что заголовок появился в переопределенном ответе. Все заголовки, которые были переопределены вручную хранятся в специальном файле .headers.
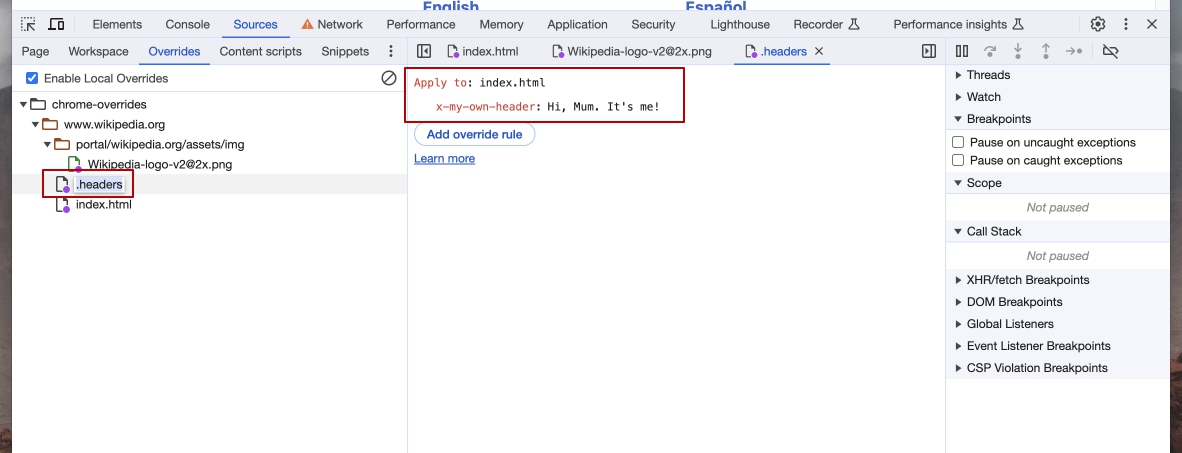
Таким образом вы легко можете переопределять заголовки http ответов под свои собственные нужды.
Переопределение XHR или fetch
Обычно, при разработке, если необходимо "мокать" (подменять) запросы, запускаются различные инструменты на стороне сервера. Теперь, если вам достаточно переопределить ответ для клиента, это можно сделать прямо в браузере без использования сторонних инструментов.
К сожалению на главной странице Википедии нет XHR запроса, но нам никто не мешает добавить в существующий файл javascript собственный код.
Выберите запрос файла javascript и в выпадающем меню выберете опцию Override content. После создания подменненного файла, в редакторе, добавьте следующий код и сохраните файл.
1(async function(){
2 const res = await fetch('https://baconipsum.com/api/?type=meat-and-filler');
3 console.log('Response: ', res);
4})()Возможно, при вставке, DevTools спросит, точно ли вы доверяете ли вы тексту скрипта. Данный скрипт выполняет XHR запрос на сайт https://baconipsum.com - это обычные API заглушки для тестирования.
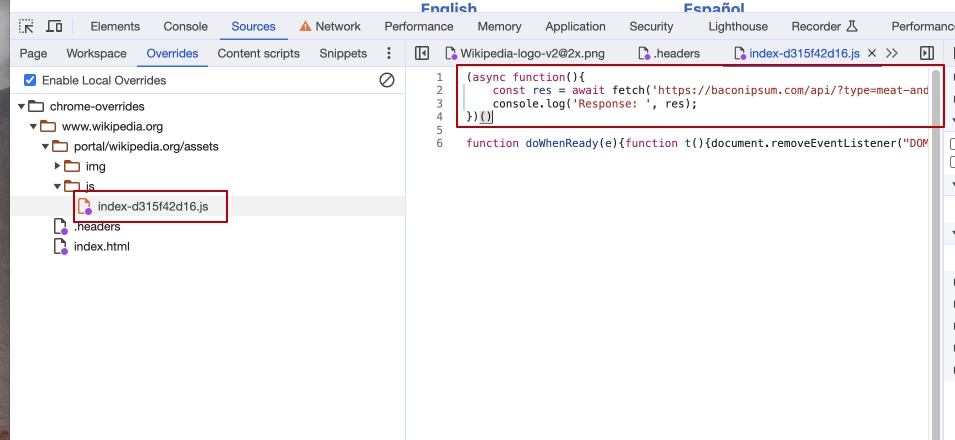
Перезагрузите страницу, проверьте, что в консоли вывелось ожидаемое сообщение, а в списке запросов появился fetch запрос.
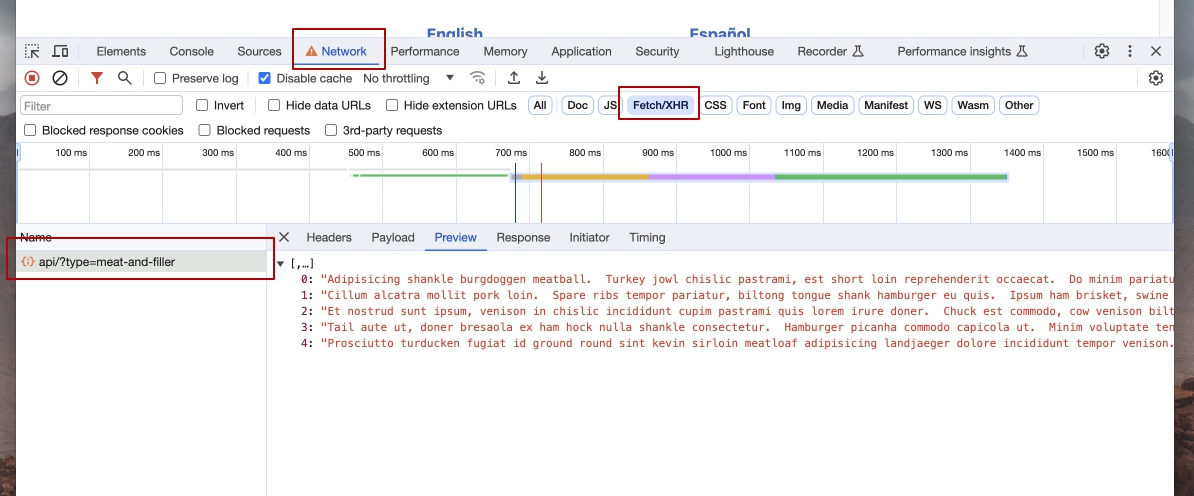
Теперь действуем так же, как с обычным контентом - опция Override content (или Override headers если нужно подменить только заголовки).
Переопределите данные ответа на fetch запрос. Обратите внимание, такой контент хранится на локальной файловой системе в директории api.
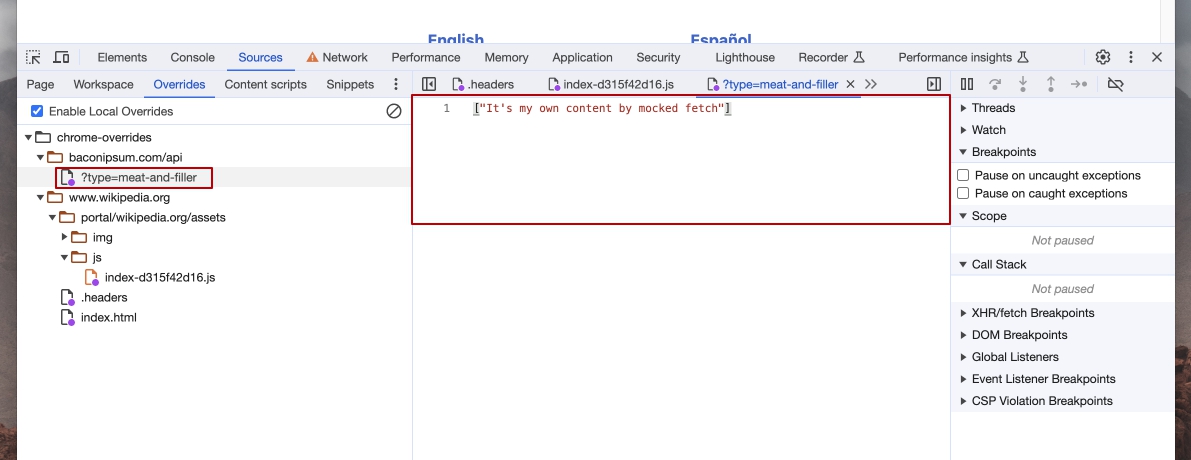
Проверьте, что fetch успешно переопределен.
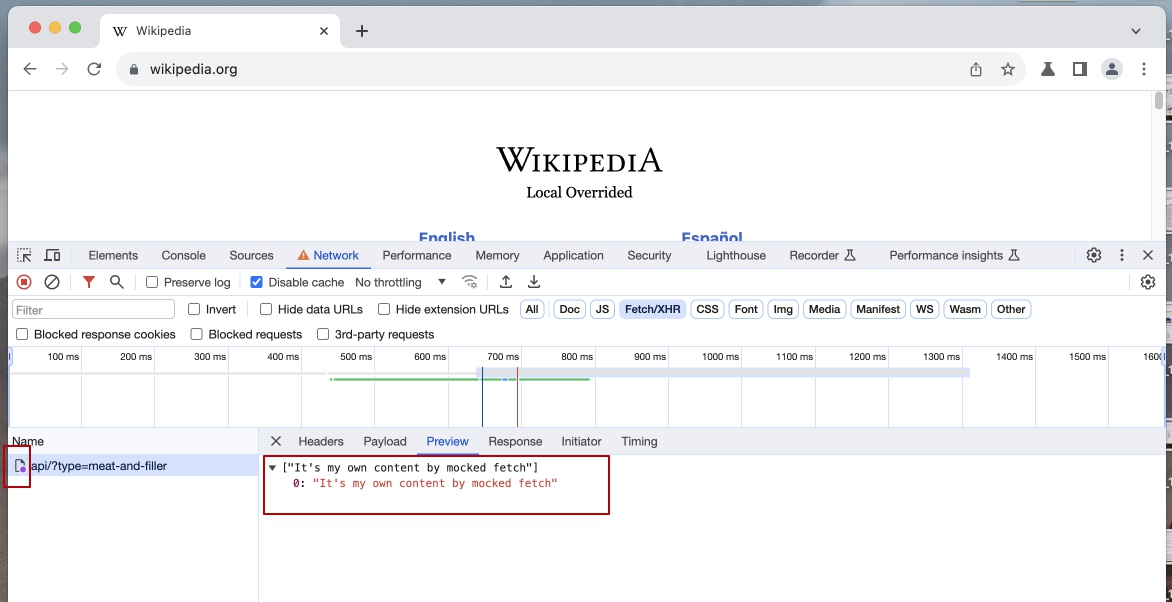
Отмена переопределения
Так как все файлы хранятся на вашем локальном компьютере, вы можете сколько угодно раз перезагружать веб страницы - переопределения сохранятся.
Если же вам понадобится временно отключить все переопределения, то это можно легко сделать. Перейдите на вкладку Sourses - Overrides и отключите опцию Enable Local Overrides. После перезагрузки страницы, вы увидите весь контент сайта без переопределений. Не беспокойтесь, все переопределения не удалятся и вы можете в любой момент снова включить данную опцию.
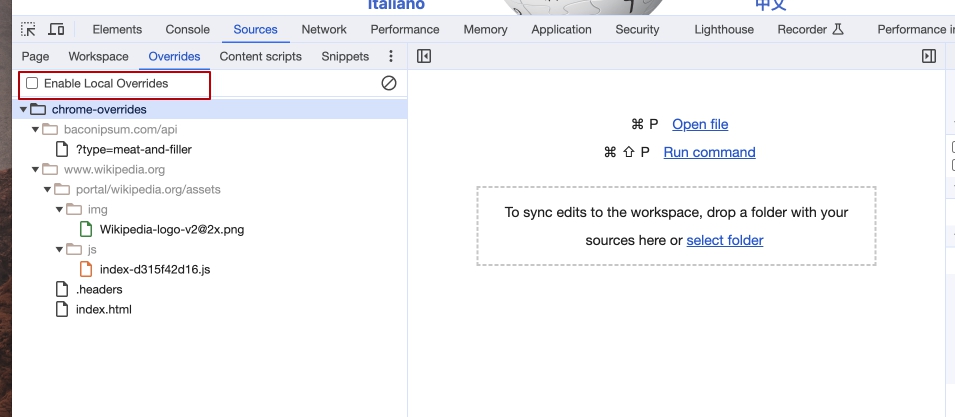
Если же вам нужно удалить одно из определений, вы можете переименовать файл переопределения или просто удалить этот файл. Сделать это можно как из панели Overrides. Удаление всей локальной директории переопределений соответственно удалит все переопределения в браузере
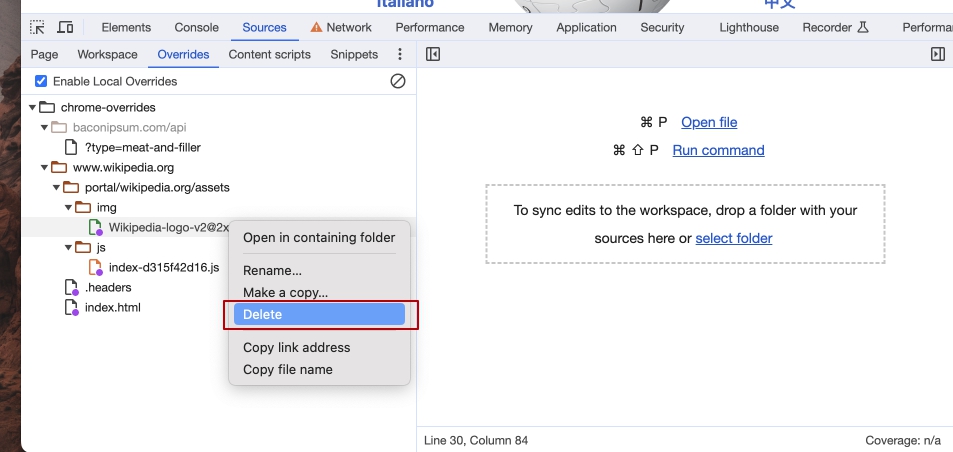
Заключение
Инструмент Local overrides позволяет быстро подменить ответ от сервера и продолжить разработку, может помочь протестировать API. Так как все локальные переопределения являются обычными файлами на файловой системе, вы можете вручную создать mock-и на будущие API и статические файлы.
Конечно данный функционал не является заменой существующим большим решениям перехвата запроса. Скорее компактной копией. В любом случае, на мой взгляд, очень полезный инструмент.
Отключение микрофона MacBook с помощью клавиши диктовки
Впервые, когда мне выдали рабочий MacBook, я по глупости считал кнопку с символом микрофона - кнопкой отключения микрофона (это казалось таким очевидным), но на самом деле это была клавиша диктовки.
Я никогда не пользовался функцией диктовки. Диктовка позволяет преобразовывать речь в текст. Возможно это полезно каким нибудь писателям, но на мой взгляд намного удобнее было бы использовать эту клавишу как отключение всех микрофонов во всей системе. В этой статье я расскажу как превратить клавишу диктовки в клавишу отключения/включения микрофона.
Установка MuteKey
MuteKey это простое, бесплатное приложение для Mac которое позволяет установить сочетание клавиш для отключения/включения микрофона.
1. Установите MuteKey. Запустите и предоставьте все необходимые разрешения.
2. Программа запущена и ее иконка отображается в верхней панели. В поле hotkey нужно задать следующее сочетание клавиш: Command - Shift - 0 (ноль). Проверьте, что назначенное сочетание работает и микрофон отключается/включается.
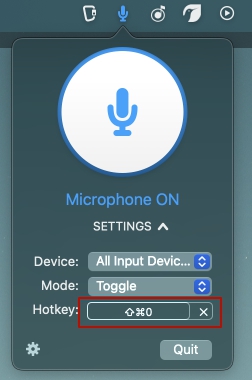
Установка Karabiner
Karabiner — бесплатное программа, позволяющая переназначать нажатия клавиш. Мы будем использовать его, чтобы переназначить клавишу диктовки (F5) на сочетание клавиш MuteKey.
1. Установите Karabiner. Вам нужно будет предоставить ему различные разрешения, программа подскажет вам что нужно сделать.
2. Запустите Karabiner-Elements
3. Установите кастомное сопоставление (custom mapping). Для этого щелкните эту ссылку, чтобы отправить карту сопоставлений клавиш в Karabiner.
4. Нажмите "Import".
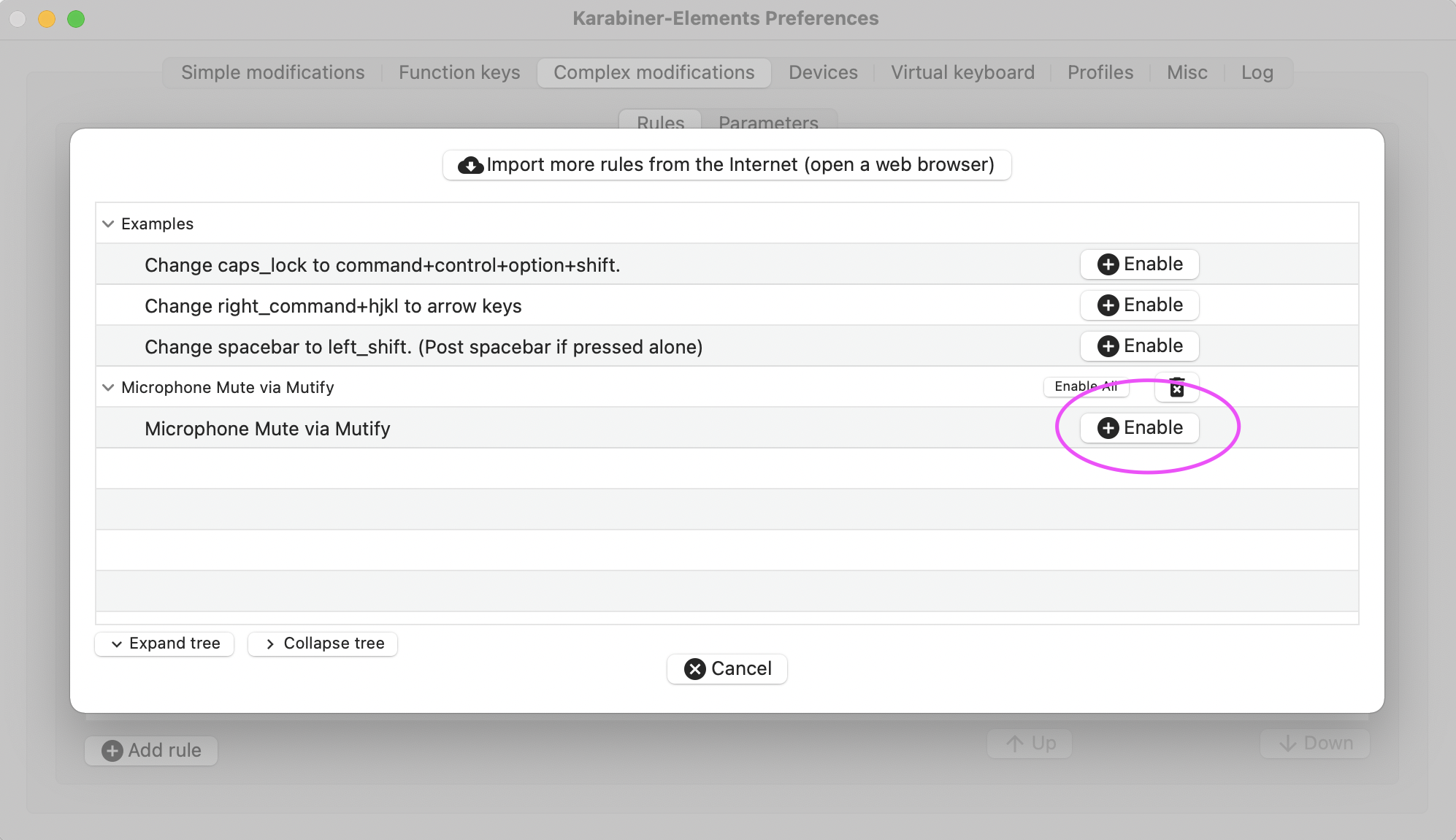
5. Нажмите "Enable".
Заключение
Теперь ваша клавиша диктовки (кнопка с микрофоном) должна отключить микрофон, пока эти два приложения работают. Вероятно, хорошей идеей будет убедиться, что обе эти программы запускаются при запуске системы.
Если все работает, когда вы нажимаете клавишу диктовки, вы должны увидеть, что значок MuteKey меняется.
P.S. Эта статья - перевод и адаптация этой. В моей статье я использую только бесплатные программы.
Как на MacOS вставлять скопированный текст без форматирования
Предположим я хочу скопировать код из моего Github в этот блог на MacOS. Выполняю Command + C, затем Command + V. Копирование произошло, но вместе с текстом копировались и стили текста (шрифты, цвет, размер и др.) Набор копируемых свойств зависит от приложения в которое вставляется текст. Это поведение порядком надоедает. Давайте взглянем на варианты решения этой проблемы.

В статье несколько решений, поэтому ознакомьтесь со всеми прежде чем приступать к реализации.
Специальная комбинация клавиш
MacOS позволяет вставлять текст без исходного форматирования. Вместо нажатия Command + V нажмите Option + Shift + Command + V, чтобы вставить текст без форматирования.
Как всегда вставлять текст без форматирования
Комбинация выше - требует серьезной гимнастики пальцев. Вставлять таким образом каждый раз будет очень неудобно. MacOS позволяет настроить поведение при вставке контента.
Перейдите в Apple menu > System Preferences и нажмите Keyboard
Выберите Keyboard Shortcuts, затем выберите App Shortcuts
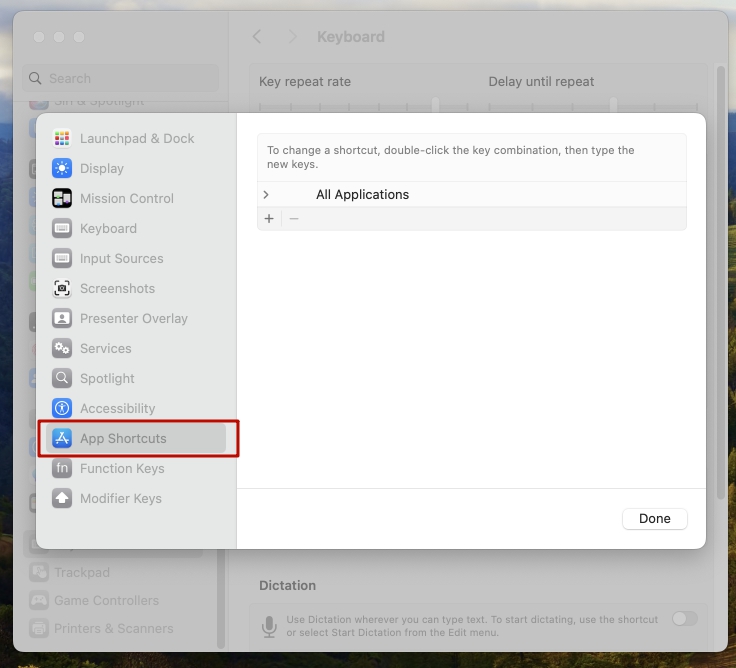
Нажмите значок Плюс (+), чтобы создать новое правило
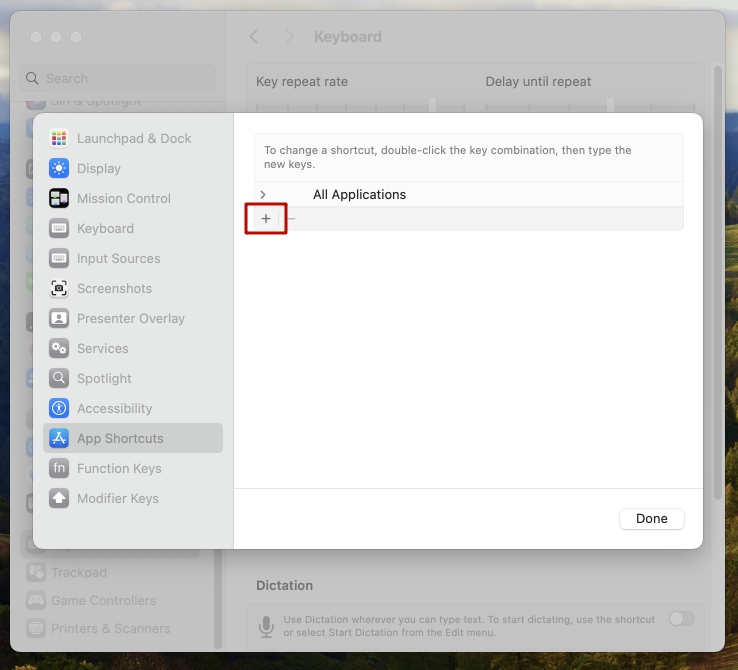
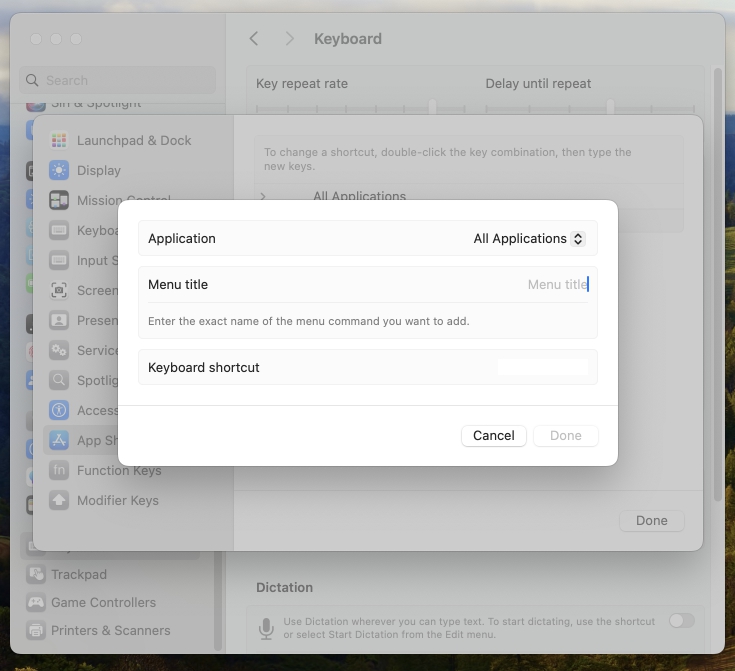
В поле Application должно быть выбрано All Applications
Введите в поде Menu title фразу Paste and Match Style (в некоторых версиях macOS нужно использовать фразу Paste & Match Style)
Поле Keyboard shortcut заполняется нажатием клавиши Command + V
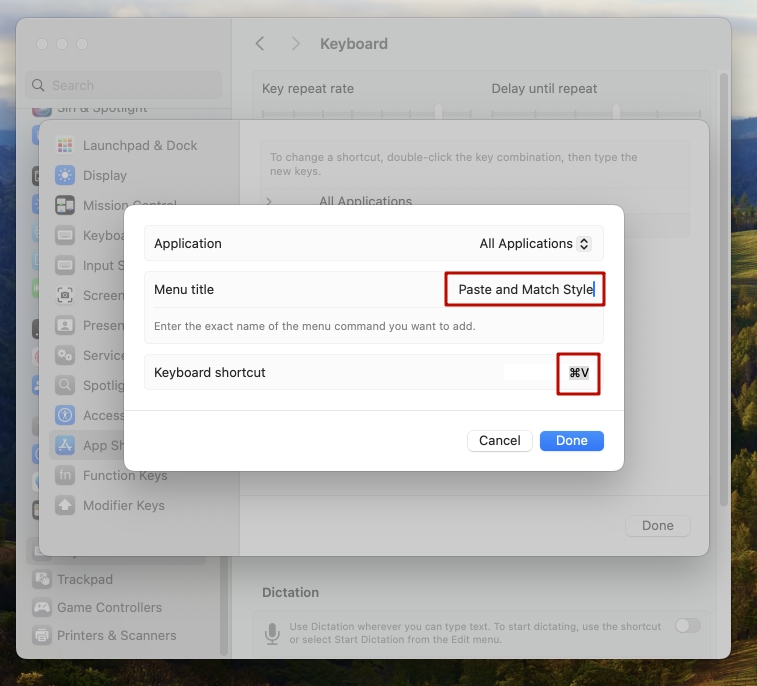
Нажмите кнопу Done. Готово. Теперь весь текст при вставке будет иметь форматирование по умолчанию для редактора.
Данное решение не идеально и у пользователей возникают разные проблемы, например:
При копировании и вставке в продуктах Microsoft (Outlook и Teams) один из пользователей не мог вставлять данные в поля, например «Кому:» или в «Чат».
Один из пользователей не смог вставлять элементы дизайна в приложении Canva
У другого пользователя форматированный текст из Windows 10 с помощью Parallels, вставляется в приложение Mac как одно длинное предложение с символами Å.
Так же, если в приложении существует собственная горячая команда Command + V, то данное решение переопределит ее.
Так что пробуйте самостоятельно, и если будут проблемы - просто удалить данное правило.
Приложение
Пока я писал эту статью, нашел замечательную утилиту под названием Paste Plain Text. Она позволяет либо автоматически форматировать весь текст попадающий в буфер обмена, либо использовать контекстное меню для вставки текста без форматирования.
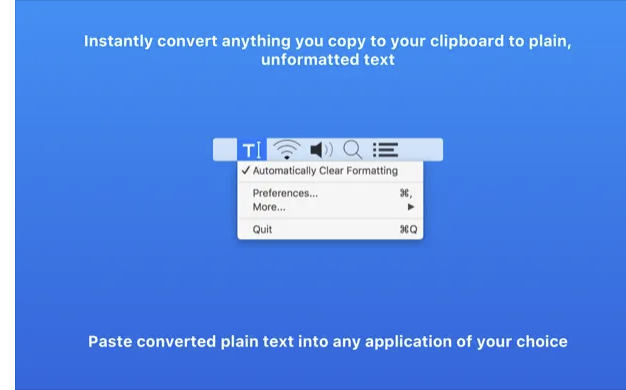
Заключение
Есть разные способы решения данной проблемы, осталось выбрать ваш вариант. Напишите в комментариях ваш вариант, возможно, вы знаете решение еще лучше.
Светлая тема в ChatGPT для macOS (Desktop App)
На момент написания этой заметки в настольном приложении ChatGPT для macOS нет встроенной настройки для переключения между светлой и тёмной темой. По умолчанию приложение наследует ту цветовую тему, которая установлена в системе: System Settings → Appearance.
Если вы хотите переопределить это поведение — например, запустить систему в тёмном режиме, а ChatGPT сделать светлым — выполните следующую команду в Terminal:
1defaults write com.openai.chat NSRequiresAquaSystemAppearance 11 — заставляет ChatGPT использовать интерфейс macOS в светлом режиме
0 — возвращает следование системным настройкам тёмной / светлой темы
После выполнения команды — перезапустите ChatGPT, чтобы изменения вступили в силу.
Связанные команды
Чтобы удалить установку NSRequiresAquaSystemAppearance (чтобы приложение вновь следило за темой системы):
1defaults delete com.openai.chat NSRequiresAquaSystemAppearanceЧтобы узнать, чему сейчас установлено значение NSRequiresAquaSystemAppearance:
1defaults read com.openai.chat NSRequiresAquaSystemAppearanceНовая фича Chrome: Split View
В Google Chrome появилась новая фича - Split View
Что такое Split View
Split View — это режим, который позволяет:
- отображать две разные вкладки одновременно на одном экране,
- менять размеры областей и перемещать вкладки между половинами,
- работать с двумя сайтами, не открывая отдельные окна.
Это делает просмотр более удобным и продуктивным, например, при сравнении страниц или написании текста с источником справа.
Где это уже работает
Браузеры Chrome обновляются так называемыми rollup-ами. То есть не весь мир сразу, а постепенно, отдельными группами. В последних версиях этот функционал включен по умолчанию.
Если ваш браузер еще не обновился, а новая версия пока не доступна можете включить фича флаг.
Чтобы включить режим, нужно:
- Открыть chrome://flags.
- Найти флаг Split View.
- Включить его и перезапустить браузер.
Затем правый клик по вкладке → «New Split View...» или аналогичный на вашем языке.
После этого Chrome разделит окно на две части.
Адресная строка меняется при клике на контент нужной страницы.
Разделить вкладки можно при клике на вкладку правой кнопкой мыши и выбрав пункат Arrange «Split View» → «Separate Views» или аналогичный на вашем языке.
Контекст и конкуренция
Браузеры вроде Edge, Vivaldi и даже некоторые сторонние на базе Chromium уже давно предлагают подобный функционал. Google не спешил с собственным Split View, но теперь догоняет конкурентов.
Вывод
Split View — это важное обновление для Chrome, которое делает браузер более удобным для профессиональной работы, исследований и многозадачности. Функция постепенно разворачивается и уже доступна в последних версиях браузера.
[Electron] Приложения поверх всех окон — даже в полноэкранном режиме или на других рабочих столах.
Перевод и адаптация заметки [Electron] Keep apps on top, whether in full-screen mode or on other desktops. Мне она очень помогла в свое время.
Я пишу приложение на Electron.
Вот что оно должно делать:
- приложение должно быть видно при переключении рабочих столов (Desktop)
- отображается поверх других приложений
- оставаться поверх даже при отображении других приложений в полноэкранном режиме
- оставаться поверх, когда Keynote находится в режиме презентации
Особенно сложно добиться отображения поверх, когда Keynote в режиме презентации. Это заметка - окончательное решение этой проблемы.
Я добавил эту настройку при открытии окон в main.js, который указан в поле main файла package.json.
1const { app, BrowserWindow } = require("electron");
2const path = require('path');
3
4const is_mac = process.platform==='darwin'
5
6if(is_mac) {
7 app.dock.hide() // - 1 -
8}
9
10const MAIN_WINDOWS_WIDTH = 300;
11const MAIN_WINDOWS_HEIGHT = 350;
12
13function createClapWindow() {
14 // Create the browser window.
15 const mainWindow = new BrowserWindow({
16 width: MAIN_WINDOWS_WIDTH,
17 height: MAIN_WINDOWS_HEIGHT,
18 webPreferences: {
19 preload: path.join(__dirname, 'preload.js'),
20 }
21 })
22
23 mainWindow.setAlwaysOnTop(true, "screen-saver") // - 2 -
24 mainWindow.setVisibleOnAllWorkspaces(true) // - 3 -
25 mainWindow.loadFile('public/reaction.html')
26}
27
28app.whenReady().then(() => {
29 createClapWindow()
30})1. app.dock.hide()
Эта настройка позволяет macOS отображать окно поверх полноэкранного режима. Поскольку в Windows такой настройки нет, я предварительно проверяю, что это именно macOS. Настройка применяется только для macOS.
2. mainWindow.setAlwaysOnTop(true, "screen-saver")
Эта настройка позволяет отображать окно поверх, когда Keynote находится в режиме презентации.
В BrowserWindow есть параметр alwaysOnTop. Когда я устанавливал его в true, окно отображалось поверх других приложений, но не поверх режима презентации Keynote.
Поэтому мне пришлось использовать следующую настройку: mainWindow.setAlwaysOnTop(true, "screen-saver").
3. mainWindow.setVisibleOnAllWorkspaces(true)
Эта настройка позволяет отображать окно при переключении на другие рабочие столы (workspaces).
Справочные ссылки
P.S.
Благодяря этой заметке мне удалось написать эту программу: https://github.com/Hydrock/TransLatte
Волшебная кнопка для вставки кода на MacOS
Вы когда-нибудь ловили себя на том, что постоянно печатаете тройные кавычки ```, чтобы начать код-блок? И вот руки уже тянутся к клавише `… А потом вы пять раз исправляете раскладку, ловите неправильный символ, удаляете, снова вводите… Короче — боль.
Но сегодня боль закончится 💉✨
Мы заставим клавишу ` (backtick) вести себя примерно так: нажал быстро → печатает обычную кавычку ` ,а подержал секунду → магическим образом появляется блок кода.
1```
2
3```И всё это — без сторонних монстров вроде Alfred/TextExpander, только Karabiner-Elements и немного AppleScript-магии.
Поехали:
Что понадобится:
- macOS
- Karabiner-Elements (бесплатно, хороший, не кусается)
- Пара минут времени
---
Шаг 1. Включаем нужные разрешения
Karabiner должен иметь право имитировать нажатие клавиш.
Идём сюда:
System Settings → Privacy & Security → Accessibility
Добавляем галочки для:
- Karabiner-Elements
- Karabiner EventViewer (если есть)
- Karabiner Console (если есть)
Что такое Karabiner-Elements?
Karabiner-Elements — это мощная утилита для macOS, которая позволяет:
переназначать клавиши,
создавать горячие клавиши,
навешивать действия на удержание клавиши,
блокировать/включать клавиши,
создавать разные профили (например, “работа”, “игры”, “кодинг”).
Главное: Karabiner работает на очень низком уровне, практически “слушая” клавиатуру напрямую, поэтому:
он видит каждое нажатие,
умеет подменять события,
может выполнять shell-команды,
а значит — может запускать osascript.
Что такое osascript?
osascript — это способ выполнять AppleScript или JavaScript for Automation из терминала.
То есть ты можешь написать:
1osascript -e 'tell application "System Events" to keystroke "Hello!"'И macOS выполнит это так, как будто ты руками напечатал “Hello!”.
Через osascript можно:
эмулировать нажатия клавиш,
вводить текст,
управлять приложениями,
нажимать кнопки UI,
даже управлять окнами.
Шаг 2. Проверяем, что AppleScript работает
Открой Karabiner → Complex Modifications → Add rule → Add your own → вставь это правило:
1{
2 "description": "TEST: Hold ` prints HELLO",
3 "manipulators": [
4 {
5 "type": "basic",
6 "from": { "key_code": "grave_accent_and_tilde" },
7 "parameters": {
8 "basic.to_if_held_down_threshold_milliseconds": 700
9 },
10 "to_if_held_down": [
11 {
12 "shell_command": "osascript -e 'tell application \"System Events\" to keystroke \"HELLO\"'"
13 }
14 ],
15 "to_if_alone": [
16 { "key_code": "grave_accent_and_tilde" }
17 ]
18 }
19 ]
20}Теперь:
короткое нажатие → `
удержание → HELLO
Если HELLO появляется — мы красавчики. Скрипт отрабатывает.
Шаг 3. Вставляем блок кода с переносами строк
Теперь меняем тестовое правило на ОНО — финальную рабочую версию:
1{
2 "description": "Hold ` to insert markdown block",
3 "manipulators": [
4 {
5 "from": {
6 "key_code": "grave_accent_and_tilde",
7 "modifiers": { "optional": ["any"] }
8 },
9 "parameters": { "basic.to_if_held_down_threshold_milliseconds": 700 },
10 "to_if_alone": [{ "key_code": "grave_accent_and_tilde" }],
11 "to_if_held_down": [
12 { "shell_command": "osascript -e 'tell application \"System Events\" to keystroke \"```\"'" },
13 { "shell_command": "osascript -e 'key code 36'" },
14 { "shell_command": "osascript -e 'key code 36'" },
15 { "shell_command": "osascript -e 'tell application \"System Events\" to keystroke \"```\"'" }
16 ],
17 "type": "basic"
18 }
19 ]
20}Теперь магия работает так:
Быстро нажал `
→ печатается обычная backtick-кавычка
Подержал 0.7 секунды
→ вставляется:
1```
2
3```🎉 Готово!
Теперь у вас полноценная “клавиша для code blocks”, которая экономит сотни нажатий в день.
macOS 26: Нативные Linux-контейнеры без Docker
На WWDC 2025 Apple представила множество обновлений, включая новый дизайн Liquid Glass. Однако среди громких анонсов легко было упустить одну из ключевых функций для разработчиков — фреймворк Containerization.
Теперь macOS 26 позволяет запускать Linux-контейнеры напрямую на Mac без использования Docker или виртуальных машин. Это решение обеспечивает нативную поддержку контейнеров и построено на открытом исходном коде, оптимизированном для чипов Apple Silicon.
По словам технического блогера Xe Iaso, ранее запуск Linux через Docker или виртуальные машины требовал больших системных ресурсов и значительно сокращал время работы от аккумулятора. Контейнеризация от Apple решает эти проблемы — разработчики получают быструю, изолированную и энергоэффективную среду.
Containerization позволяет:
- создавать и загружать Linux-образы
- запускать контейнеры локально на Mac
- обеспечивать безопасную изоляцию между контейнерами.
Сейчас функция доступна в бета-версии для разработчиков, и уже можно протестировать, насколько хорошо она работает. Как отмечает Xe Iaso, это может стать «непобедимым опытом серверной разработки, способным соперничать с тем, что придумывают инженеры Google — прямо на вашем MacBook».
Распаковка git - Скрипт
Для одного из уроков по Git мне понадобился скрипт для удобного просмотра содержимого директории .git (репозитория). (Инструкция для mac и linux)
Все данные, которые мы хотим сохранить в репозитории, Git хранит в специальных объектах. Эти объекты сжимаются с использованием утилиты zlib для экономии места. Впоследствии Git может объединять такие сжатые объекты в специальные пакеты (pack-файлы), чтобы оптимизировать хранение и ускорить доступ к данным.

В корне директории проекта создайте текстовый скрипт unpack_git_objects.sh и добавьте в него содержимое:
1#!/bin/bash
2
3# Целевая директория
4DEST_DIR='./'
5
6# Проверка наличия .git
7if [ ! -d ".git" ]; then
8 echo "Ошибка: текущая директория не содержит .git"
9 exit 1
10fi
11
12# Копируем .git в целевую директорию
13echo "Копирование .git в $DEST_DIR..."
14mkdir -p "$DEST_DIR"
15cp -r .git "$DEST_DIR"
16
17# Переходим в целевую директорию .git с использованием pushd
18pushd "$DEST_DIR/.git" || exit 1
19
20# Создаем директорию для разархивированных объектов
21UNPACKED_DIR="unpacked_objects"
22mkdir -p "$UNPACKED_DIR"
23
24echo "Разархивация объектов с использованием git cat-file..."
25# Перебираем все объекты
26for hash in $(git rev-list --all --objects | awk '{print $1}'); do
27 # Определяем тип объекта (blob, tree, commit и т.д.)
28 obj_type=$(git cat-file -t "$hash")
29 # Извлекаем содержимое объекта
30 git cat-file -p "$hash" > "$UNPACKED_DIR/$hash-$obj_type"
31 echo "Разархивирован объект: $hash ($obj_type)"
32done
33
34echo "Все объекты разархивированы в $DEST_DIR/.git/$UNPACKED_DIR"
35
36# Возвращаемся в исходную директорию с использованием popd
37popdСделайте файл исполняемым:
1chmod +x unpack_git_objects.shЗапустите скрипт:
1./unpack_git_objects.shТеперь в директории .git, будет создана директория unpacked_objects в которой будут представлены расшифрованные объекты.
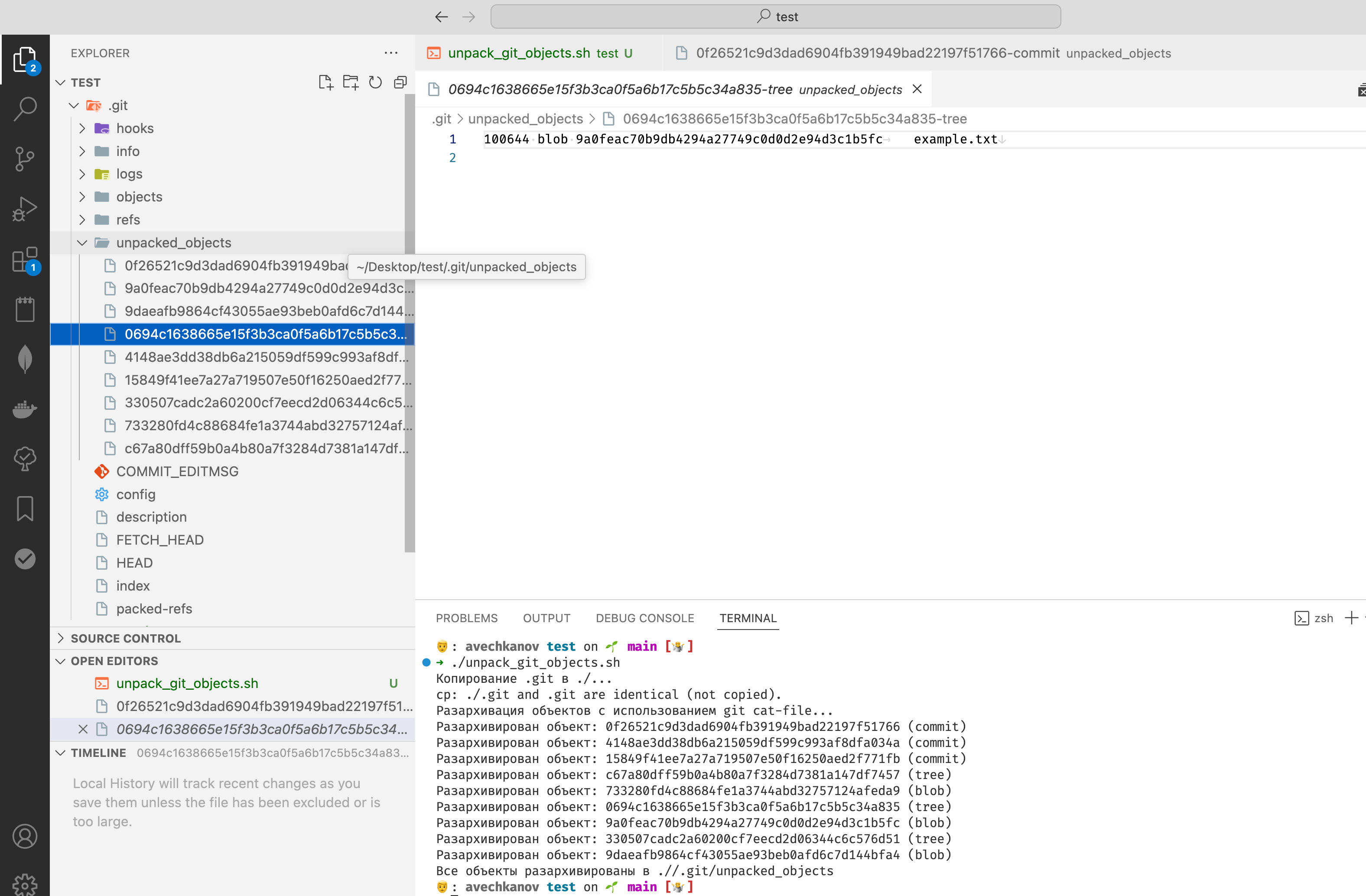
Теперь можно удобно просматривать и изучать все объекты git. В целях обучения - идеально.
Что можно сделать еще? Можно добавить команду git decode - которая будет выполнять этот скрипт.
Я работаю на mac, поэтому буду редактировать файл ~/.zshrc, если у вас linux, то добавить нужно в ~/.bashrc
1# Добавляем алиас для GIT
2git() {
3 if [ "$1" = "decode" ]; then
4 # тут расположить сам скрипт
5 else
6 command git "$@"
7 fi
8}Сохраните файл и перезапустите терминал. Теперь при запуске команды git decode в директории .git будет создаваться директория unpacked_objects с расшифрованными/разархивированными объектами git.
Почему ваш сайт должен иметь размер менее 14 КБ
Небольшой размер сайта напрямую ускоряет его загрузку — в этом нет ничего неожиданного. Удивительно другое: страница размером 14 КБ может загружаться значительно быстрее, чем страница в 15 КБ — разница способна достигать 612 мс. При этом между страницами 15 КБ и 16 КБ разница во времени загрузки уже почти незаметна.

Это связано с алгоритмом медленного запуска TCP (TCP slow start). В этой статье мы разберём, что это такое, как он работает и почему вам стоит обращать на это внимание. Но для начала кратко пройдёмся по базовым понятиям.
Это перевод/адаптация статьи Why your website should be under 14kB in size от Nathaniel
Что такое TCP?
Transmission Control Protocol (TCP) — это протокол, который поверх интернет-протокола (IP) обеспечивает надёжную передачу пакетов данных. Иногда всю эту связку называют TCP/IP.
Когда браузер запрашивает ваш веб-сайт (или, например, изображение либо таблицу стилей), он делает это с помощью протокола HTTP.
HTTP работает поверх TCP, и один HTTP-запрос обычно передаётся не одним, а несколькими TCP-пакетами.
Сам по себе IP — это лишь система доставки пакетов данных из одной точки Интернета в другую. Он не умеет проверять, дошёл ли пакет до получателя успешно.
В случае с веб-сайтами принципиально важно, чтобы все данные были получены полностью — иначе страница может загрузиться с пропусками. При этом существуют и другие сценарии использования Интернета, где подтверждение доставки не так критично, например потоковое видео в реальном времени.
TCP — это надстройка над IP, которая позволяет браузеру и серверу веб-сайта сообщать друг другу, какие пакеты были успешно доставлены, а какие — нет.
Сервер отправляет несколько пакетов, затем ждёт ответа от браузера о том, что они получены. Такой ответ называется подтверждением (ACK, от Acknowledge). После этого сервер отправляет следующую порцию пакетов — либо, если ACK не пришёл, повторно отправляет данные.
Что такое медленный старт TCP?
Медленный старт TCP (TCP slow start) — это алгоритм, который серверы используют, чтобы определить, сколько пакетов можно отправлять одновременно.
Когда браузер впервые подключается к вашему серверу, сервер не знает, какая пропускная способность доступна между ними.
Пропускная способность (bandwidth) — это объём данных, который может быть передан по сети за единицу времени. Обычно её измеряют в битах в секунду (бит/с). Часто используют аналогию с сантехникой: представьте пропускную способность как то, сколько воды может протекать по трубе за секунду.
Сервер не знает, какой объём данных способно выдержать соединение, поэтому сначала отправляет небольшой и безопасный объём — обычно около 10 TCP-пакетов.
Если эти пакеты успешно доходят до посетителя сайта, его компьютер отправляет серверу подтверждение (ACK), сообщая, что данные были получены.
После этого сервер отправляет следующую порцию данных, увеличивая количество пакетов вдвое.
Этот процесс повторяется до тех пор, пока пакеты не начнут теряться или сервер не перестанет получать подтверждения ACK. В этот момент сервер продолжает передачу данных, но снижает скорость отправки.
В этом и заключается суть медленного старта TCP (TCP slow start). В реальности конкретная реализация алгоритма может отличаться, но в общих чертах он работает именно так.
Так откуда же взялись 14кБ?
Большинство реализаций TCP slow start на веб-серверах начинают передачу именно с 10 TCP-пакетов.
Максимальный размер TCP-пакета составляет 1500 байт.
Этот предел задан не спецификацией TCP — он следует из стандарта Ethernet.
Каждый пакет TCP использует 40 байт в заголовке — 16 байт для IP и дополнительные 24 байта для TCP (IP-пакет содержит TCP-сегмент).
Остается 1460 байт на содержимое TCP-пакета. 10 x 1460 = 14600 байт или примерно 14 КБ!
Поэтому, если вам удастся уместить весь сайт — или хотя бы его критически важную часть — в 14 КБ, вы сэкономите пользователям значительное количество времени. Речь идёт о времени, необходимом на один сетевой «туда-обратно» (round trip) между браузером посетителя и вашим сервером.
Насколько плохой может быть поездка туда и обратно?
Люди очень нетерпеливы, и даже один сетевой проход туда-обратно может занимать неожиданно много времени. Сколько именно — зависит от задержки (latency) сети…
Задержка (latency) — это время, за которое пакет данных проходит путь от источника до получателя. Если пропускная способность — это то, сколько воды может протекать по трубе за секунду, то задержка — это время, за которое одна капля входит в трубу и выходит с другого конца.
Вот забавный пример того, насколько плохой может быть задержка:
Спутниковый интернет
Спутниковый интернет обеспечивается спутниками, находящимися на орбите Земли. Его используют в труднодоступных и малонаселённых районах, на нефтяных платформах, круизных лайнерах, а также для Wi-Fi на борту самолётов.
Чтобы наглядно показать, что такое плохая задержка, представим следующую ситуацию: группа рабочих на нефтяной платформе забыла дома игральные кости и вынуждена использовать отличный сайт Missingdice.com (размером менее 14 КБ), чтобы играть в Dungeons & Dragons.

Сначала один из них использует свой телефон, чтобы сделать запрос на веб-страницу…
Телефон отправляет этот запрос на Wi-Fi-маршрутизатор платформы, а тот передаёт данные на спутниковую тарелку. Будем оптимистичны и предположим, что на это уходит всего 1 мс.
Затем спутниковая антенна должна отправить эти данные на спутник, находящийся на орбите над Землей.
Обычно это достигается с помощью спутника на геостационарной орбите на высоте 35786 км над поверхностью Земли. Скорость света составляет 299792458 м/с, поэтому сообщение, отправленное с Земли на спутник, занимает 120 мс. Затем спутник отправляет сообщение обратно на наземную станцию, что занимает еще 120 мс.
Затем наземная станция должна отправить запрос туда, где находится сервер на земле (свет замедляется до 200000000 м/с, когда он находится в оптоволоконном кабеле). Если расстояние между наземной станцией и сервером такое же, как расстояние между Нью-Йорком и Лондоном, это займет около 28 мс, но если оно больше похоже на расстояние между Нью-Йорком и Сиднеем, оно займет 80 мс, поэтому мы назовем это 60 мс (удобное число для наших математических вычислений).
Затем запрос должен быть обработан сервером, что может занять около 10 мс, после чего сервер снова отправляет его обратно.
Обратно на наземную станцию, в космос, обратно к спутниковой антенне, затем к Wi-Fi маршрутизатору и снова к телефону нашего нефтяника.
1phone -> WiFi router -> satellite dish -> satellite -> ground station -> server -> ground station -> satellite -> satellite dish -> WiFi router -> phone
2Если мы посчитаем, то это будет 10 + ( 1 + 120 + 120 + 60 ) x 2 = 612 мс.
Это означает дополнительные 612 мс на каждый сетевой «туда-обратно». Возможно, на первый взгляд это не кажется слишком долгим ожиданием, но на веб-сайте может потребоваться несколько таких проходов ещё до того, как браузер получит самый первый ресурс.
Кроме того, HTTPS требует двух дополнительных циклов передачи данных, прежде чем он сможет выполнить первый — что дает нам время до 1836 мс!
А как насчет задержки у людей, живущих на суше?
Спутниковый интернет может показаться заведомо плохим примером — я выбрал его именно потому, что он наглядный и немного экстремальный. Однако и у пользователей «на суше» задержка может быть не меньше, а иногда и хуже, по целому ряду причин:
- Мобильные устройства 2G обычно имеют задержку от 300 до 1000 мс.
- Сети 3G могут иметь задержку от 100 до 500 мс.
- Шумная мобильная сеть — скажем, в необычно людном месте, например на музыкальном фестивале.
- Серверы, работающие с большими объемами трафика
Неоднородные и нестабильные соединения также могут приводить к потере пакетов, из-за чего требуется дополнительный сетевой «туда-обратно», чтобы повторно получить утраченные данные.
Теперь, когда вы знаете о правиле 14 КБ, что вы можете сделать?
Разумеется, стоит делать сайт как можно меньшего размера — вы заботитесь о своих посетителях и хотите, чтобы им было комфортно. Поэтому стремиться к тому, чтобы каждая страница укладывалась в 14 КБ, — это отличная и вполне разумная цель.
Эти 14 КБ считаются уже с учётом сжатия, то есть фактически это может быть около 50 КБ несжатых данных — что, по меркам веба, весьма щедро. Для сравнения: у компьютеров управления «Аполлона-11» было всего 72 КБ памяти.
Как только вы избавитесь от автозапускаемых видео, всплывающих окон, cookie-баннеров, кнопок социальных сетей, трекеров, а также громоздких JavaScript- и CSS-фреймворков и прочего мусора, который мало кому нравится, — вы, скорее всего, уже уложитесь в этот предел.
Но даже если вы очень старались уложиться в 14 КБ, но всё же не смогли, это правило всё равно остаётся полезным ориентиром.
Если вы уверены, что первые 14 КБ данных, отправляемые пользователю, позволяют отобразить что-то действительно полезное — например, критически важные CSS и JS, а также первые абзацы текста с объяснением того, как пользоваться вашим приложением.
Примечание. Правило 14 КБ включает в себя и HTTP-заголовки, которые не сжимаются (даже при использовании HTTP/2 в первом ответе сервера). Оно также включает изображения, поэтому загружайте только то, что находится выше сгиба (above the fold) (имеется ввиду первый экран сайта), делайте изображения максимально лёгкими или используйте прелоадеры, чтобы посетители понимали, что загрузка идёт и впереди их ждёт что-то полезное.
Некоторые предостережения относительно правила
Правило 14 КБ больше похоже на эмпирическое правило, чем на фундаментальный закон:
- Некоторые серверы увеличили начальное окно медленного запуска TCP до 30 пакетов вместо 10.
- Иногда сервер знает, что он может начать с большего количества пакетов, поскольку он использовал подтверждение TLS для установления возможности использования большего окна.
- Серверы могут кэшировать количество пакетов, которые может обрабатывать маршрут, и отправлять больше при следующем подключении.
- Есть и другие предостережения — здесь более подробная статья о том, почему правило 14 КБ не всегда работает.
HTTP/2 и правило 14 КБ
Иногда можно услышать мнение, что правило 14 КБ перестаёт быть актуальным при использовании HTTP/2. Я изучил всё, что смог по этой теме, не доводя себя до изнеможения, и не нашёл никаких подтверждений тому, что серверы с HTTP/2 перестали использовать медленный старт TCP или начали отправку данных с объёма больше 10 пакетов.
HTTP/3 и QUIC
Как и в случае с HTTP/2, существует мнение, что HTTP/3 и QUIC покончат с правилом 14 КБ — это неправда. QUIC рекомендует то же правило 14 КБ.
Дополнительная информация
Большая часть содержания этого поста взята из следующих ресурсов:
Network Information API – как узнать состояние сети прямо в браузере
В современном мире оптимизация веб-приложений под различные сетевые условия становится ключевым аспектом разработки. Network Information API предоставляет необходимые данные о соединении устройства, помогая разработчикам адаптировать работу приложений в зависимости от качества сети пользователя.

Что такое Network Information API?
Network Information API — это интерфейс, предоставляющий информацию о типе подключения и характеристиках сети пользователя, таких как пропускная способность, тип соединения и задержка. Данный API входит в состав Navigator интерфейса и доступен через объект navigator.connection.
Основные характеристики и возможности
Тип соединения
API предоставляет свойство type, обозначающее тип сети, к которой подключен пользователь. Возможные значения:
- bluetooth
- cellular
- ethernet
- wifi
- wimax
- other
- none (отсутствие сети)
Эффективная пропускная способность
Свойство effectiveType указывает на качество соединения с возможными значениями:
- slow-2g
- 2g
- 3g
- 4g
Ширина канала
Свойство downlink показывает примерную ширину канала в мегабитах в секунду, что позволяет оценить скорость загрузки данных.
Задержка
Свойство rtt (round-trip time) измеряет задержку в миллисекундах, помогая оценить скорость отклика сервера.
Экономия трафика
Свойство saveData указывает, активирован ли режим экономии трафика, что полезно для минимизации объема передаваемых данных.
Практическое использование
Network Information API позволяет адаптировать функциональность приложения. Например, можно уменьшить количество сетевых запросов при медленном соединении. Вот пример использования API:
1if ('connection' in navigator) {
2 const connection = navigator.connection;
3
4 function updateNetworkStatus() {
5 console.log('Тип соединения:', connection.effectiveType);
6 console.log('Задержка:', connection.rtt + 'ms');
7 console.log('Ширина канала:', connection.downlink + 'Mb/s');
8 console.log('Экономия данных:', connection.saveData ? 'Включена' : 'Выключена');
9
10 if (connection.saveData || connection.effectiveType === '2g') {
11 // Принять меры для экономии данных, например, отключить автозагрузку изображений
12 }
13 }
14
15 connection.addEventListener('change', updateNetworkStatus);
16 updateNetworkStatus();
17} else {
18 console.log('Network Information API не поддерживается в этом браузере.');
19}Примеры использования Network Information API
1. Адаптация изображений и медиа
На медленной сети загружаются облегчённые изображения и превью вместо видео, на быстрой — полное качество. Снижает время первого рендера и расход трафика.
2. Условная загрузка JavaScript
Тяжёлые модули (аналитика, графики, видео-плееры) подгружаются только при хорошем соединении. Улучшает TTI и стабильность SPA.
3. Управление prefetch и preload
Prefetch ресурсов отключается при saveData или 2g/3g, чтобы не ухудшать UX. Часто используется в SEO-ориентированных и e-commerce сайтах.
4. PWA и offline-first сценарии
Фоновая синхронизация и частые запросы откладываются на плохой сети и возобновляются при улучшении соединения.
5. Деградация интерфейса
На медленной сети уменьшается количество анимаций, real-time обновлений и визуальных эффектов, сохраняя отзывчивость интерфейса.
Ограничения и поддержка
Network Information API доступен не во всех браузерах, и его функции могут варьироваться. В большинстве современных версий Chrome и Edge данное API поддерживается, однако в Safari и Firefox — нет.

Заключение
Network Information API — мощный инструмент для улучшения UX и оптимизации использования сетевых ресурсов в веб-приложениях под различные сетевые условия. Однако следует предусмотреть альтернативные решения для браузеров без поддержки этого API.
Настройки в GIT: Основы для комфортной работы
Git — это мощный инструмент для управления версиями, но для эффективной работы необходимо правильно настроить его под свои нужды. В этой статье мы рассмотрим основные настройки, которые помогут вам начать работать с Git максимально комфортно.

Для начала, необходимо уяснить, что Git позволяет настраивать параметры на трех уровнях: глобальном, локальном и системном. Разберем каждый из них.
1. Глобальный уровень (--global)
Настройки применяются ко всем репозиториям для текущего пользователя на этом компьютере. Эти параметры хранятся в файле ~/.gitconfig (или %USERPROFILE%\.gitconfig на Windows).
Пример:
1git config --global user.name "Ваше Имя"
2git config --global user.email "ваш_email@example.com"Когда использовать:
Когда вы хотите задать параметры, которые будут применяться ко всем вашим проектам на текущей машине, например имя пользователя, email или алиасы.
2. Локальный уровень (по умолчанию, без флага)
Настройки применяются только к конкретному репозиторию. Они хранятся в файле .git/config в корневой папке репозитория.
Пример:
1git config user.name "Локальное Имя"
2git config user.email "local_email@example.com"Когда использовать:
Если проект требует настроек, отличных от глобальных. Например, вы работаете под разными именами или email в разных репозиториях.
3. Системный уровень (--system)
Настройки применяются для всех пользователей и всех репозиториев на данной машине. Эти параметры хранятся в файле конфигурации, который обычно расположен в /etc/gitconfig (или C:\ProgramData\Git\config на Windows).
Пример:
1sudo git config --system core.editor nanoКогда использовать:
Если проект требует настроек, отличных от глобальных. Например, вы работаете под разными именами или email в разных репозиториях.
Как узнать, на каком уровне установлен параметр?
Чтобы проверить значение настройки и ее уровень, используйте команду:
1git config --list --show-originВы увидите список всех параметров, а также файлы, из которых они были загружены.
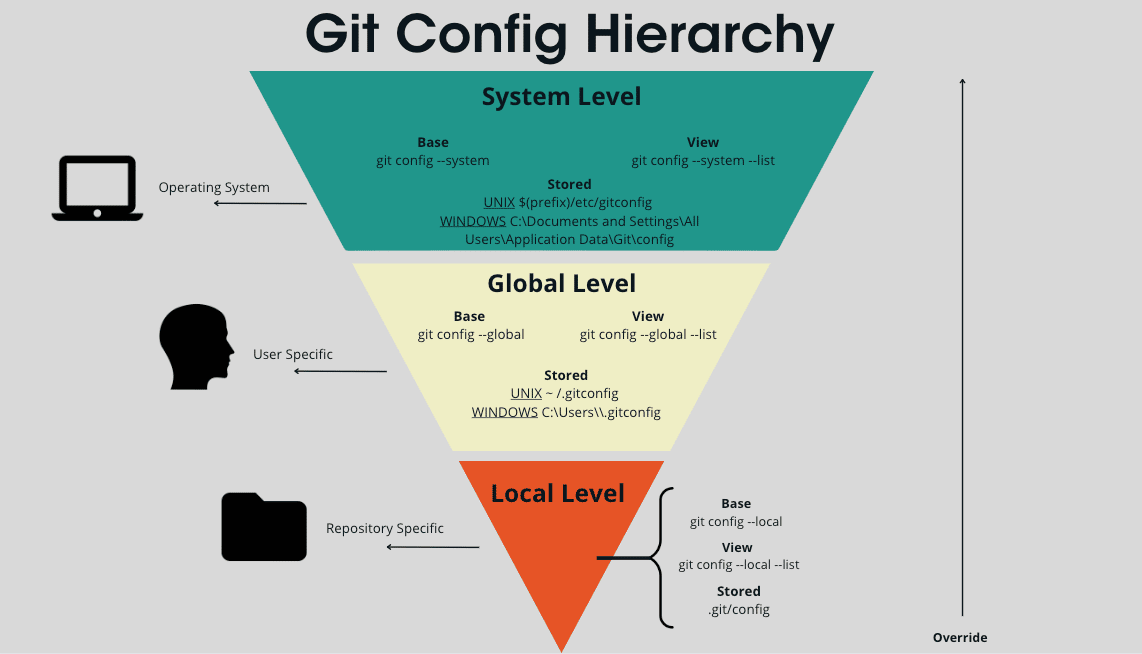
Порядок приоритетов уровней
Если один и тот же параметр задан на нескольких уровнях, Git использует настройки в следующем порядке (от наивысшего приоритета к низшему):
1. Локальный (файл .git/config в репозитории).
2. Глобальный (файл ~/.gitconfig).
3. Системный (файл /etc/gitconfig).
Таким образом, локальная настройка всегда переопределяет глобальную и системную.
1. Настройка имени пользователя и электронной почты
Каждое изменение в Git сопровождается информацией о том, кто его сделал. Чтобы настроить имя и email, используйте команды:
1git config --global user.name "Ваше Имя"
2git config --global user.email "ваш_email@example.com"Флаг --global применяет настройки ко всем репозиториям на вашем компьютере. Если хотите задать настройки только для конкретного репозитория, уберите флаг --global.
2. Выбор редактора
По умолчанию Git использует системный текстовый редактор (например, vi на Linux). Вы можете задать редактор, который вам удобен, например nano или vscode:
1git config --global core.editor "nano"Для VS Code настройка будет выглядеть так:
1git config --global core.editor "code --wait"Флаг --wait в команде code --wait используется для того, чтобы заставить Git дождаться завершения работы редактора перед продолжением выполнения команды.
Как это работает:
1. Когда вы, например, создаете сообщение для коммита с помощью команды:
1git commitи Git вызывает указанный редактор (в данном случае VS Code), то без флага --wait Git завершит выполнение сразу после открытия редактора. Это может привести к ошибкам или созданию пустого коммита, если вы не успеете завершить редактирование.
2. С флагом --wait Git ждет, пока вы закончите редактирование файла в VS Code и закроете вкладку или редактор. Только после этого Git продолжит выполнение команды.
Когда это важно:
Флаг особенно полезен для операций, которые требуют взаимодействия с текстовым редактором, например:
• Написание сообщений для коммитов (git commit).
• Редактирование сообщений для интерактивного ребейза (git rebase -i).
• Настройка файлов конфигурации через Git.
Без флага --wait
Если вы не укажете --wait, то Git посчитает, что работа с файлом завершена, сразу после запуска VS Code. В результате:
• Файл может остаться пустым.
• Команда может завершиться с ошибкой.
Флаг --wait необходим для редакторов, которые работают в фоновом режиме или запускаются как графическое приложение (например, VS Code, Sublime Text). В таких случаях Git должен знать, что процесс редактирования завершён, и для этого требуется явное указание подождать завершения работы редактора.
В случае с текстовыми редакторами, такими как nano или vim, флаг --wait не нужен, потому что они:
1. Запускаются в том же терминале:
Когда вы запускаете nano, терминал переходит в режим редактирования прямо в текущем окне. Пока вы не закроете редактор (например, нажав Ctrl+O для сохранения и Ctrl+X для выхода), Git не продолжит выполнение команды.
2. По умолчанию блокируют выполнение последующих команд:
Такие редакторы работают синхронно, и Git автоматически ожидает завершения работы редактора, без необходимости в дополнительном флаге.
Почему графическим редакторам нужен --wait?
Редакторы вроде VS Code работают асинхронно. Когда вы запускаете code, приложение открывается в отдельном окне, и процесс, который вызвал редактор (в данном случае Git), может продолжить выполняться, не дожидаясь завершения редактирования. Флаг --wait изменяет это поведение, заставляя Git ожидать закрытия редактора.
Итог:
• Для редакторов, работающих в терминале (nano, vim), флаг --wait не нужен, так как они блокируют терминал до завершения работы.
• Для графических редакторов (code, sublime) флаг --wait нужен, чтобы Git подождал, пока вы закончите редактирование.
3. Настройка цветовой схемы
Git предоставляет цветовую подсветку для удобного отображения статуса файлов, логов и диффов. Чтобы включить цвета, выполните:
1git config --global color.ui autoНачиная с более поздних версий Git (примерно с 1.8.4), цветовая подсветка включена по умолчанию для большинства систем. Настройка color.ui уже установлена в значение auto, если вы используете современную версию Git. Однако, в некоторых ситуациях или старых версиях Git, раскрашивание может быть отключено, и явная настройка помогает это гарантировать.
Что делает color.ui auto?
• Значение auto говорит Git, что цвета должны отображаться только в интерактивных средах (например, в терминале), но не в скриптах или перенаправленных выводах (где цвета могут мешать).
• В скриптах (например, git log > log.txt):
Цвета не отображаются, так как это текстовый файл.
Цвета в терминале основаны на кодах управления ANSI (ANSI escape codes), которые используются для форматирования текста, изменения его цвета и других визуальных эффектов. Эти коды — стандарт для большинства терминалов, и Git использует их для цветовой подсветки.
Как работают ANSI-коды?
ANSI-коды представляют собой последовательности символов, начинающиеся с \033[ (или ESC[), за которыми следуют числовые значения, разделенные точкой с запятой. Например:
• Код \033[31m устанавливает красный цвет текста.
• Код \033[1;32m включает жирный шрифт и зеленый текст.
• Код \033[0m сбрасывает все форматирование.
Пример применения:
1echo -e "\033[31mКрасный текст\033[0m"То есть, отображение цветов, на самом деле, это вставка в текст специальных кодов/тегов которые задают цвет текста. Да, при выводе в терминал мы хотим видеть цветной текст, но если захотим вывести результаты выполнения команд git в текстовый файл - то эти коды в текстовом файле нам не нужны. Настройка color.ui auto как раз и сообщает Git, чтобы он самостоятельно принял решение, когда нужно добавлять в текстовый вывод коды цветов, а когда не нужно.
Git и цвета в терминале
Git использует цветовую схему терминала, чтобы подчеркнуть важные элементы. Например:
• Зеленый: staged изменения.
• Красный: unstaged изменения.
• Желтый: untracked файлы.
Настроить цвета в Git можно через файл конфигурации. Например:
1git config --global color.status.added "green bold"
2git config --global color.status.changed "yellow"
3git config --global color.status.untracked "red"Проверка поддержки цвета терминалом
Вы можете проверить, сколько цветов поддерживает ваш терминал:
1echo $TERMРезультаты:
• xterm или xterm-256color: поддержка 256 цветов.
• vt100: только 16 стандартных цветов.
Цвета в терминале — это инструмент для визуального выделения текста, основанный на ANSI-кодах. Git эффективно использует эту функциональность для цветовой подсветки статуса, логов и изменений, что делает работу удобной и понятной.
4. Упрощение ввода команд
Для сокращения рутины можно создать псевдонимы (алиасы) для часто используемых команд. Например:
1git config --global alias.st status
2git config --global alias.co checkout
3git config --global alias.br branch
4git config --global alias.cm commitТеперь вместо git status можно писать git st, что экономит время.
5. Работа с окончанием строк (line endings)
Окончания строк в текстовых документах это на самом деле специальный символ, который не видно в текстовом редакторе, но он есть.
Окончания строк отличаются между операционными системами из-за исторических причин и подходов к представлению текста:
• Windows использует \r\n (Carriage Return + Line Feed) для обозначения конца строки.
• Unix/Linux/macOS используют \n (Line Feed) как окончание строки.
• Классические системы Mac (до macOS) использовали \r (Carriage Return), но этот формат уже не актуален.
Почему это важно?
1. Совместимость между ОС:
При совместной работе на разных платформах различия в окончаниях строк могут привести к неожиданным изменениям при работе с файлами:
• Git может считать, что файл изменён, просто из-за различий в форматах строк.
• Инструменты или редакторы могут некорректно интерпретировать текст.
2. Консистентность репозитория:
Для однозначного представления текста в репозитории важно придерживаться одного формата строк.
Git может автоматически конвертировать окончания строк между форматами Windows и Unix. Это особенно важно при совместной работе на разных операционных системах.
Для автоматической настройки используйте:
На Windows:
1git config --global core.autocrlf trueЭто конвертирует \r\n в \n при сохранении файлов в репозитории, а при извлечении обратно приводит их к \r\n.
На Unix (Linux/Mac):
1git config --global core.autocrlf inputКогда вы добавляете файл в репозиторий (git add), Git автоматически преобразует окончания строк из \r\n (Windows-формат) в \n (Unix-формат). Это гарантирует, что в репозитории все строки хранятся в формате \n, независимо от исходной системы, где был создан файл.
Однако, локальные файлы на вашей машине остаются без изменений. Если файл уже имеет строки в формате \n (Unix-формат), Git ничего не преобразует. Локальная версия файла сохраняется такой, какой она была.
Пример:
1. Вы копируете файл с Windows на Linux. Этот файл содержит строки с \r\n.
2. При добавлении в репозиторий (git add) Git преобразует все строки в \n, чтобы в репозитории использовался Unix-формат.
3. Локальная копия файла на вашей машине не изменится — она останется в исходном формате (с \r\n).
Итог:
• Формат строк в репозитории всегда будет стандартным для Unix (\n).
• Локальный файл на вашей машине остается без изменений (с теми окончаниями строк, с которыми вы работаете).
6. Сохранение данных для авторизации
Этот блок будет полезен, если вы не используете SSH ключи для аутентификации/авторизации в git репозитории, а используете логин и пароль по протоколу HTTPS. В любом случае, будет полезным знать о механизмах хранения авторизационных данных.
Для удобного доступа к удалённым репозиториям (GitHub, GitLab) можно настроить кэширование паролей:
Для кратковременного сохранения (например, на 15 минут):
1git config --global credential.helper cacheДля долговременного сохранения:
1git config --global credential.helper storeGit использует систему помощников по управлению учетными данными (credential helpers) для сохранения и автоматического использования данных авторизации (логинов и паролей) при подключении к удаленным репозиториям. Это упрощает работу с защищенными репозиториями и устраняет необходимость вводить пароль при каждом доступе.
Как работает система помощников Git?
1. При первом обращении к удаленному репозиторию:
• Git запрашивает имя пользователя и пароль, если они не были переданы явно (например, через URL в формате https://username@repository).
• После успешной авторизации Git может передать эти данные в хранилище (если настроен помощник по учетным данным).
2. При последующих запросах:
• Git автоматически извлекает сохраненные данные из хранилища и использует их для авторизации.
• Это предотвращает повторное ручное введение пароля.
Как работает система помощников Git?
1. При первом обращении к удаленному репозиторию:
• Git запрашивает имя пользователя и пароль, если они не были переданы явно (например, через URL в формате https://username@repository).
• После успешной авторизации Git может передать эти данные в хранилище (если настроен помощник по учетным данным).
2. При последующих запросах:
• Git автоматически извлекает сохраненные данные из хранилища и использует их для авторизации.
• Это предотвращает повторное ручное введение пароля.
Основные виды помощников по учетным данным
1. Кратковременное сохранение: cache
• Пароль хранится в памяти (RAM) только на ограниченное время.
• По умолчанию, данные хранятся 15 минут, но вы можете изменить этот интервал:
1git config --global credential.helper 'cache --timeout=3600'(3600 секунд = 1 час)
• Пример:
Если вы работаете с репозиторием и периодически отправляете изменения, Git запрашивает пароль только один раз в течение установленного времени.
2. Долговременное сохранение: store
• Данные авторизации сохраняются в текстовом файле в незашифрованном виде.
• Локация: ~/.git-credentials (или аналогичная для вашей ОС).
• Включение:
1git config --global credential.helper store• Риски:
Пароли хранятся в виде обычного текста. Если другие пользователи имеют доступ к вашей системе, они могут прочитать этот файл.
3. Интеграция с системой: manager (Windows, macOS)
• Использует безопасные хранилища ОС:
• Windows: Credential Manager.
• macOS: Keychain.
• Linux: libsecret.
• Включение (если поддерживается в вашей системе):
1git config --global credential.helper manager• Безопасность:
Пароли шифруются и хранятся в безопасном месте, предоставляемом ОС.
4. Удаление сохраненных учетных данных
• Чтобы удалить сохраненные данные, используйте:
1git credential-cache exitГде хранятся настройки?
• cache: в оперативной памяти, до истечения времени.
• store: в файле ~/.git-credentials.
• manager: в безопасном хранилище ОС (Windows Credential Manager, macOS Keychain, и т.д.).
Проверка текущего помощника:
Чтобы узнать, какой помощник используется в вашей системе:
1git config --get credential.helperGit предоставляет несколько способов управления данными авторизации, от временного хранения до интеграции с безопасными системами ОС. Для большинства пользователей рекомендуется использовать manager, так как это безопасный и удобный вариант, особенно для долговременной работы.
Если вы используете SSH-ключи для аутентификации, системы помощников по учётным данным Git не нужны. SSH-ключи — это более безопасный и удобный способ работы, особенно для долгосрочных проектов.
7. Просмотр всех настроек
Чтобы убедиться, что настройки работают правильно, вы можете вывести список всех конфигураций:
1git config --list8. Сброс настроек
Если вы хотите сбросить настройки, выполните:
Для всех глобальных параметров:
1git config --global --unset имя_параметраДля конкретного репозитория:
1git config --unset имя_параметраЗаключение
Настройка Git — это важный шаг для повышения вашей продуктивности. Даже базовые изменения, такие как добавление алиасов или выбор удобного редактора, значительно облегчают работу. Настройте Git под себя и наслаждайтесь комфортной разработкой!
Истоки и эволюция редакторов Vi и Vim
История Vi и Vim тесно переплетается с развитием программного обеспечения с открытым исходным кодом (Open Source Software). В этой статье мы отправимся в путешествие к истокам текстовых редакторов UNIX, чтобы рассмотреть ключевых участников и важные события, повлиявшие на их эволюцию.

Эта статья основана на посте Gustavo Pezzi: Understanding the Origins and the Evolution of Vi & Vim. Статья дополнена подробностями и уточнениями для более глубокого понимания.
Наше путешествие начнётся с Университета Королевы Марии, сыгравшего ключевую роль в истории редактора Vim. В 1973 году именно здесь была установлена первая в Великобритании система UNIX. Кроме того, профессор Джордж Кулурис разработал текстовый редактор под названием em. Этот редактор стал предшественником vi и вдохновил создание множества его клонов, включая Vim.

Ed
В UNIX-оболочках всё основано на тексте. Исполняемые файлы запускаются текстовыми командами, параметры передаются в текстовом формате, а потоки данных перемещаются по системе, используя текст. Практически все операции в ОС выполняются с помощью текстовых токенов. Неудивительно, что пользователи UNIX так увлечены текстовыми редакторами.
Думаю, нам следует начать с ed — редактора командной строки, созданного Кеном Томпсоном и предназначенного для работы с телетайпами, а не с экранными терминалами.

Первая заметка: телетайп — это устройство, напоминающее печатную машинку, но управляемое компьютером. В ранние годы развития компьютерных технологий мониторов ещё не существовало, и их роль выполняли телетайпы. Пользователи вводили команды на клавиатуре телетайпа, а результаты вычислений автоматически печатались на бумаге. Удобно, не так ли? Это сарказм :)
Ed — это так называемый линейный текстовый редактор. В нём редактирование текста происходило построчно, а не в привычном для нас сегодня формате, где весь текст доступен для визуального редактирования.
Редактирование одной строки за раз было вполне оправдано для телетайпов. Однако с появлением и ростом популярности видеодисплеев такой подход стал неудобным для большинства пользователей. Среди недовольных был и Джордж Кулурис из Университета Королевы Марии. Он считал команды редактора Ed слишком сложными и загадочными, неподходящими для обычных пользователей, или, как он выразился, «смертных».
На мое удивление, редактор Ed до сих пор доступен на MacOS и Ubuntu.
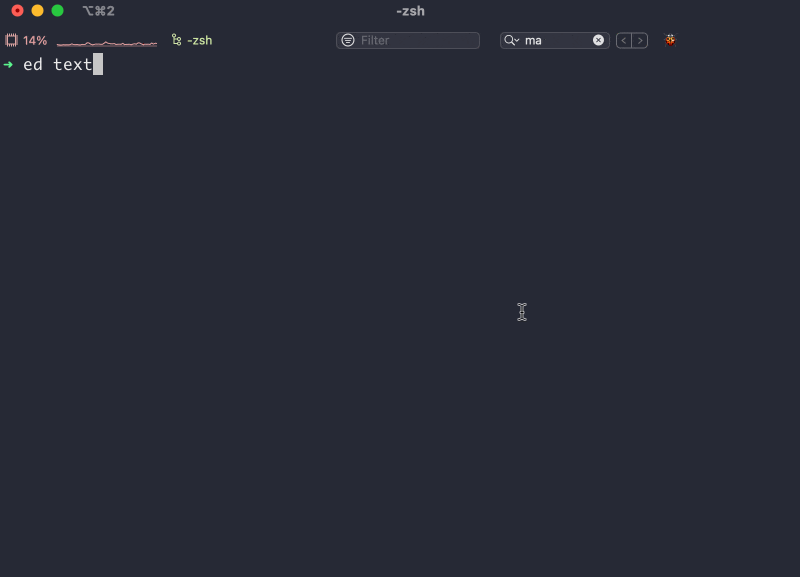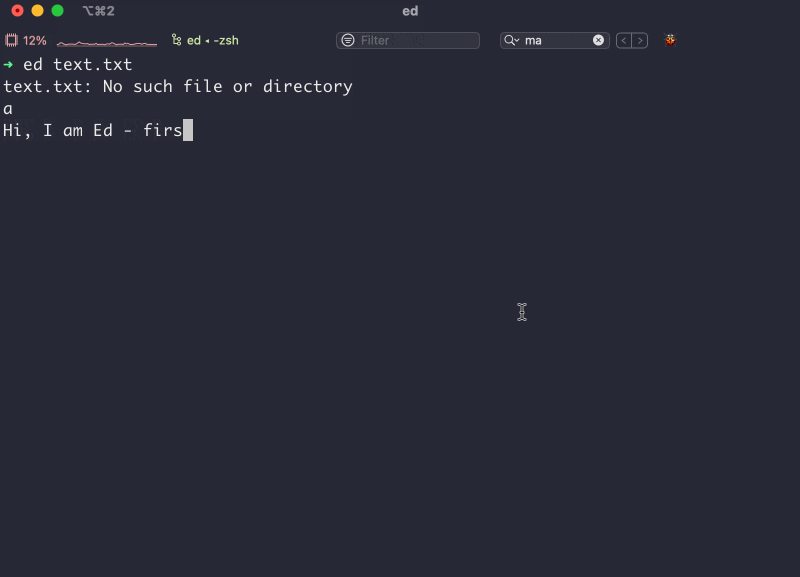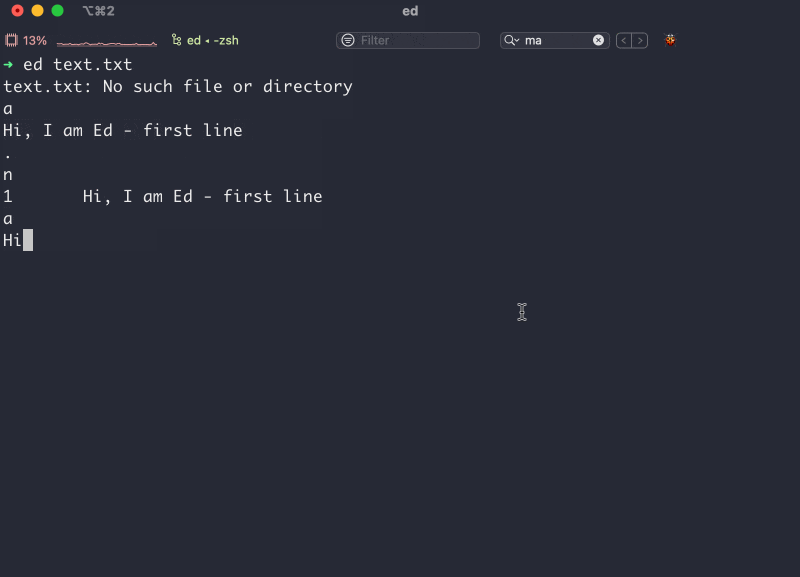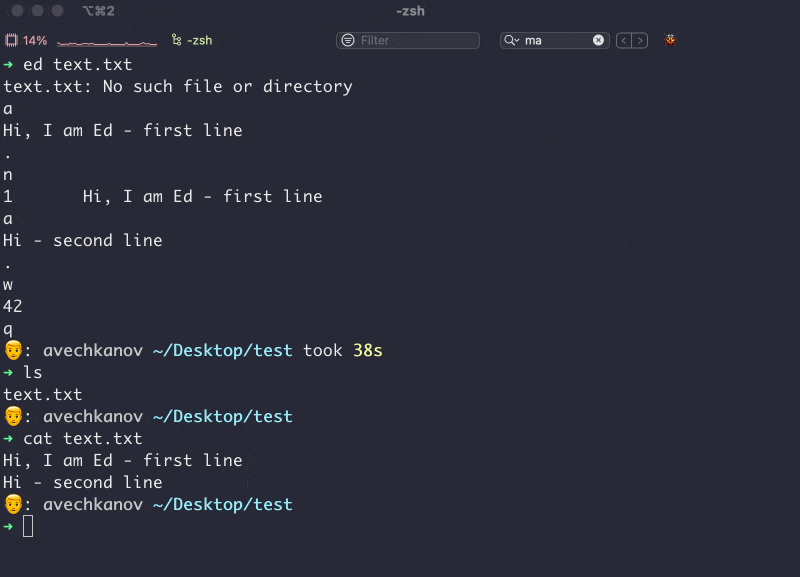
Для того, чтобы стало чуть понятнее, как это работает, опишу несколько команд:
a - append - добавление новой строки
. (точка) - завершить ввод строки
n - вывести все строки файла с нумерацией
w - write - сохранить файл
q - quit - выход из программы
У современного пользователя наверняка возникнет вопрос: зачем? Почему нужно редактировать текст построчно? В видео ниже автор подробно объясняет, почему так сложилось. Если же кратко, то задумайтесь: как вы могли бы переместить курсор на пишущей машинке? :)
Редактор Ed, созданный Кеном Томпсоном, был вдохновлён редактором под названием QED (Quick Editor, или “быстрый редактор”). QED также представлял собой линейный текстовый редактор, предназначенный для работы на телетайпах и разработанный для консоли SDS 940. Кен Томпсон переписал QED на языке программирования BCPL (Basic Combined Programming Language) для работы в операционной системе MULTICS, которая впоследствии стала предшественником UNIX.
Интересный факт: редактор Ed стал стандартным редактором строкового режима для операционной системы UNIX и сохраняет этот статус по сей день. Более того, он остаётся частью стандарта POSIX, обеспечивая совместимость с современными системами.
Em
После серии разочарований в использовании Ed, в феврале 1976 года Джордж Кулурис, будучи преподавателем в колледже Королевы Марии, решил усовершенствовать этот редактор. Взяв за основу оригинальный исходный код, написанный Кеном Томпсоном, он создал редактор em (Ed for Mortals — “Ed для простых смертных”).
Редактор em, созданный Кулурисом, был разработан специально для работы с дисплейными терминалами. Хотя он оставался построчным редактором, em стал одной из первых программ в UNIX, активно использовавших «режим необработанного терминала» (raw terminal mode). В этом режиме обработку всех нажатий клавиш брала на себя сама программа, а не драйвер терминального устройства.
Найти редактор em было сложнее. Но все же удалось найти исходники под современные ОС. Если решите попробовать собрать - вот репозиторий.
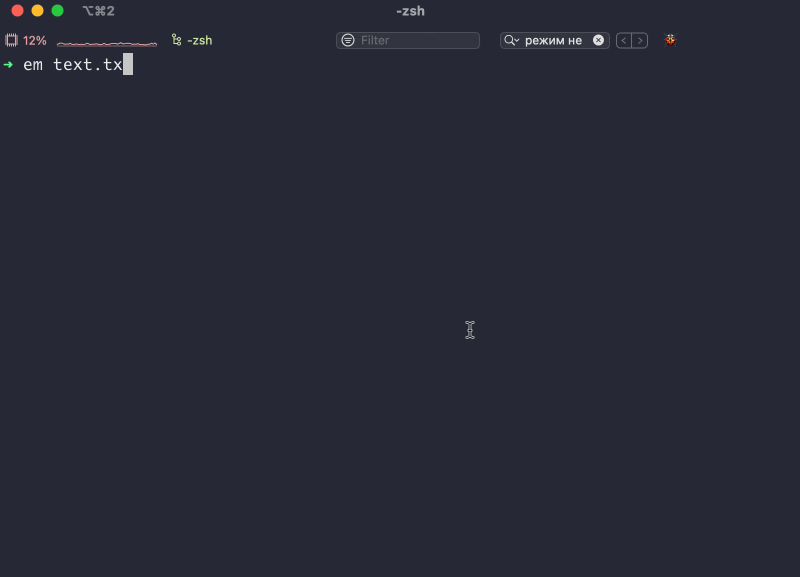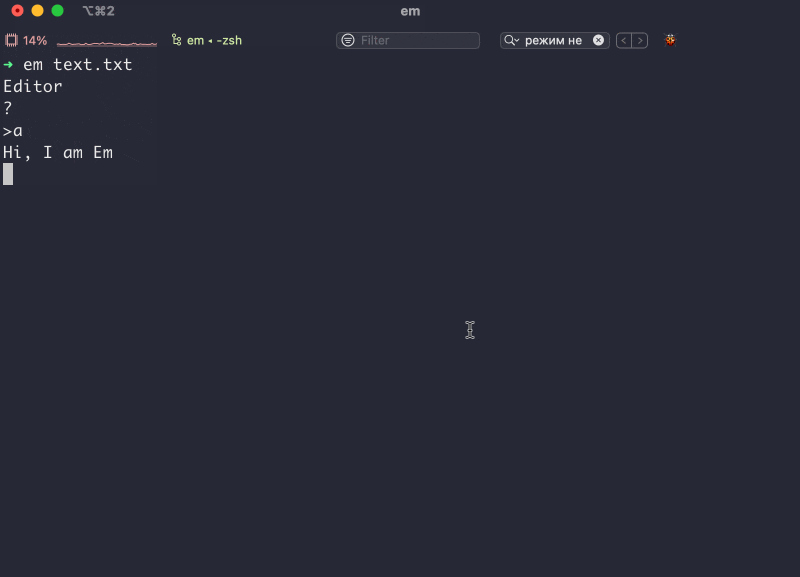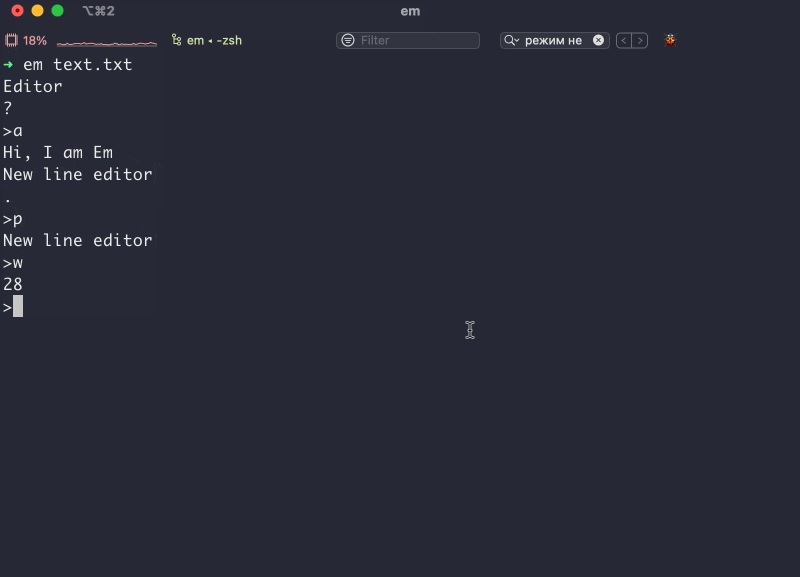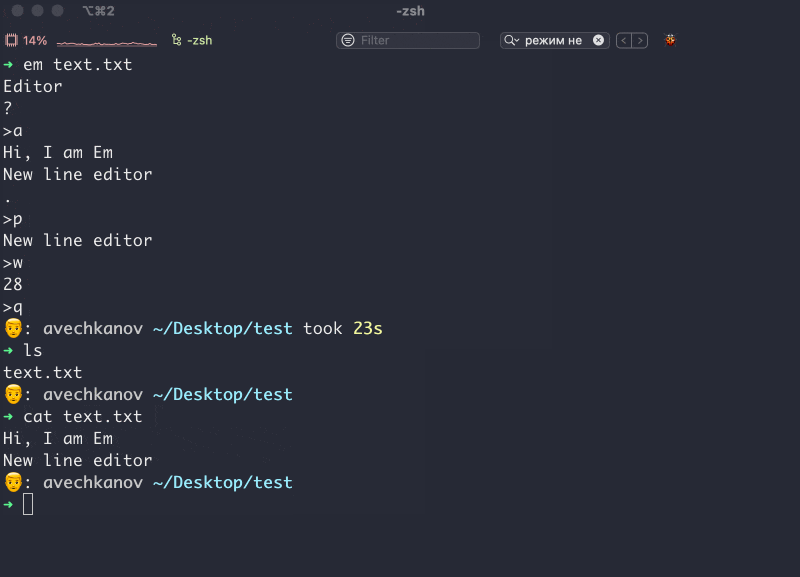
Однако Джордж Кулурис был далеко не единственным, кого разочаровал редактор Ed. На другой стороне Атлантики всё больше пользователей выражали недовольство работой с построчным редактором, созданным Кеном Томпсоном.
Vi
В 1976 году Кен Томпсон посетил Калифорнийский университет в Беркли, привезя с собой сломанный компилятор Паскаля для UNIX, который требовал доработки. Задачу по исправлению системы Паскаля Томпсона доверили студенту Биллу Джою. В процессе работы Джой всё чаще замечал, что редактор Ed ограничивает его возможности и замедляет процесс.

Летом 1976 года Джордж Кулурис посетил Калифорнийский университет в Беркли, привезя с собой DECtape с записанным редактором em. Он продемонстрировал свою разработку местным специалистам. Мнения разделились: некоторые посчитали, что такой обновлённый подход к текстовому редактору слишком ресурсоёмок, но другие, включая Билла Джоя, были впечатлены работой Кулуриса.
Стоит отметить, что компьютеры того времени были очень больши по размерам, но крайне слабы по производительности. К примеру, у вышеупомянутого SDS 940 было примерно от 72 КБ до 288 КБ оперативной памяти.

Вдохновившись редактором em Кулуриса, Билл Джой и Чак Хейли, оба аспиранты Калифорнийского университета в Беркли, создали новый редактор под названием en. Вскоре они расширили возможности en, разработав редактор ex. В октябре 1977 года Билл Джой добавил в ex полноэкранный визуальный режим, который получил название vi.
То есть Vi - это всего лишь "Визуальный" режим редактора Ex. Иронично правда? :)
Если вы хотите попробовать Ex самостоятельно, то для macOS можно установить при помощи пакетного менеджера homebrew. Ex - часть пакета ex-vi. Для установки запустите команду в терминале:
1brew install ex-vi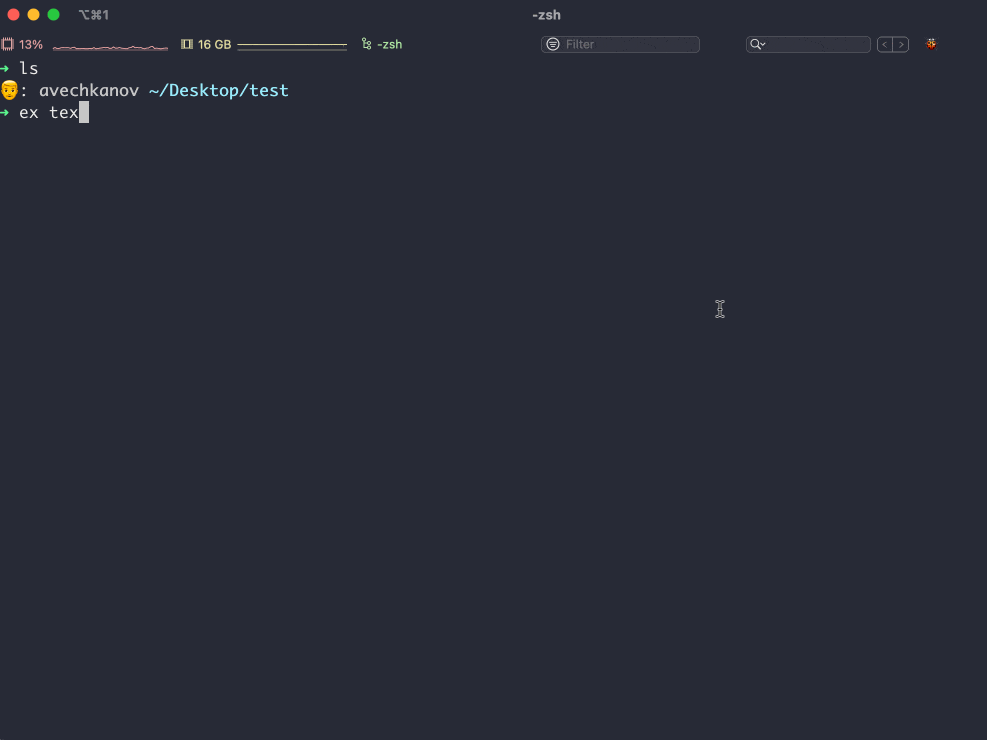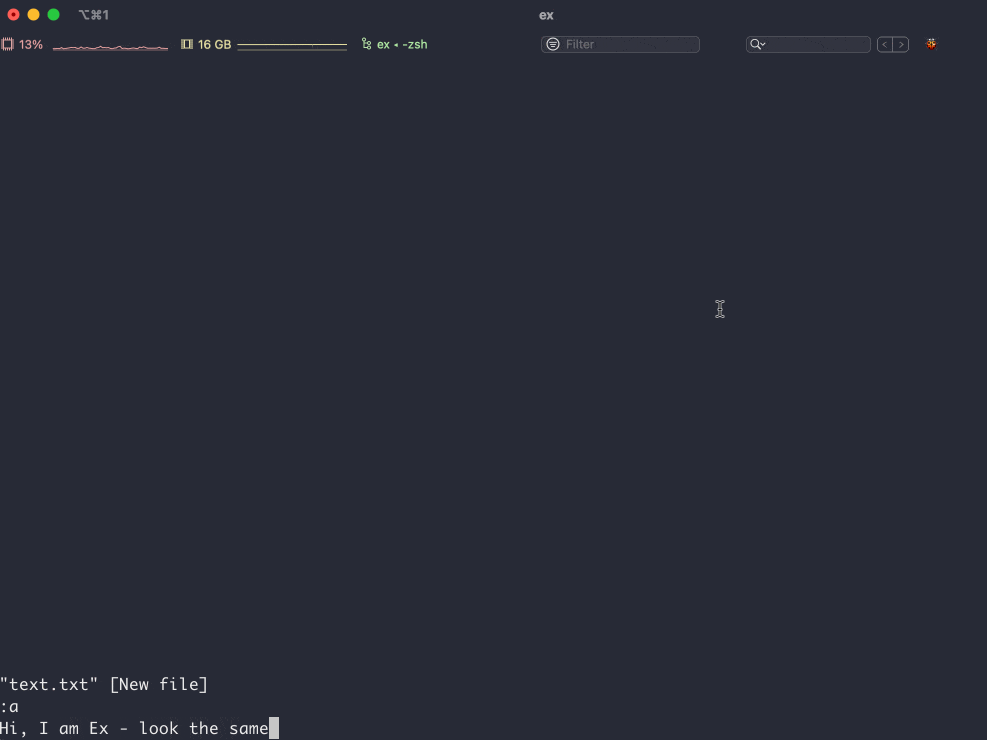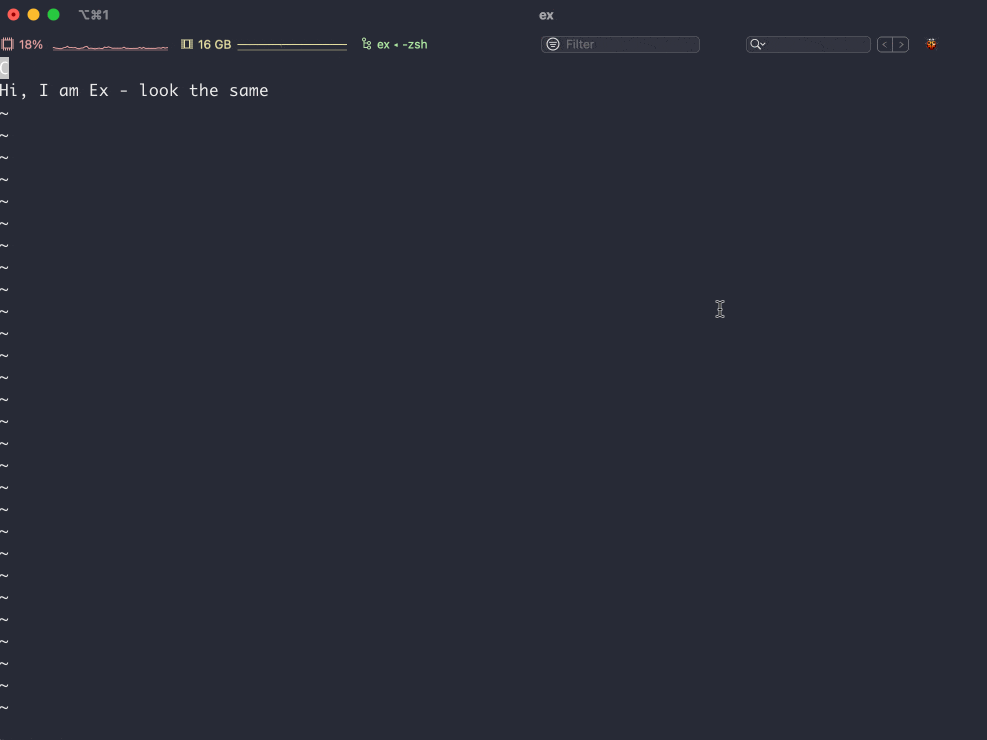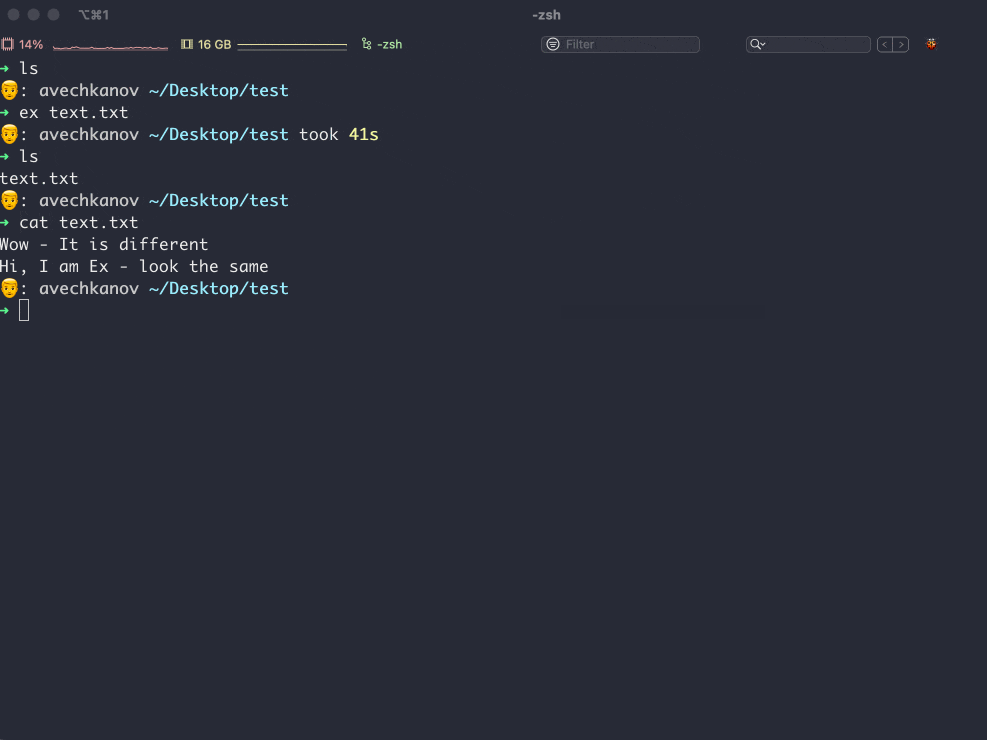
Vi и ex — это на самом деле одна и та же программа с общим кодом. Можно считать, что vi — это запуск ex с дополнительным параметром, который позволяет отображать и редактировать текст на экранном терминале. По сути, vi является визуальным режимом редактора ex.
Интересный факт: визуальный режим в vi также назывался open-режимом, что можно перевести как “режим открытого редактирования текста”.
Название vi произошло от сокращённой команды visual, используемой для входа в визуальный режим из редактора ex. Со временем, как многим из нас известно, vi стало не только обозначением визуального режима, но и именем исполняемого файла, который мы запускаем из оболочки UNIX.
Джой также упомянул, что многие функции vi были вдохновлены редактором Bravo. Bravo — бимодальный текстовый редактор, разработанный в Xerox PARC для Xerox Alto.

Если захотите попробовать редактор Bravo - есть виртуальная машина Xerox Alto в браузере.
Кстати, компания Xerox и её революционные разработки, опередившие своё время, заслуживают отдельной статьи. Но об этом мы поговорим как-нибудь в другой раз.
Также стоит отметить, что Билл Джой разработал vi на терминале ADM-3A. На этом терминале клавиша Escape находилась в крайнем левом углу клавиатуры, примерно там же, где на современных клавиатурах расположена клавиша Tab. Такое расположение делало работу с Escape более удобной и естественной для пользователей того времени.
Интересный факт: многие современные пользователи vi переназначают почти неиспользуемую клавишу Caps Lock для смены режимов редактора. Это делает работу с vi быстрее и удобнее, особенно учитывая частое использование клавиши Escape.

Помимо влияния терминала ADM-3A на сочетания клавиш vi, стоит упомянуть, что Билл Джой создавал свой редактор, работая через чрезвычайно медленный модем со скоростью всего 300 бод. Эта особенность оказала значительное влияние на подход к оптимизации работы редактора и его интерфейса.
Бод — это единица измерения скорости передачи данных в телекоммуникациях, обозначающая количество символов (сигнальных изменений) в секунду. Один бод не всегда равен одному биту, так как один символ может содержать несколько бит информации в зависимости от используемой модуляции. Но это все еще очень медленно.
Вот цитата Билла Джоя из интервью о его процессе написания ex и vi:
"It took a long time. It was really hard to do because you've got to remember that I was trying to make it usable over a 300 baud modem. That's also the reason you have all these funny commands. It just barely worked to use a screen editor over a modem. It was just barely fast enough. A 1200 baud modem was an upgrade. 1200 baud now is pretty slow. 9600 baud is faster than you can read. 1200 baud is way slower. So the editor was optimized so that you could edit and feel productive when it was painting slower than you could think. Now that computers are so much faster than you can think, nobody understands this anymore."
«Это заняло много времени. Это было действительно сложно сделать, потому что нужно помнить, что я пытался сделать его пригодным для использования через модем на скорости 300 бод. Именно поэтому там есть все эти странные команды. Использовать экранный редактор через такой модем едва удавалось. Скорости едва хватало. Модем на 1200 бод был уже обновлением. Сейчас 1200 бод — это очень медленно. 9600 бод — быстрее, чем вы успеваете читать. А 1200 бод — намного медленнее. Поэтому редактор был оптимизирован так, чтобы вы могли редактировать и чувствовать продуктивность, даже когда скорость отображения была медленнее, чем скорость ваших мыслей. Теперь, когда компьютеры работают намного быстрее, чем человек успевает думать, никто этого больше не понимает.».
Джой также сравнивает разработку vi и Emacs:
"People doing Emacs were sitting in labs at MIT with what were essentially fibre-channel links to the host, in contemporary terms. They were working on a PDP-10, which was a huge machine by comparison, with infinitely fast screens. So they could have funny commands with the screen shimmering and all that, and meanwhile, I'm sitting at home in sort of World War II surplus housing at Berkeley with a modem and a terminal that can just barely get the cursor off the bottom line... It was a world that is now extinct."
«Люди, работавшие над Emacs, сидели в лабораториях MIT с тем, что в современных терминах можно назвать высокоскоростными соединениями типа Fibre Channel к хосту. Они работали на PDP-10, которая по сравнению с моими условиями была огромной машиной с невероятно быстрыми экранами. Так что они могли позволить себе забавные команды с мерцанием экрана и всем таким прочим. А тем временем я сидел дома в чем-то вроде послевоенного жилья времён Второй мировой в Беркли с модемом и терминалом, который с трудом мог поднять курсор с нижней строки экрана… Это был мир, который теперь полностью исчез.»
Билл Джой также сыграл ключевую роль в создании первой версии BSD UNIX в 1978 году, разработанной в Калифорнийском университете в Беркли. Эта версия включала редактор ex, что значительно поспособствовало его популярности за пределами университета и укрепило позиции редактора в сообществе UNIX.
Большинство пользователей проводили все свое время в визуальном режиме ex, поэтому Билл Джой решил создать жесткую ссылку под названием «vi» и добавить ее во второй дистрибутив BSD в мае 1979 года.
Билл Джой утверждал, что значительная часть популярности vi была связана с его доступностью: редактор поставлялся вместе с BSD UNIX. В то время как другие редакторы, такие как Emacs, могли стоить сотни долларов, vi был бесплатным и доступным для всех пользователей BSD, что сделало его предпочтительным выбором.
Клоны Vi
На основе vi были разработаны многие редакторы-клоны. Идея заключалась в том, чтобы либо улучшить исходный редактор, добавив в него новые функции, либо перенести интерфейс vi на другие платформы (Atari ST, Amiga, MS-DOS, OS/2 и т. д.). Vim Брэма Муленаара начинался как один из таких портов.
Stevie
Stevie (редактор ST для энтузиастов VI) — клон vi, разработанный для Atari ST.
Тим Томпсон (Тим не родственник Кену Томпсону - просто так совпало) написал оригинальную версию Stevie и опубликовал ее исходный код как бесплатное программное обеспечение в группе новостей comp.sys.atari.st в июне 1987 года. Позже Stevie также был портирован на UNIX, OS/2 и Amiga.

А вот пример его работы:
Один важный момент заключается в том, что редактор Stevie был написан с нуля и не использовал исходный код vi. Код vi, в свою очередь, был основан на коде ed, разработанном компанией AT&T. Теоретически это означало, что vi могли использовать только те, кто обладал лицензией AT&T. Именно по этой причине многие клоны vi предпочли использовать исходный код Stevie в качестве основы, избегая лицензионных ограничений, связанных с оригинальным vi.
Elvis
Elvis — это текстовый редактор, который был создан как клон популярного редактора vi, входящего в состав UNIX. Elvis был разработан в 1990 году Стивом Киркендаллом (Steve Kirkendall) и стал одной из самых популярных альтернатив vi в то время, когда оригинальный vi был тесно связан с коммерческими версиями UNIX.
Создатель Elvis, Стив Киркендалл, задумался о создании собственного текстового редактора после того, как Stevie неожиданно завершил работу с ошибкой. Это привело к потере нескольких часов его работы и подорвало доверие Киркендалла к редактору, что в итоге подтолкнуло его к разработке альтернативы.
Stevie хранил буфер редактирования в оперативной памяти, что Стив Киркендалл считал непрактичным для работы в операционной системе MINIX. Одной из главных причин, побудивших его создать собственный клон vi, было желание хранить буфер редактирования не в памяти, а во внешнем файле. Благодаря этому подходу даже в случае сбоя редактора отредактированный текст можно было восстановить из этого файла, что делало новый редактор гораздо более надёжным.
Забавный факт: когда Стива Киркендалла спросили, почему он выбрал название Elvis, он признался, что частично сделал это ради того, чтобы люди задавали ему этот вопрос. Кроме того, названия клонов vi традиционно включают буквы «vi», и Elvis не стал исключением.
Elvis стал пионером многих идей, которые позже были внедрены в другие клоны редакторов. Он получил признание за свою компактность, богатый набор функций и стал первым клоном vi, который предоставил подсветку синтаксиса для различных типов файлов. Это сделало Elvis одним из самых популярных редакторов своего времени.
Создатель MINIX, Эндрю Таненбаум, предложил сообществу выбрать основной текстовый редактор для их операционной системы между Stevie и Elvis. Выбор пал на Elvis, и он остаётся текстовым редактором по умолчанию в MINIX по сей день.
Vim
И вот мы наконец добрались до Vim! Этот редактор, пожалуй, самый популярный клон vi за всю историю. Со временем он эволюционировал в мощную и универсальную программу с активным и постоянно растущим сообществом. Хотя сегодня называть Vim клоном vi кажется не совсем корректным из-за его обширных возможностей, исторически именно так и было — Vim начинался как клон оригинального vi.
Вдохновленный предыдущим портом Stevie для Commodore Amiga, Брэм Муленаар начал работать над Vim для Amiga в 1988 году. Первоначально Vim был разработан для Commodore Amiga.
Первый публичный выпуск Vim (v1.14) состоялся в 1991 году.
Как вы можете видеть на изображении выше, имя «Vim» было аббревиатурой от «Vi IMitation». В 1993 году название было изменено на «Vi iMproved».
Интересный факт: первая общедоступная копия Vim для Amiga была включена в диск Фреда Фиша №591. Фред Фиш — известный программист, внёсший вклад в разработку GNU GDB, а также создатель серии бесплатных дисков для компьютеров Amiga. Серия Fish Disks выпускалась с 1986 по 1994 год, распространяясь по всему миру. Эти диски часто появлялись в компьютерных магазинах и клубах энтузиастов Amiga, делая программное обеспечение более доступным для широкого круга пользователей.
Создание Vim на основе исходного кода Stevie, а не оригинального vi, позволило распространять редактор без привязки к лицензии AT&T. Vim выпускается под собственной лицензией Vim, которая включает уникальное условие: она побуждает пользователей делать пожертвования на благотворительность, в частности, на помощь детям в Уганде. Это делает Vim не только инструментом для работы, но и проектом с социальной миссией.
Факт: Брам Муленаар, создатель Vim, был активным защитником негосударственной организации, базирующейся в Кибаале, Уганда. Он основал её для поддержки детей, чьи родители умерли от СПИДа. В 1994 году Муленаар работал волонтёром в Детском центре Кибаале, занимаясь проектированием систем водоснабжения и канализации. В течение последующих 25 лет он неоднократно возвращался в Уганду, продолжая свою работу и помогая детям.
Интерфейс Vim, как и у vi, основан на текстовых командах, вводимых через терминал, без использования меню или значков. Хотя Vim также поддерживает графический пользовательский интерфейс (GUI), позволяющий работать с меню и панелями инструментов, самым популярным и традиционным остаётся текстовый интерфейс, работающий в командной строке UNIX. Именно этот режим ассоциируется с мощью и гибкостью Vim.
Если вы решите попробовать на vim с GUI на macOS, то есть MacVim.
Но, в действительности он мало чем отличается от терминального образца.
Vim включает режим совместимости с vi, но при его отключении предлагает множество улучшений, недоступных в оригинальном vi. Среди таких улучшений: поддержка Unicode, расширенные регулярные выражения, автодополнение, подсветка синтаксиса и множество других функций, напоминающих инструменты современных IDE. Эти возможности делают Vim мощным инструментом как для программирования, так и для редактирования текста.
Vim сегодня
В отличие от большинства других клонов vi, Vim продолжает активно развиваться и поддерживаться большим сообществом пользователей и разработчиков. Новые функции регулярно разрабатываются и добавляются, что делает редактор всё более мощным и актуальным. Эта активная эволюция способствует сохранению популярности Vim среди как новичков, так и опытных пользователей.
Разумеется, возможности Vim можно значительно расширить с помощью множества сторонних плагинов. В сочетании с мощным встроенным языком сценариев VimScript редактор превращается в невероятно продуктивный инструмент для программирования и работы с текстом. Такая гибкость позволяет настроить Vim под практически любые задачи, удовлетворяя потребности самых требовательных пользователей.
Некоторые важные вехи с первых дней разработки Vim:
1988: (Vim 1.0) Разработка Vi IMitation на Amiga.
1991: (Vim 1.14) Первый публичный выпуск на диске Фреда Фиша № 591.
1993: (Vim 1.22) Портирован на UNIX и переименован в Vi Improved.
1994: (Vim 3.0) Несколько окон.
1996: (Vim 4.0) Графический интерфейс пользователя
1998: (Vim 5.0) Подсветка синтаксиса
2001: (Vim 6.0) Складной и многоязычный
2006: (Vim 7.0) Проверка орфографии на лету и поддержка вкладок.
Vim-у сейчас больше 30 лет! В таблице ниже показаны некоторые вехи и улучшения Vim за последние 20 лет. Визуализация была создана @mpereira и включает в себя обзор истории разработки Vim, как видно из его репозитория git, созданного в 2004 году.
Текстовый редактор, созданный Брамом Муленааром, пользуется большой популярностью среди разработчиков программного обеспечения. В различных опросах он неоднократно упоминался как один из самых широко используемых текстовых редакторов или даже IDE. Более того, Vim до сих пор остаётся редактором по умолчанию во многих современных дистрибутивах Linux, подтверждая свою востребованность и универсальность.
Брам Муленаар продолжал работать над развитием Vim вплоть до нескольких недель до своей кончины в 2023 году. Современные компьютеры, в их привычном нам виде, во многом обязаны таким выдающимся людям, как Брам. Немногие инструменты с открытым исходным кодом могут сравниться с Vim по своему влиянию и легендарному статусу, который он заслуженно занимает в мире программирования.
P.S. Многие задаются извечным вопросом: «Как выйти из Vim?» Лично мне пришлось помучиться не только с этим, но и с тем, как выходить из Ed, Em, Ex, Bravo и Vi. Со мной все в порядке ;)
Спасибо за внимание!
iTerm — как дублировать вкладку в той же директории
Современные среды разработки часто требуют использования нескольких вкладок терминала для работы над проектом. Например, вам может понадобиться вкладка для компиляции, чтобы собрать финальный JavaScript-файл для браузера. Помимо компиляции фронтенда, может потребоваться запуск сервера для обработки входящих запросов, будь то сервер фронтенда или бэкенда.

При работе с iTerm вы можете настроить сочетание клавиш для дублирования существующей вкладки терминала, чтобы открыть новую сессию в той же папке. В этом руководстве я подробно расскажу, как настроить этот удобный ярлык!
Открытие новой вкладки в iTerm в той же папке
По умолчанию сочетание CMD + T в iTerm открывает новую вкладку, но она начинается с домашней директории (обычно ~/). Эта команда не отображается в разделе Keys, так как она встроена как стандартное поведение iTerm.
Но если добавить эту комбинацию клавиш вручную, и назначить событие на открытие новой вкладки, то отрываться она начинает в той же директории, что и первая вкладка!
1. Откройте настройки iTerm, нажав CMD + ,.
2. Перейдите в раздел Keys.
3. Нажмите на знак + в левом нижнем углу.
4. Выберите сочетание клавиш (например, CMD + T).
5. В поле действия (Action) выберите Duplicate Tab.
6. Нажмите OK, чтобы сохранить новое сочетание клавиш.
Вот и все! Теперь вы можете дублировать любые вкладки iTerm, одновременно нажав CMD + t на клавиатуре, при этом они всегда будут открываться в тех же директориях! Удачи!
Webpack Module Federation в NextJS
Мне тут понадобилось подключить в приложение NextJS и я столкнулся с большими проблемами. В этой статье я постараюсь коротко и емко на примере показать как подключить Webpack Module Federation (Далее MF) компоненты на ваше приложение NextJS (на клиентской стороне).

Проблема
До недавнего времени, официальным решением внедрения MF модулей в NextJS была библиотека @module-federation/nextjs-mf.
Плагин @module-federation/nextjs-mf — это специальный модуль, который упрощает интеграцию Webpack Module Federation в приложения на Next.js. Он создан командой, которая разрабатывает сам Module Federation, и решает множество проблем, связанных с SSR, shared-зависимостями и конфигурацией Next.js.
Next.js по умолчанию не поддерживает Module Federation “из коробки”, особенно в части SSR (Server Side Rendering). Этот плагин:
- Упрощает настройку Webpack Module Federation в Next.js
- Добавляет поддержку SSR и динамической загрузки remote компонентов
- Обеспечивает корректную работу shared зависимостей (например, React)
- Позволяет использовать dynamic() из next/dynamic с federation-компонентами
- Работает как на клиенте, так и на сервере
- Позволяет делать federated middleware (например, отданные с getServerSideProps)
- Позволяет делать hot-reload remote модулей в dev-среде
Но вот незадача, она deprecated.
Команда разрабатывающая решение MF более не развивает плагин и вскоре прекратит поддержку.
Стоит отметить что в последнем сообщении Zack Jackson (ментейнер MF) отмечает:
- Поддержка Module Federation в Next.js — вероятна (~80%), но не гарантирована.
- Вектор развития положительный, технические и организационные барьеры уменьшаются.
- Плагин nextjs-mf получит частичное восстановление и поддержку App Router в ближайшем будущем.
Надежда умирает последней...
Решение
Но не стоит отчаиваться. NextJS собирается Webpack, а значит под капотом все те модули, а значит можно просто использовать плагин ModuleFederationPlugin из самого webpack.
Далее в статье мы создадим Remote приложение (без NextJS) для раздачи виджетов, и Host на основе NextJS и подключим к нему модули WMF из Remote
Я подготовил два репозитория:
1) Host (приложение NextJS) в который будем подключать приложение (https://github.com/Hydrock/wmf-nextjs)
2) Remote - отсюда будем отдавать компонент (https://github.com/Hydrock/wmf-remote)
Скачайте оба репозитория в удобную для вас директорию и запустите (Смотрите инструкцию).
В NextJS приложении на http://localhost:3000 должен подружаться удаленный компонент из Remote приложения.
Теперь посмотрим как это сделано.
Разбор
В приложении wmf-nextjs откройте конфиг next.config.ts
1const { container } = require('webpack');
2const { ModuleFederationPlugin } = container;
3import type { NextConfig } from "next";
4
5const nextConfig: NextConfig = {
6 webpack(config, { isServer }) {
7 if (!isServer) {
8 console.log('✅ Webpack client config is used');
9
10 config.plugins.push(
11 new ModuleFederationPlugin({})
12 );
13 }
14
15 return config;
16 },
17};
18
19module.exports = nextConfig;
20Тут мы просто подключили плагин ModuleFederationPlugin из Webpack. Не указывали remote и exposes параметры - все это будет делаться динамически в компоненте. Мы же хотим в будущем загружать модули из разных источников.
Файл components/RemoteWrapper.tsx - обертка над загружаемым компонентом. Обратите внимание на 'use client'- мы рендерим/загружаем модуль только на клиенте/в браузере.
Файл RemoteWidget.tsx - сам загрузчик удаленного модуля. В идеале, конечно, все это нужно оформить в отдельную библиотеку загрузчик с обработкой ошибок, но я специально этого не делал для простоты примера.
1// components/RemoteWidget.tsx
2'use client';
3
4import React, { useEffect, useState } from 'react';
5
6function injectScript(url: string, scope: string): Promise<void> {
7 return new Promise((resolve, reject) => {
8 // eslint-disable-next-line
9 // @ts-ignore
10 if (window[scope]) return resolve(); // уже есть
11
12 const existingScript = document.querySelector(`script[src="${url}"]`);
13 if (existingScript) return resolve(); // уже загружен
14
15 const script = document.createElement('script');
16 script.src = url;
17 script.type = 'text/javascript';
18 script.async = true;
19
20 script.onload = () => {
21 const checkInterval = setInterval(() => {
22 // eslint-disable-next-line
23 // @ts-ignore
24 if (window[scope]) {
25 clearInterval(checkInterval);
26 resolve();
27 }
28 }, 20);
29
30 // если через 3 сек не появился контейнер — ошибка
31 setTimeout(() => {
32 clearInterval(checkInterval);
33 reject(new Error(`🛑 ${scope} не появился в window после загрузки`));
34 }, 3000);
35 };
36
37 script.onerror = () => reject(new Error(`❌ Ошибка загрузки ${url}`));
38 document.head.appendChild(script);
39 });
40}
41
42const RemoteWidget = () => {
43 const [Comp, setComp] = useState<React.ComponentType | null>(null);
44
45 // INFO: при первом вызове useEffect container равен undefined
46 // но при втором он успевает инициализироваться
47 // но вот что заставляет запустить useEffect второй раз - не знаю
48 useEffect(() => {
49 const load = async () => {
50 const remoteUrl = 'http://localhost:8082/remoteEntry.js';
51 const scope = 'remoteApp';
52 const module = './RemoteComponent';
53
54 await injectScript(remoteUrl, scope);
55
56 // @ts-ignore — Webpack runtime
57 await __webpack_init_sharing__('default');
58
59 // @ts-ignore
60 const container = window[scope];
61 if (!container) throw new Error(`Remote container ${scope} не найден в window`);
62
63 // 🔧 если нет shared, передай пустой объект
64 // eslint-disable-next-line
65 // @ts-ignore
66 await container.init(typeof __webpack_share_scopes__ !== 'undefined'
67 // eslint-disable-next-line
68 // @ts-ignore
69 ? __webpack_share_scopes__.default
70 : {}
71 );
72
73 const factory = await container.get(module);
74 const Module = factory();
75
76 setComp(() => Module.default || Module);
77 };
78
79 load().catch(console.error);
80 }, []);
81
82 if (!Comp) return <div>Загрузка виджета...</div>;
83 return <Comp />;
84};
85
86export default RemoteWidget;В этом загрузчике есть баг, почему то вставка скрипта remoteEntry.js из удаленного модуля, и последующая инициализация scope происходит позже, чем webpack попытается его использовать - поэтому в консоль выподает ошибка. Но, при повторном рендере компонента все работает хорошо. Я надеюсь это починить в коде и исправить статью, до того как вы это прочитаете. В любом случае, вариант рабочий.
В коде есть функция injectScript. Его задача, добавить тег script на страницу с remoteEntry.js файлом из удаленного приложения. Когда этот файл загружается, он "сообщает" webpack-у какие удаленные модули есть в наличии и как их загрузить.
Когда скрипт загружен, срабатывает событие script.onload - запускается интервал и в нем проверяется, что scope инициализирован на объекте window (window[scope]). Все таки скрипту, нужно некоторое время для инициализации. После этого созданный выше промис резолвится.
В компоненте RemoteWidget мы ждем когда scope будет точно инициализирован - await injectScript(remoteUrl, scope);
Далее четь разберемся подробнее.
Функция __webpack_init_sharing__ — это внутренняя часть Webpack Module Federation Runtime, и она играет ключевую роль в том, как работает механизм shared (разделяемых) зависимостей между host и remote.
Когда вы вызываете await __webpack_init_sharing__('default'); вы инициализируете share scope с именем 'default', где Webpack:
- создаёт или подключается к глобальному контейнеру зависимостей (обычно __webpack_share_scopes__)
- определяет, какие модули доступны как shared
- обеспечивает, чтобы singleton модули (например, react) были реально одинаковыми
- запускает механизм сравнения версий, если указаны requiredVersion и strictVersion
Технически…
В примере мы шарим (remote приложение):
1shared: {
2 react: {
3 eager: true,
4 singleton: true,
5 },
6}__webpack_init_sharing__('default') создаёт глобальный скоуп (если его ещё нет)
туда помещается react как singleton
при загрузке remote, его container.init() синхронизируется с этим скоупом
Это ключевой механизм, который позволяет host и remote использовать одну и ту же копию React, и избежать ошибок типа:Invalid hook calluseContext(null)Cannot read properties of undefined (reading 'useLayoutEffect')
Далее, в нашем коде:
1const container = window[scope];
2
3await container.init(typeof __webpack_share_scopes__ !== 'undefined'
4 ? __webpack_share_scopes__.default
5 : {}
6);получаем remote-контейнер, зарегистрированный Webpack-ом как self[scope] (например, remoteApp, как у нас в примере)
он должен содержать методы init() и get()
вызываем init, чтобы контейнер подключился к глобальному набору shared-зависимостей (это обязательно, если ты используешь shared)
если ты не вызовешь init(), и в remote объявлены shared, произойдёт ошибка
container.init(...) обязан быть вызван перед get(), иначе remote не сможет синхронизировать зависимости.
1const factory = await container.get(module);
2const Module = factory();container.get('./RemoteComponent') - это асинхронный вызов, который:
находит нужный модуль внутри remoteEntry.js
загружает его chunk (если нужно)
возвращает фабрику (factory), то есть функцию, которая создаёт модуль
Важно: модуль не возвращается напрямую, а через factory() — это особенность Webpack runtime
factory() возвращает экспортированное содержимое модуля
это либо объект Module, содержащий default экспорт, либо просто сам компонент
Ну а далее у нас установка модуля/компонента в стейт и последующее его использование.
1setComp(() => Module.default || Module);Вообщем все сложно... Но мне хотелось немного разъяснить, что тут происходит.
Заключение
Хоть официальная библиотека поддержки MF в NextJS теперь deprecated - использование MF в NextJS все же возможно. Да, только на клиентской стороне, да, SSR придется реализовывать/придумывать самому, но - это реально.
Если вы заходите улучшить пример - создайте Issue в одном из репозиториев или можете сразу делать PR.
Спасибо за внимание!